فراپارامترها متغیرهایی هستند که جنبه های مختلف آموزش را کنترل می کنند. سه فراپارامتر رایج عبارتند از:
در مقابل، پارامترها متغیرهایی هستند، مانند وزن و سوگیری، که بخشی از خود مدل هستند. به عبارت دیگر، هایپرپارامترها مقادیری هستند که شما کنترل می کنید. پارامترها مقادیری هستند که مدل در طول آموزش محاسبه می کند.
میزان یادگیری
نرخ یادگیری یک عدد ممیز شناور است که شما تعیین میکنید که بر سرعت همگرایی مدل تأثیر میگذارد. اگر نرخ یادگیری خیلی کم باشد، همگرا شدن مدل ممکن است زمان زیادی طول بکشد. با این حال، اگر نرخ یادگیری بیش از حد بالا باشد، مدل هرگز همگرا نمیشود، بلکه در اطراف وزنها و سوگیریهایی که ضرر را به حداقل میرسانند، میچرخد. هدف این است که نرخ یادگیری را انتخاب کنید که نه خیلی زیاد و نه خیلی کم باشد تا مدل به سرعت همگرا شود.
نرخ یادگیری، میزان تغییراتی را که باید در وزن ها و سوگیری ها در طول هر مرحله از فرآیند نزول گرادیان ایجاد شود، تعیین می کند. مدل گرادیان را در نرخ یادگیری ضرب می کند تا پارامترهای مدل (وزن و مقادیر بایاس) را برای تکرار بعدی تعیین کند. در مرحله سوم شیب نزول ، "مقدار کوچک" برای حرکت در جهت شیب منفی به نرخ یادگیری اشاره دارد.
تفاوت بین پارامترهای مدل قدیمی و پارامترهای مدل جدید متناسب با شیب تابع ضرر است. به عنوان مثال، اگر شیب زیاد باشد، مدل یک گام بزرگ برمی دارد. اگر کوچک باشد، قدم کوچکی برمی دارد. به عنوان مثال، اگر قدر گرادیان 2.5 و نرخ یادگیری 0.01 باشد، مدل پارامتر را 0.025 تغییر می دهد.
نرخ یادگیری ایده آل به مدل کمک می کند تا در تعداد معقولی از تکرارها همگرا شود. در شکل 20، منحنی زیان نشان می دهد که مدل به طور قابل توجهی در طول 20 تکرار اول قبل از شروع به همگرایی بهبود می یابد:
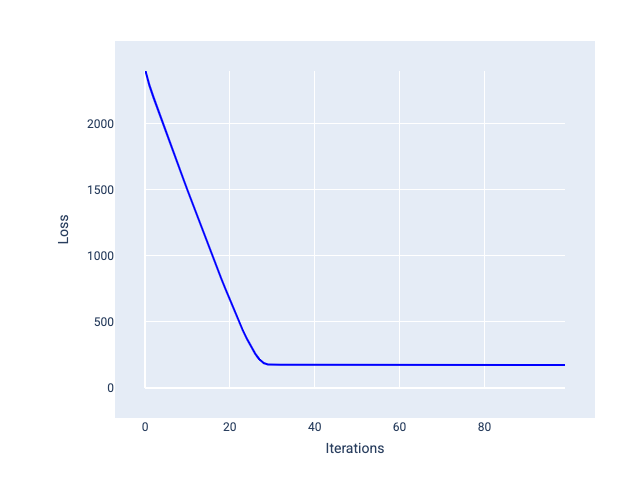
شکل 20 . نمودار ضرر نشان دهنده مدلی آموزش دیده با نرخ یادگیری است که به سرعت همگرا می شود.
