हाइपरपैरामीटर ऐसे वैरिएबल होते हैं जो ट्रेनिंग के अलग-अलग पहलुओं को कंट्रोल करते हैं. तीन सामान्य हाइपरपैरामीटर ये हैं:
इसके उलट, पैरामीटर ऐसे वैरिएबल होते हैं जो मॉडल का हिस्सा होते हैं. जैसे, वेट और बायस. दूसरे शब्दों में कहें, तो हाइपरपैरामीटर ऐसी वैल्यू होती हैं जिन्हें कंट्रोल किया जा सकता है. वहीं, पैरामीटर ऐसी वैल्यू होती हैं जिन्हें मॉडल, ट्रेनिंग के दौरान कैलकुलेट करता है.
सीखने की दर
लर्निंग रेट एक फ़्लोटिंग पॉइंट नंबर होता है. इसे सेट करने से यह तय होता है कि मॉडल कितनी तेज़ी से कन्वर्ज होगा. अगर लर्निंग रेट बहुत कम है, तो मॉडल को कन्वर्ज होने में ज़्यादा समय लग सकता है. हालांकि, अगर लर्निंग रेट बहुत ज़्यादा है, तो मॉडल कभी भी कन्वर्ज नहीं होता. इसके बजाय, यह उन वज़न और बायस के आस-पास घूमता रहता है जो नुकसान को कम करते हैं. इसका मकसद, एक ऐसी लर्निंग रेट चुनना है जो न तो बहुत ज़्यादा हो और न ही बहुत कम, ताकि मॉडल जल्दी से कन्वर्ज हो जाए.
लर्निंग रेट से यह तय होता है कि ग्रेडिएंट डिसेंट प्रोसेस के हर चरण के दौरान, वेट और बायस में कितने बदलाव किए जाएं. मॉडल, ग्रेडिएंट को लर्निंग रेट से गुणा करता है, ताकि अगले इटरेशन के लिए मॉडल के पैरामीटर (वज़न और बायस वैल्यू) तय किए जा सकें. ग्रेडिएंट डिसेंट के तीसरे चरण में, नेगेटिव स्लोप की दिशा में आगे बढ़ने के लिए "छोटी रकम" का मतलब लर्निंग रेट से है.
पुराने मॉडल के पैरामीटर और नए मॉडल के पैरामीटर के बीच का अंतर, लॉस फ़ंक्शन के स्लोप के हिसाब से होता है. उदाहरण के लिए, अगर स्लोप ज़्यादा है, तो मॉडल बड़ा कदम उठाता है. अगर बदलाव छोटा है, तो छोटा कदम उठाया जाता है. उदाहरण के लिए, अगर ग्रेडिएंट का मैग्नीट्यूड 2.5 है और लर्निंग रेट 0.01 है, तो मॉडल पैरामीटर को 0.025 से बदल देगा.
लर्निंग रेट सही होने पर, मॉडल को कुछ ही इटरेशन में कन्वर्ज होने में मदद मिलती है. आंकड़े 20 में, लॉस कर्व से पता चलता है कि मॉडल, कन्वर्ज होना शुरू होने से पहले, पहले 20 इटरेशन के दौरान बेहतर हुआ है:
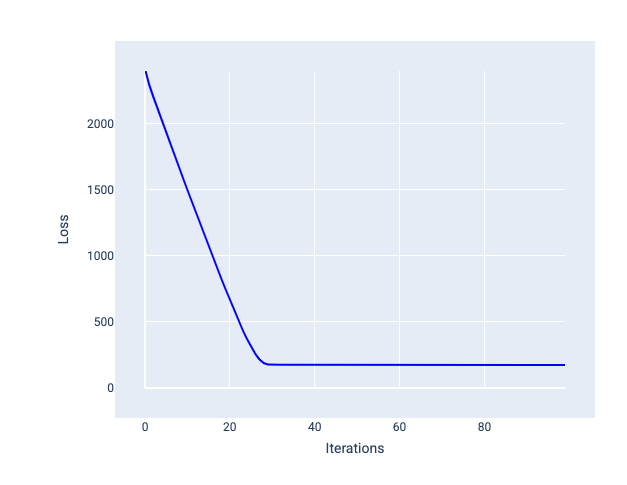
20वीं इमेज. लॉस ग्राफ़ में, लर्निंग रेट के साथ ट्रेन किए गए मॉडल को दिखाया गया है. यह मॉडल, जल्दी कन्वर्ज होता है.
