Гиперпараметры — это переменные, которые управляют различными аспектами обучения. Вот три наиболее распространённых гиперпараметра:
В отличие от этого, параметры — это переменные, такие как веса и смещение, которые являются частью самой модели. Другими словами, гиперпараметры — это значения, которыми вы управляете; параметры — это значения, которые модель вычисляет во время обучения.
Скорость обучения
Скорость обучения — это число с плавающей запятой, которое вы задаёте и которое влияет на скорость сходимости модели. Если скорость обучения слишком низкая, сходимость модели может занять много времени. Однако, если скорость обучения слишком высокая, модель никогда не сходится, а вместо этого колеблется вокруг весов и смещения, минимизирующих потери. Цель — выбрать скорость обучения не слишком высокую и не слишком низкую, чтобы модель быстро сходилась.
Скорость обучения определяет величину изменений весов и смещения на каждом этапе процесса градиентного спуска. Модель умножает градиент на скорость обучения, чтобы определить параметры модели (значения веса и смещения) для следующей итерации. На третьем этапе градиентного спуска «небольшое» смещение в направлении отрицательного наклона определяется скоростью обучения.
Разница между параметрами старой и новой модели пропорциональна наклону функции потерь. Например, если наклон большой, модель делает большой шаг. Если маленький, модель делает малый шаг. Например, если величина градиента равна 2,5, а скорость обучения равна 0,01, то модель изменит параметр на 0,025.
Идеальная скорость обучения позволяет модели сходиться за разумное количество итераций. На рисунке 20 кривая потерь показывает, что модель значительно улучшается в течение первых 20 итераций, прежде чем начинает сходиться:
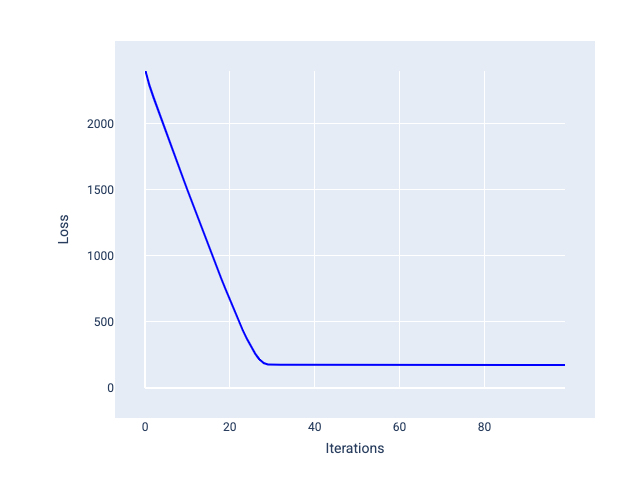
Рисунок 20. График потерь, показывающий модель, обученную с быстро сходящейся скоростью обучения.
Напротив, слишком низкая скорость обучения может потребовать слишком много итераций для достижения сходимости. На рисунке 21 кривая потерь показывает, что модель демонстрирует лишь незначительные улучшения после каждой итерации:
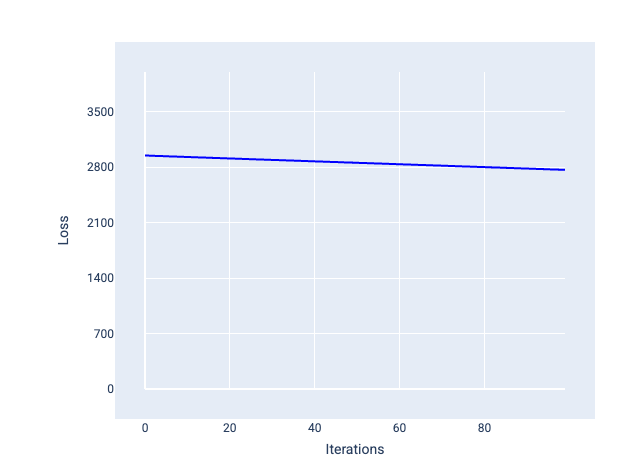
Рисунок 21. График потерь, показывающий модель, обученную с небольшой скоростью обучения.