در مقابل، نرخ یادگیری بسیار کوچک میتواند تکرارهای زیادی طول بکشد تا همگرا شوند. در شکل 21، منحنی ضرر مدل را نشان میدهد که پس از هر تکرار، فقط بهبودهای جزئی ایجاد میکند:
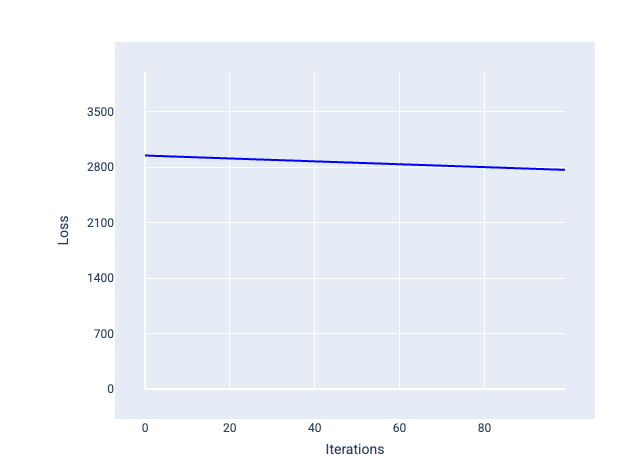
شکل 21 . نمودار زیان نشان دهنده یک مدل آموزش دیده با نرخ یادگیری اندک.
نرخ یادگیری خیلی زیاد هرگز همگرا نمی شود، زیرا هر تکرار یا باعث جهش ضرر یا افزایش مداوم آن می شود. در شکل 22، منحنی ضرر مدل را در حال کاهش و سپس افزایش تلفات پس از هر تکرار نشان می دهد، و در شکل 23 تلفات در تکرارهای بعدی افزایش می یابد:
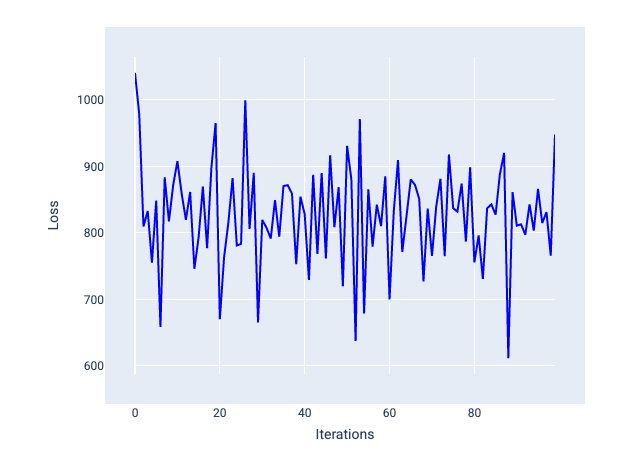
شکل 22 . نمودار زیان مدلی را نشان می دهد که با نرخ یادگیری بسیار بزرگ آموزش دیده است، که در آن منحنی ضرر به شدت در نوسان است و با افزایش تکرارها بالا و پایین می شود.
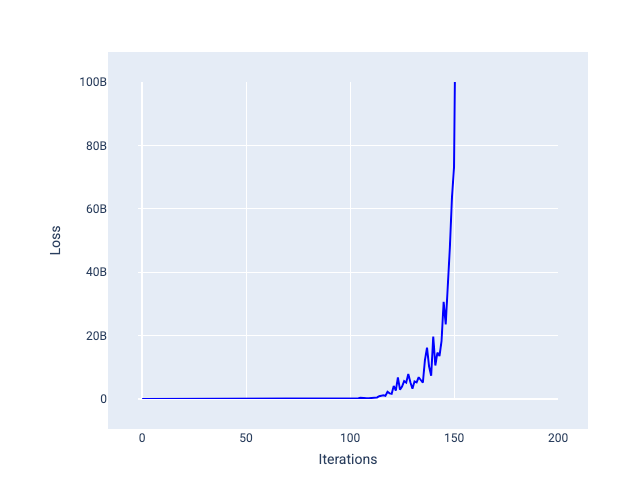
شکل 23 . نمودار زیان مدلی را نشان می دهد که با نرخ یادگیری بسیار بزرگ آموزش دیده است، که در آن منحنی ضرر در تکرارهای بعدی به شدت افزایش می یابد.
