Gli iperparametri sono variabili che controllano diversi aspetti dell'addestramento. Tre iperparametri comuni sono:
Al contrario, i parametri sono le variabili, come i pesi e il bias, che fanno parte del modello stesso. In altre parole, gli iperparametri sono valori che controlli, mentre i parametri sono valori che il modello calcola durante l'addestramento.
Tasso di apprendimento
Il tasso di apprendimento è un numero in virgola mobile che imposti e che influisce sulla velocità di convergenza del modello. Se il tasso di apprendimento è troppo basso, il modello può impiegare molto tempo per convergere. Tuttavia, se il tasso di apprendimento è troppo alto, il modello non converge mai, ma oscilla tra i pesi e il bias che riducono al minimo la perdita. L'obiettivo è scegliere un tasso di apprendimento non troppo alto né troppo basso, in modo che il modello converga rapidamente.
Il tasso di apprendimento determina l'entità delle modifiche da apportare ai pesi e al bias durante ogni passaggio del processo di discesa del gradiente. Il modello moltiplica il gradiente per il tasso di apprendimento per determinare i parametri del modello (valori di peso e bias) per l'iterazione successiva. Nel terzo passaggio della discesa del gradiente, la "piccola quantità" da spostare nella direzione della pendenza negativa si riferisce al tasso di apprendimento.
La differenza tra i parametri del vecchio modello e quelli del nuovo modello è proporzionale alla pendenza della funzione di perdita. Ad esempio, se la pendenza è elevata, il modello esegue un passo grande. Se è piccolo, fa un piccolo passo. Ad esempio, se l'entità del gradiente è 2,5 e il tasso di apprendimento è 0,01, il modello modificherà il parametro di 0,025.
Il tasso di apprendimento ideale aiuta il modello a convergere in un numero ragionevole di iterazioni. Nella Figura 20, la curva di perdita mostra un miglioramento significativo del modello durante le prime 20 iterazioni prima di iniziare a convergere:
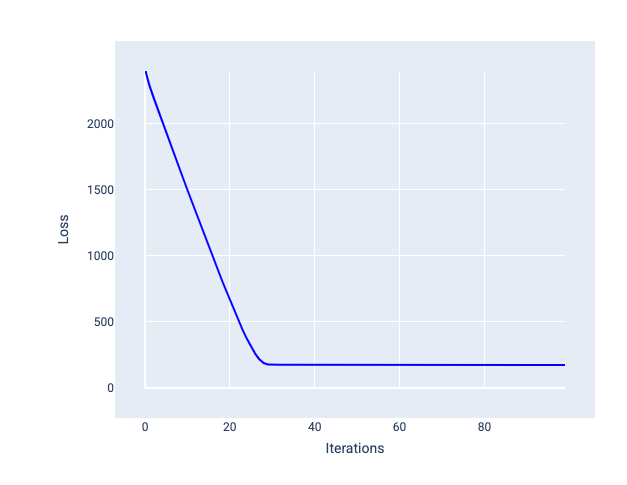
Figura 20. Grafico della perdita che mostra un modello addestrato con un tasso di apprendimento che converge rapidamente.
Al contrario, un tasso di apprendimento troppo basso può richiedere troppe iterazioni per convergere. Nella figura 21, la curva di perdita mostra che il modello apporta solo miglioramenti minori dopo ogni iterazione:
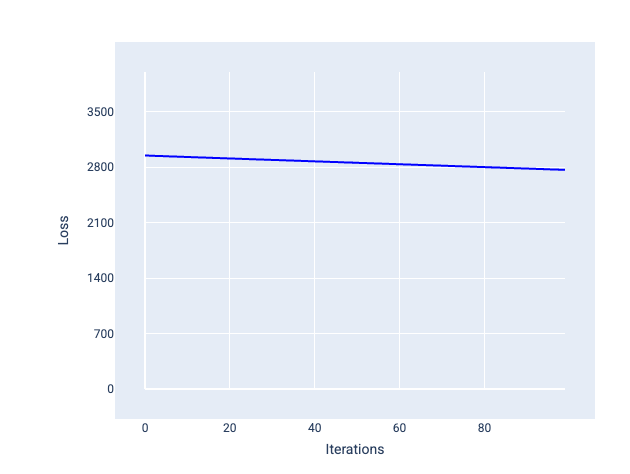
Figura 21. Grafico della perdita che mostra un modello addestrato con un tasso di apprendimento ridotto.