Слишком большая скорость обучения никогда не сходится, поскольку каждая итерация приводит к тому, что потери либо колеблются, либо постоянно увеличиваются. На рисунке 22 кривая потерь показывает, что модель сначала уменьшает, а затем увеличивает потери после каждой итерации, а на рисунке 23 потери увеличиваются на последующих итерациях:
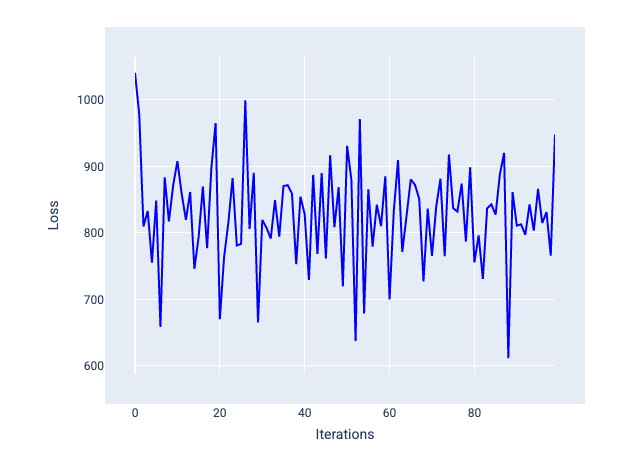
Рисунок 22. График потерь, показывающий модель, обученную со слишком большой скоростью обучения, где кривая потерь сильно колеблется, поднимаясь и опускаясь по мере увеличения числа итераций.
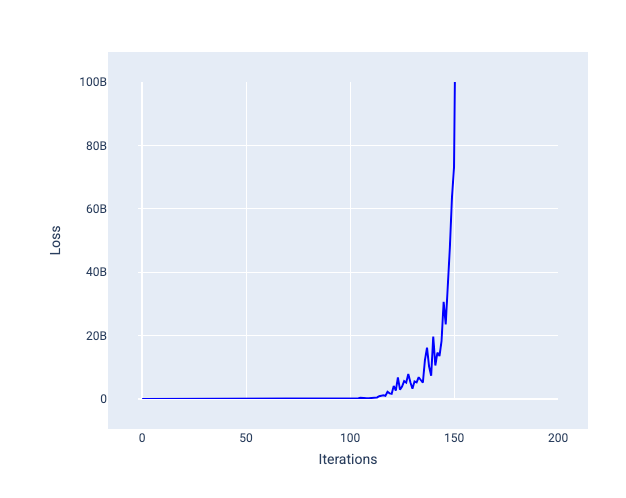
Рисунок 23. График потерь, показывающий модель, обученную со слишком большой скоростью обучения, где кривая потерь резко возрастает на последующих итерациях.
Упражнение: проверьте свое понимание
Размер партии
Размер пакета — это гиперпараметр, который определяет количество примеров, обрабатываемых моделью перед обновлением весов и смещения. Можно подумать, что модель должна вычислять потери для каждого примера в наборе данных перед обновлением весов и смещения. Однако, если набор данных содержит сотни тысяч или даже миллионы примеров, использование полного пакета нецелесообразно.
Два распространенных метода получения правильного градиента в среднем без необходимости просматривать каждый пример в наборе данных перед обновлением весов и смещения — это стохастический градиентный спуск и мини-пакетный стохастический градиентный спуск :
Стохастический градиентный спуск (SGD) : стохастический градиентный спуск использует только один пример (размер партии – один) на итерацию. При достаточном количестве итераций SGD работает, но создаёт сильный шум. «Шум» относится к вариациям во время обучения, которые приводят к увеличению потерь, а не к их уменьшению в течение итерации. Термин «стохастический» означает, что один пример, входящий в каждую партию, выбирается случайным образом.