इसके उलट, लर्निंग रेट बहुत कम होने पर, कन्वर्ज होने में बहुत ज़्यादा समय लग सकता है. आंकड़े 21 में, लॉस कर्व से पता चलता है कि हर इटरेशन के बाद मॉडल में सिर्फ़ मामूली सुधार हो रहा है:
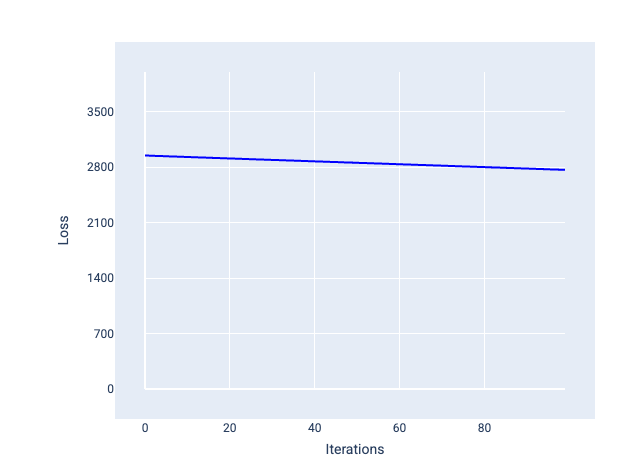
21वीं इमेज. लर्निंग रेट कम होने पर, मॉडल की ट्रेनिंग के दौरान लॉस दिखाने वाला ग्राफ़.
लर्निंग रेट बहुत ज़्यादा होने पर, मॉडल कभी भी कन्वर्ज नहीं होता. ऐसा इसलिए होता है, क्योंकि हर बार के बदलाव से या तो नुकसान कम-ज़्यादा होता रहता है या लगातार बढ़ता रहता है. आंकड़े 22 में, लॉस कर्व से पता चलता है कि हर बार के बाद मॉडल का लॉस कम होता है और फिर बढ़ता है. वहीं, आंकड़े 23 में बाद के इटरेशन में लॉस बढ़ता है:
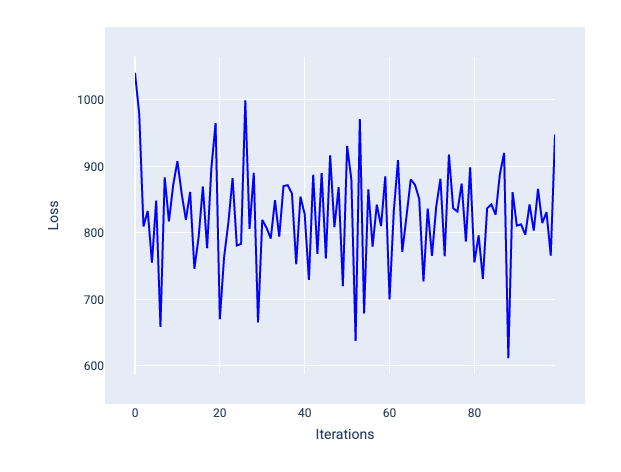
22वीं इमेज. लॉस ग्राफ़ में, बहुत ज़्यादा लर्निंग रेट के साथ ट्रेन किए गए मॉडल को दिखाया गया है. इसमें लॉस कर्व में काफ़ी उतार-चढ़ाव दिख रहा है. साथ ही, इटरेशन बढ़ने पर यह ऊपर और नीचे जा रहा है.
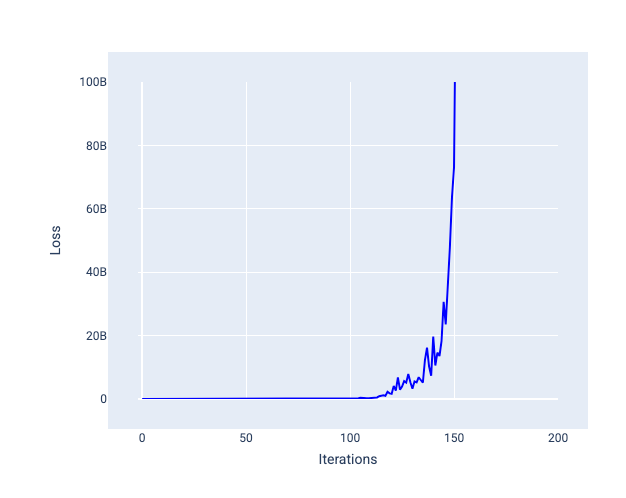
23वीं इमेज. लॉस ग्राफ़ में, लर्निंग रेट के साथ ट्रेन किया गया मॉडल दिखाया गया है. इसमें लर्निंग रेट बहुत ज़्यादा है. इसलिए, बाद के इटरेशन में लॉस कर्व तेज़ी से बढ़ता है.