تمرین: درک خود را بررسی کنید
اندازه دسته
اندازه دسته ای یک فراپارامتر است که به تعداد نمونه هایی که مدل قبل از به روز رسانی وزن و سوگیری آن پردازش می کند، اشاره دارد. ممکن است فکر کنید که مدل باید قبل از بهروزرسانی وزنها و بایاس، ضرر را برای هر نمونه در مجموعه داده محاسبه کند. با این حال، زمانی که یک مجموعه داده شامل صدها هزار یا حتی میلیونها مثال باشد، استفاده از دسته کامل عملی نیست.
دو تکنیک رایج برای به دست آوردن گرادیان مناسب به طور متوسط بدون نیاز به نگاه کردن به هر نمونه در مجموعه داده قبل از بهروزرسانی وزنها و بایاس ، نزول گرادیان تصادفی و نزول گرادیان تصادفی دستهای کوچک هستند:
نزول گرادیان تصادفی (SGD) : نزول گرادیان تصادفی تنها از یک مثال واحد (اندازه دسته ای یک) در هر تکرار استفاده می کند. با توجه به تکرارهای کافی، SGD کار می کند اما بسیار پر سر و صدا است. "صدا" به تغییراتی در طول تمرین اشاره دارد که باعث افزایش تلفات به جای کاهش در طول یک تکرار می شود. اصطلاح "تصادفی" نشان می دهد که یک نمونه شامل هر دسته به طور تصادفی انتخاب شده است.
در تصویر زیر توجه کنید که وقتی مدل وزنها و بایاس خود را با استفاده از SGD بهروزرسانی میکند، کاهش اندکی نوسان میکند، که میتواند منجر به نویز در نمودار ضرر شود:
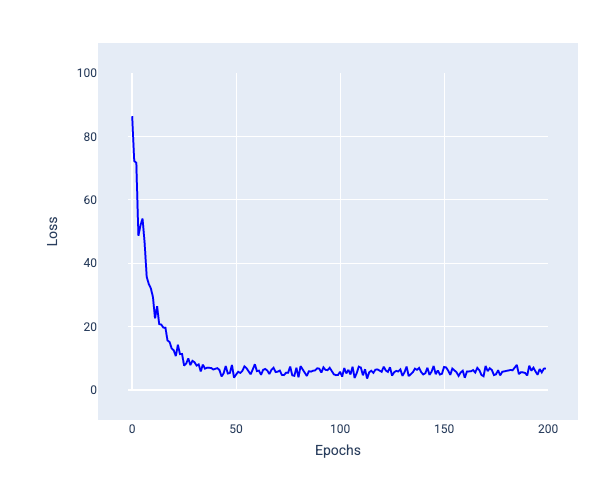
شکل 24 . مدل آموزش دیده با نزول گرادیان تصادفی (SGD) که نویز را در منحنی تلفات نشان می دهد.
توجه داشته باشید که استفاده از نزول گرادیان تصادفی می تواند نویز را در کل منحنی تلفات ایجاد کند، نه فقط نزدیک به همگرایی.
نزول گرادیان تصادفی مینی دسته ای (مینی-بچ SGD) : نزول گرادیان تصادفی مینی دسته ای مصالحه ای بین کل دسته ای و SGD است. برای تعداد $ N $ از نقاط داده، اندازه دسته می تواند هر عددی بزرگتر از 1 و کمتر از $ N $ باشد. مدل نمونههای موجود در هر دسته را بهطور تصادفی انتخاب میکند، گرادیانهای آنها را میانگین میگیرد و سپس وزنها و بایاسها را یک بار در هر تکرار بهروزرسانی میکند.
تعیین تعداد نمونه برای هر دسته به مجموعه داده و منابع محاسباتی موجود بستگی دارد. به طور کلی، اندازههای دستهای کوچک مانند SGD رفتار میکنند و اندازههای دستهای بزرگتر مانند نزول گرادیان کامل دستهای عمل میکنند.