Un tasso di apprendimento troppo elevato non converge mai perché ogni iterazione fa oscillare la perdita o la aumenta continuamente. Nella Figura 22, la curva di perdita mostra la perdita del modello che diminuisce e poi aumenta dopo ogni iterazione, mentre nella Figura 23 la perdita aumenta nelle iterazioni successive:
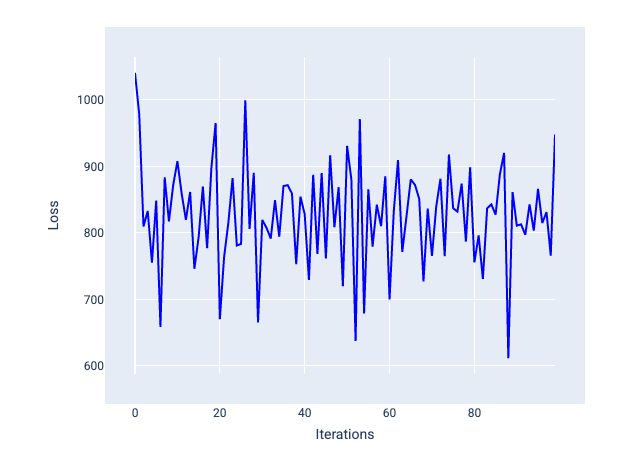
Figura 22. Grafico della perdita che mostra un modello addestrato con un tasso di apprendimento troppo elevato, in cui la curva di perdita oscilla notevolmente, salendo e scendendo con l'aumentare delle iterazioni.
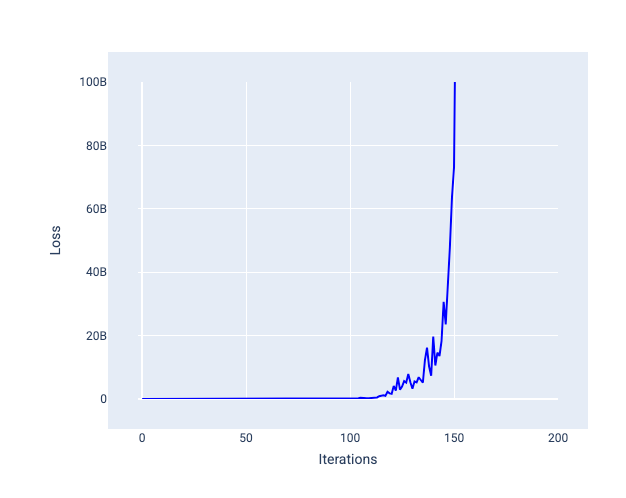
Figura 23. Grafico della perdita che mostra un modello addestrato con un tasso di apprendimento troppo elevato, in cui la curva di perdita aumenta drasticamente nelle iterazioni successive.
Esercizio: verifica la tua comprensione
Dimensione del batch
La dimensione del batch è un iperparametro che si riferisce al numero di esempi che il modello elabora prima di aggiornare i pesi e il bias. Potresti pensare che il modello debba calcolare la perdita per ogni esempio nel set di dati prima di aggiornare i pesi e il bias. Tuttavia, quando un set di dati contiene centinaia di migliaia o addirittura milioni di esempi, l'utilizzo del batch completo non è pratico.
Due tecniche comuni per ottenere il gradiente corretto in media senza dover esaminare ogni esempio nel set di dati prima di aggiornare i pesi e il bias sono stochastic gradient descent e mini-batch stochastic gradient descent:
Discesa stocastica del gradiente (SGD): la discesa stocastica del gradiente utilizza un solo esempio (una dimensione del batch pari a uno) per iterazione. Con un numero sufficiente di iterazioni, SGD funziona, ma è molto rumoroso. Il "rumore" si riferisce alle variazioni durante l'addestramento che causano un aumento della perdita anziché una diminuzione durante un'iterazione. Il termine "stocastico" indica che l'esempio che compone ogni batch viene scelto in modo casuale.