एक्सरसाइज़: देखें कि आपको कितना समझ आया
बैच का साइज़
बैच का साइज़ एक हाइपरपैरामीटर है. यह उदाहरणों की उस संख्या को दिखाता है जिसे मॉडल, वज़न और बायस को अपडेट करने से पहले प्रोसेस करता है. आपको लग सकता है कि मॉडल को वज़न और पक्षपात को अपडेट करने से पहले, डेटासेट में मौजूद हर उदाहरण के लिए नुकसान का हिसाब लगाना चाहिए. हालांकि, जब किसी डेटासेट में लाखों उदाहरण होते हैं, तो पूरे बैच का इस्तेमाल करना सही नहीं होता.
वज़न और बायस को अपडेट करने से पहले, डेटासेट के हर उदाहरण को देखे बिना औसत पर सही ग्रेडिएंट पाने के लिए, दो सामान्य तकनीकों का इस्तेमाल किया जाता है. ये तकनीकें हैं: स्टोकास्टिक ग्रेडिएंट डिसेंट और मिनी-बैच स्टोकास्टिक ग्रेडिएंट डिसेंट:
स्टोकास्टिक ग्रेडिएंट डिसेंट (एसजीडी): स्टोकास्टिक ग्रेडिएंट डिसेंट, हर बार सिर्फ़ एक उदाहरण (एक का बैच साइज़) का इस्तेमाल करता है. अगर SGD को कई बार दोहराया जाए, तो यह काम करता है. हालांकि, इसमें बहुत ज़्यादा नॉइज़ होता है. "नॉइज़" का मतलब ट्रेनिंग के दौरान होने वाले ऐसे बदलावों से है जिनकी वजह से किसी इटरेशन के दौरान, नुकसान कम होने के बजाय बढ़ जाता है. "स्टोकास्टिक" शब्द का मतलब है कि हर बैच में शामिल एक उदाहरण को बिना किसी क्रम के चुना जाता है.
नीचे दी गई इमेज में देखें कि SGD का इस्तेमाल करके मॉडल के वज़न और बायस को अपडेट करने पर, लॉस में थोड़ा-बहुत बदलाव कैसे होता है. इससे लॉस ग्राफ़ में नॉइज़ आ सकता है:
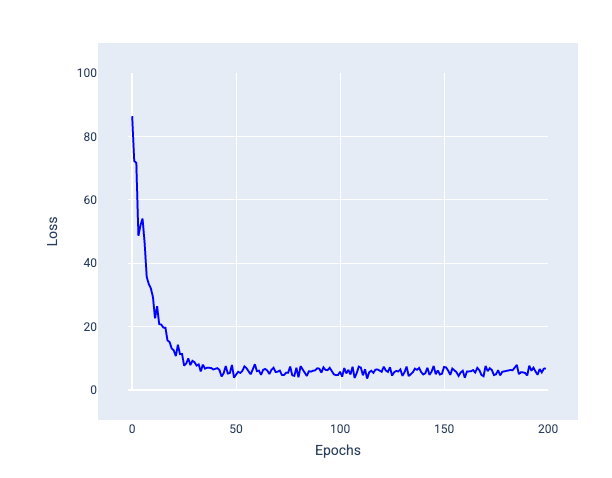
24वीं इमेज. स्टोकास्टिक ग्रेडिएंट डिसेंट (एसजीडी) का इस्तेमाल करके ट्रेन किए गए मॉडल में, लॉस कर्व में नॉइज़ दिख रहा है.
ध्यान दें कि स्टोकैस्टिक ग्रेडिएंट डिसेंट का इस्तेमाल करने से, पूरी लॉस कर्व में नॉइज़ जनरेट हो सकता है. यह सिर्फ़ कन्वर्जेंस के आस-पास नहीं होता.
मिनी-बैच स्टोकैस्टिक ग्रेडिएंट डिसेंट (मिनी-बैच SGD): मिनी-बैच स्टोकैस्टिक ग्रेडिएंट डिसेंट, फ़ुल-बैच और SGD के बीच का एक समझौता है. $ N $ डेटा पॉइंट के लिए, बैच का साइज़ 1 से ज़्यादा और $ N $ से कम हो सकता है. मॉडल, हर बैच में शामिल उदाहरणों को रैंडम तरीके से चुनता है. इसके बाद, उनके ग्रेडिएंट का औसत निकालता है. इसके बाद, हर इटरेशन में एक बार वज़न और बायस को अपडेट करता है.