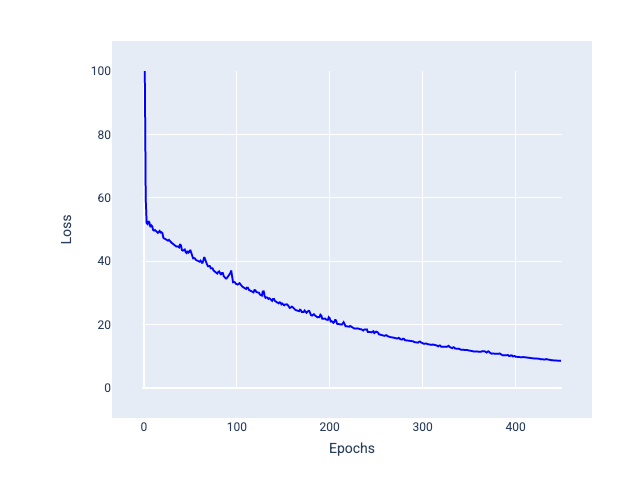
شکل 25 . مدل آموزش دیده با مینی بچ SGD.
هنگام آموزش یک مدل، ممکن است فکر کنید که سر و صدا یک ویژگی نامطلوب است که باید حذف شود. با این حال، مقدار مشخصی از نویز می تواند چیز خوبی باشد. در ماژولهای بعدی، خواهید آموخت که چگونه نویز میتواند به تعمیم بهتر مدل کمک کند و وزنها و سوگیری بهینه را در یک شبکه عصبی پیدا کند.
دوره ها
در طول آموزش، یک دوره به این معنی است که مدل هر نمونه در مجموعه آموزشی را یک بار پردازش کرده است. به عنوان مثال، با توجه به یک مجموعه آموزشی با 1000 نمونه و اندازه کوچک دسته ای 100 نمونه، برای تکمیل یک دوره، 10 تکرار طول می کشد.
آموزش معمولاً به دوره های زیادی نیاز دارد. یعنی سیستم باید هر نمونه در مجموعه آموزشی را چندین بار پردازش کند.
تعداد دوره ها یک فراپارامتر است که قبل از شروع آموزش مدل تنظیم می کنید. در بسیاری از موارد، شما باید آزمایش کنید که چند دوره طول می کشد تا مدل همگرا شود. به طور کلی، دوره های بیشتر مدل بهتری را تولید می کند، اما زمان بیشتری برای آموزش نیاز دارد.