Обратите внимание на следующее изображение, как потери слегка колеблются, когда модель обновляет свои веса и смещение с использованием SGD, что может привести к появлению шума на графике потерь:
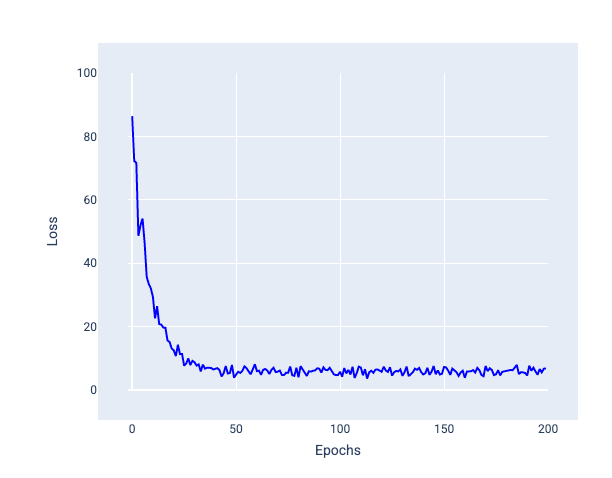
Рисунок 24. Модель, обученная с помощью стохастического градиентного спуска (SGD), демонстрирует шум на кривой потерь.
Обратите внимание, что использование стохастического градиентного спуска может привести к появлению шума на всей кривой потерь, а не только вблизи конвергенции.
Мини-пакетный стохастический градиентный спуск (мини-пакетный SGD) : мини-пакетный стохастический градиентный спуск представляет собой компромисс между полным пакетом и SGD. Для $ N $ количества точек данных размер пакета может быть любым числом больше 1 и меньше $ N $. Модель случайным образом выбирает примеры, включаемые в каждый пакет, усредняет их градиенты, а затем обновляет веса и смещение один раз за итерацию.
Определение количества примеров для каждого пакета зависит от набора данных и доступных вычислительных ресурсов. В целом, пакеты небольшого размера ведут себя как SGD, а пакеты большего размера — как полнопакетный градиентный спуск.
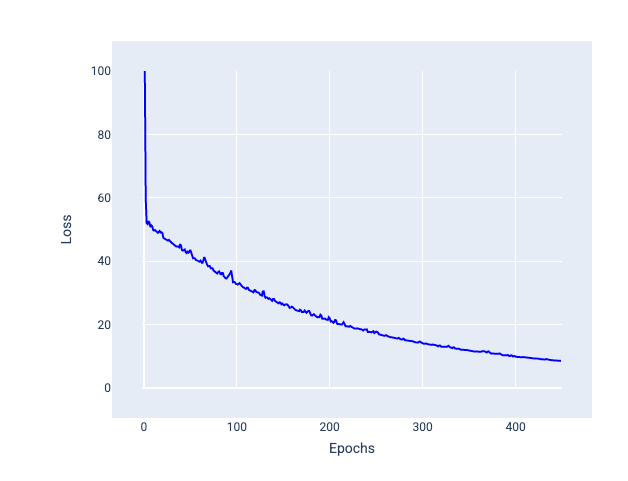
Рисунок 25. Модель, обученная с помощью мини-пакетного SGD.
При обучении модели вы можете подумать, что шум — это нежелательная характеристика, которую следует устранить. Однако определённое количество шума может быть полезным. В последующих модулях вы узнаете, как шум может помочь модели лучше обобщать данные и находить оптимальные веса и смещение в нейронной сети .
Эпохи
В процессе обучения эпоха означает, что модель обработала каждый пример в обучающем наборе один раз . Например, при наличии обучающего набора из 1000 примеров и мини-пакета из 100 примеров модели потребуется 10 итераций для завершения одной эпохи.
Обучение обычно требует много эпох. То есть системе приходится обрабатывать каждый пример в обучающем наборе несколько раз.
Количество эпох — это гиперпараметр, который вы задаёте перед началом обучения модели. Во многих случаях вам придётся экспериментировать с тем, сколько эпох потребуется модели для сходимости. Как правило, чем больше эпох, тем лучше модель, но и обучение занимает больше времени.