हर बैच के लिए उदाहरणों की संख्या तय करना, डेटासेट और उपलब्ध कंप्यूट रिसॉर्स पर निर्भर करता है. आम तौर पर, छोटे बैच साइज़, SGD की तरह काम करते हैं. वहीं, बड़े बैच साइज़, फ़ुल-बैच ग्रेडिएंट डिसेंट की तरह काम करते हैं.
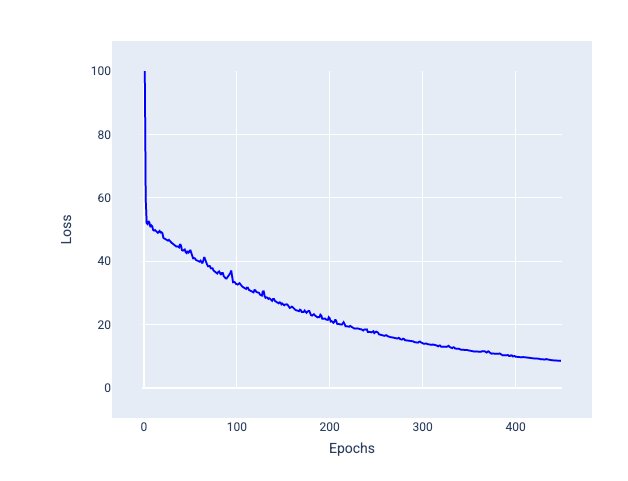
25वीं इमेज. मिनी-बैच SGD का इस्तेमाल करके ट्रेन किया गया मॉडल.
मॉडल को ट्रेनिंग देते समय, आपको लग सकता है कि नॉइज़ एक ऐसी अवांछित विशेषता है जिसे हटा दिया जाना चाहिए. हालांकि, कुछ हद तक शोर होना अच्छा होता है. बाद के मॉड्यूल में, आपको यह जानने को मिलेगा कि नॉइज़, मॉडल को बेहतर तरीके से सामान्य बनाने में कैसे मदद कर सकता है. साथ ही, न्यूरल नेटवर्क में सही वैल्यू और बायस का पता कैसे लगाया जा सकता है.
युग
ट्रेनिंग के दौरान, युग का मतलब है कि मॉडल ने ट्रेनिंग सेट में मौजूद हर उदाहरण को एक बार प्रोसेस कर लिया है. उदाहरण के लिए, अगर ट्रेनिंग सेट में 1,000 उदाहरण हैं और मिनी-बैच का साइज़ 100 उदाहरण हैं, तो मॉडल को एक इपॉक पूरा करने में 10 इटरेशन लगेंगे.
ट्रेनिंग के लिए आम तौर पर कई इपॉक की ज़रूरत होती है. इसका मतलब है कि सिस्टम को ट्रेनिंग सेट में मौजूद हर उदाहरण को कई बार प्रोसेस करना होगा.
इपॉक की संख्या एक हाइपरपैरामीटर है. इसे मॉडल की ट्रेनिंग शुरू होने से पहले सेट किया जाता है. कई मामलों में, आपको यह एक्सपेरिमेंट करना होगा कि मॉडल को कन्वर्ज होने में कितने इपॉक लगते हैं. आम तौर पर, ज़्यादा इपॉक से बेहतर मॉडल बनता है. हालांकि, इसमें ट्रेनिंग में ज़्यादा समय लगता है.