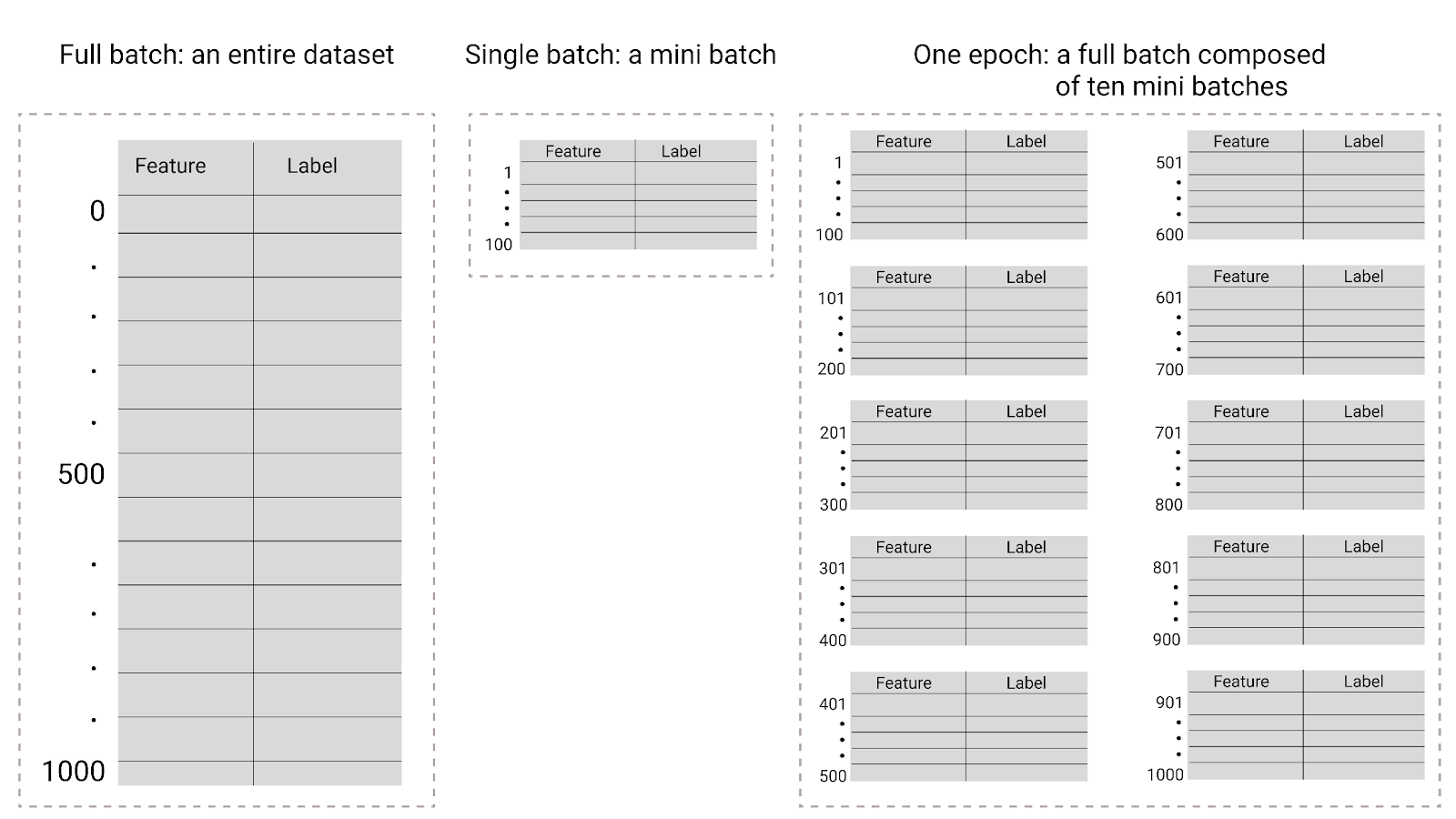
شکل 26 . دسته کامل در مقابل دسته کوچک.
جدول زیر نحوه ارتباط اندازه دسته و دوره ها را با تعداد دفعاتی که یک مدل پارامترهای خود را به روز می کند، توضیح می دهد.
| نوع دسته ای | زمانی که وزن ها و به روز رسانی سوگیری رخ می دهد |
|---|---|
| دسته کامل | بعد از اینکه مدل به تمام نمونه های موجود در مجموعه داده نگاه می کند. به عنوان مثال، اگر یک مجموعه داده شامل 1000 نمونه باشد و مدل برای 20 دوره تمرین کند، مدل وزن ها و سوگیری ها را 20 بار، یک بار در هر دوره به روز می کند. |
| نزول گرادیان تصادفی | بعد از اینکه مدل به یک مثال واحد از مجموعه داده نگاه می کند. به عنوان مثال، اگر یک مجموعه داده شامل 1000 نمونه باشد و برای 20 دوره آموزش داده شود، مدل وزن ها و سوگیری ها را 20000 بار به روز می کند. |
| نزول گرادیان تصادفی دسته ای کوچک | بعد از اینکه مدل به نمونه های هر دسته نگاه می کند. به عنوان مثال، اگر یک مجموعه داده شامل 1000 نمونه باشد، و اندازه دسته ای 100 باشد، و مدل برای 20 دوره تمرین کند، مدل وزن ها و سوگیری ها را 200 بار به روز می کند. |