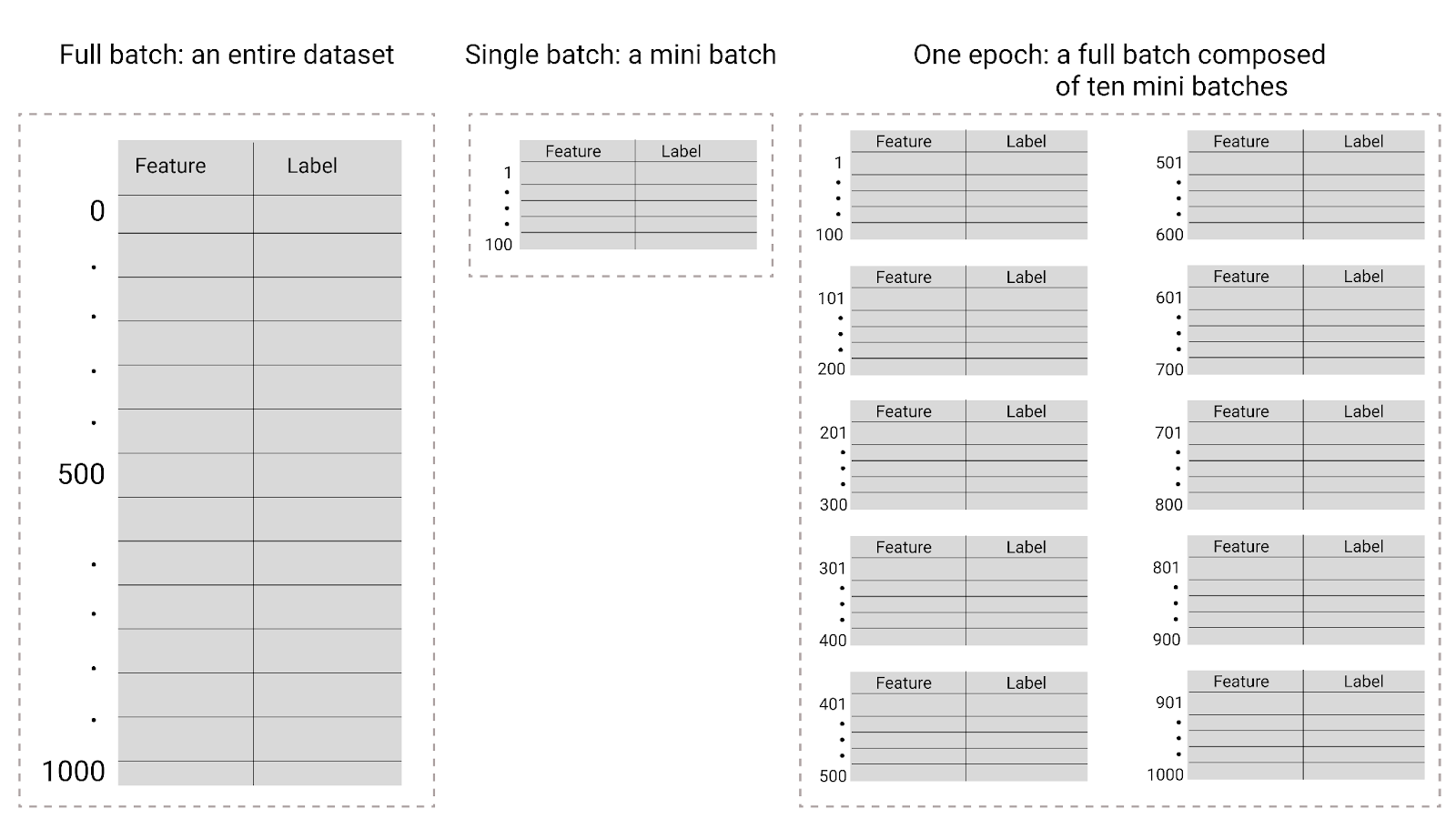
Рисунок 26. Полная партия и мини-партия.
В следующей таблице описывается, как размер пакета и эпохи соотносятся с количеством обновлений параметров модели.
| Тип партии | Когда происходят обновления весов и смещений |
|---|---|
| Полная партия | После того, как модель проанализирует все примеры в наборе данных (например, если набор данных содержит 1000 примеров, а модель обучается в течение 20 эпох), она обновляет веса и смещение 20 раз, по одному разу за эпоху. |
| Стохастический градиентный спуск | После того, как модель проанализирует один пример из набора данных (например, если набор данных содержит 1000 примеров и обучается в течение 20 эпох), модель обновит веса и смещение 20 000 раз. |
| Мини-пакетный стохастический градиентный спуск | После того, как модель проанализирует примеры в каждом пакете (например, если набор данных содержит 1000 примеров, а размер пакета равен 100, и модель обучается в течение 20 эпох, она обновляет веса и смещение 200 раз). |