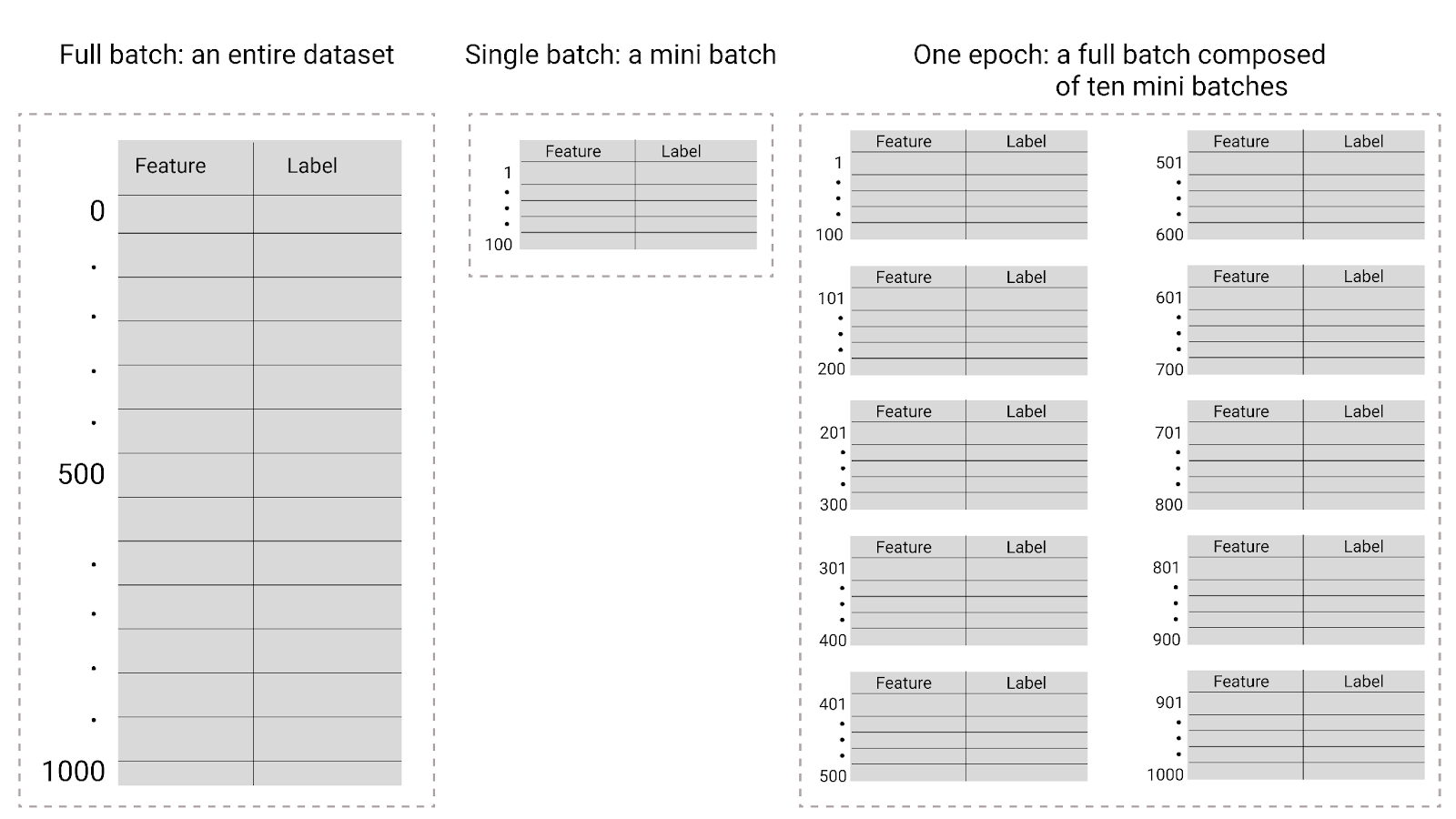
26वीं इमेज. पूरे बैच बनाम मिनी बैच.
इस टेबल में बताया गया है कि बैच साइज़ और इपिक, मॉडल के पैरामीटर को अपडेट करने की संख्या से कैसे जुड़े होते हैं.
| बैच का टाइप | वज़न और पूर्वाग्रह से जुड़े अपडेट कब होते हैं |
|---|---|
| पूरा बैच | जब मॉडल, डेटासेट में मौजूद सभी उदाहरणों को देख लेता है. उदाहरण के लिए, अगर किसी डेटासेट में 1,000 उदाहरण हैं और मॉडल को 20 इपॉक के लिए ट्रेन किया जाता है, तो मॉडल, वज़न और बायस को 20 बार अपडेट करता है. हर इपॉक में एक बार अपडेट किया जाता है. |
| स्टोकेस्टिक ग्रेडिएंट डिसेंट | मॉडल, डेटासेट के किसी एक उदाहरण को देखने के बाद. उदाहरण के लिए, अगर किसी डेटासेट में 1,000 उदाहरण हैं और उसे 20 इपॉक के लिए ट्रेन किया जाता है, तो मॉडल, वज़न और बायस को 20,000 बार अपडेट करता है. |
| मिनी-बैच स्टोकेस्टिक ग्रेडिएंट डिसेंट | जब मॉडल, हर बैच में मौजूद उदाहरणों को देख लेता है. उदाहरण के लिए, अगर किसी डेटासेट में 1,000 उदाहरण हैं और बैच का साइज़ 100 है और मॉडल 20 इपॉक के लिए ट्रेन करता है, तो मॉडल वज़न और बायस को 200 बार अपडेट करता है. |