Nell'immagine seguente, nota come la perdita oscilla leggermente man mano che il modello aggiorna i pesi e il bias utilizzando SGD, il che può portare a rumore nel grafico della perdita:
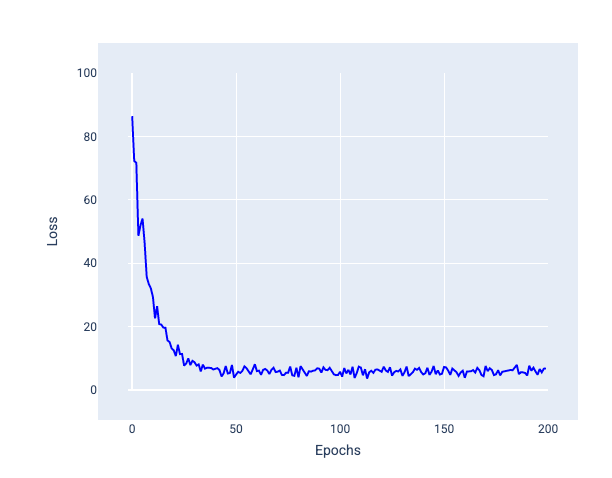
Figura 24. Modello addestrato con la discesa del gradiente stocastico (SGD) che mostra rumore nella curva di perdita.
Tieni presente che l'utilizzo della discesa del gradiente stocastico può produrre rumore in tutta la curva di perdita, non solo in prossimità della convergenza.
Discesa stocastica del gradiente in mini-batch (mini-batch SGD): la discesa stocastica del gradiente in mini-batch è un compromesso tra full-batch e SGD. Per $ N $ punti dati, la dimensione del batch può essere qualsiasi numero maggiore di 1 e inferiore a $ N $. Il modello sceglie gli esempi inclusi in ogni batch in modo casuale, calcola la media dei gradienti e poi aggiorna i pesi e il bias una volta per iterazione.
La determinazione del numero di esempi per ogni batch dipende dal set di dati e dalle risorse di calcolo disponibili. In generale, batch di piccole dimensioni si comportano come SGD, mentre batch di dimensioni maggiori si comportano come la discesa del gradiente full-batch.
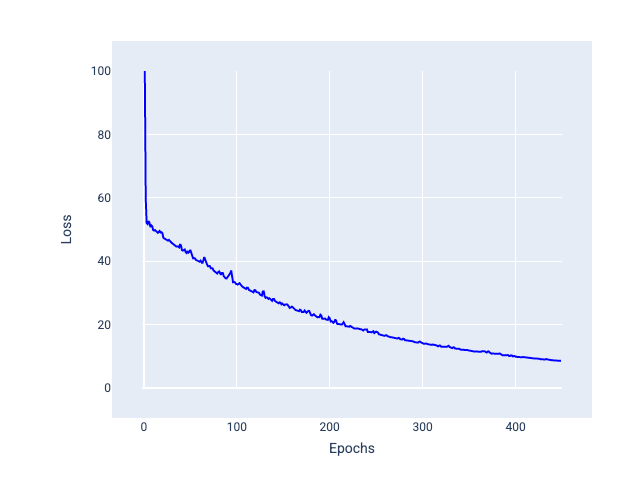
Figura 25. Modello addestrato con SGD mini-batch.
Durante l'addestramento di un modello, potresti pensare che il rumore sia una caratteristica indesiderabile che dovrebbe essere eliminata. Tuttavia, una certa quantità di rumore può essere una cosa positiva. Nei moduli successivi, imparerai come il rumore può aiutare un modello a generalizzare meglio e a trovare i pesi e i bias ottimali in una rete neurale.
Epoche
Durante l'addestramento, un periodo indica che il modello ha elaborato ogni esempio nel set di addestramento una volta. Ad esempio, dato un set di addestramento con 1000 esempi e una dimensione del mini-batch di 100 esempi, il modello impiegherà 10 iterazioni per completare un'epoca.
L'addestramento in genere richiede molte epoche. ovvero il sistema deve elaborare più volte ogni esempio nel set di addestramento.
Il numero di epoche è un iperparametro che imposti prima che il modello inizi l'addestramento. In molti casi, dovrai sperimentare il numero di epoche necessarie per la convergenza del modello. In generale, più sono le epoche, migliore sarà il modello, ma anche più tempo ci vorrà per l'addestramento.
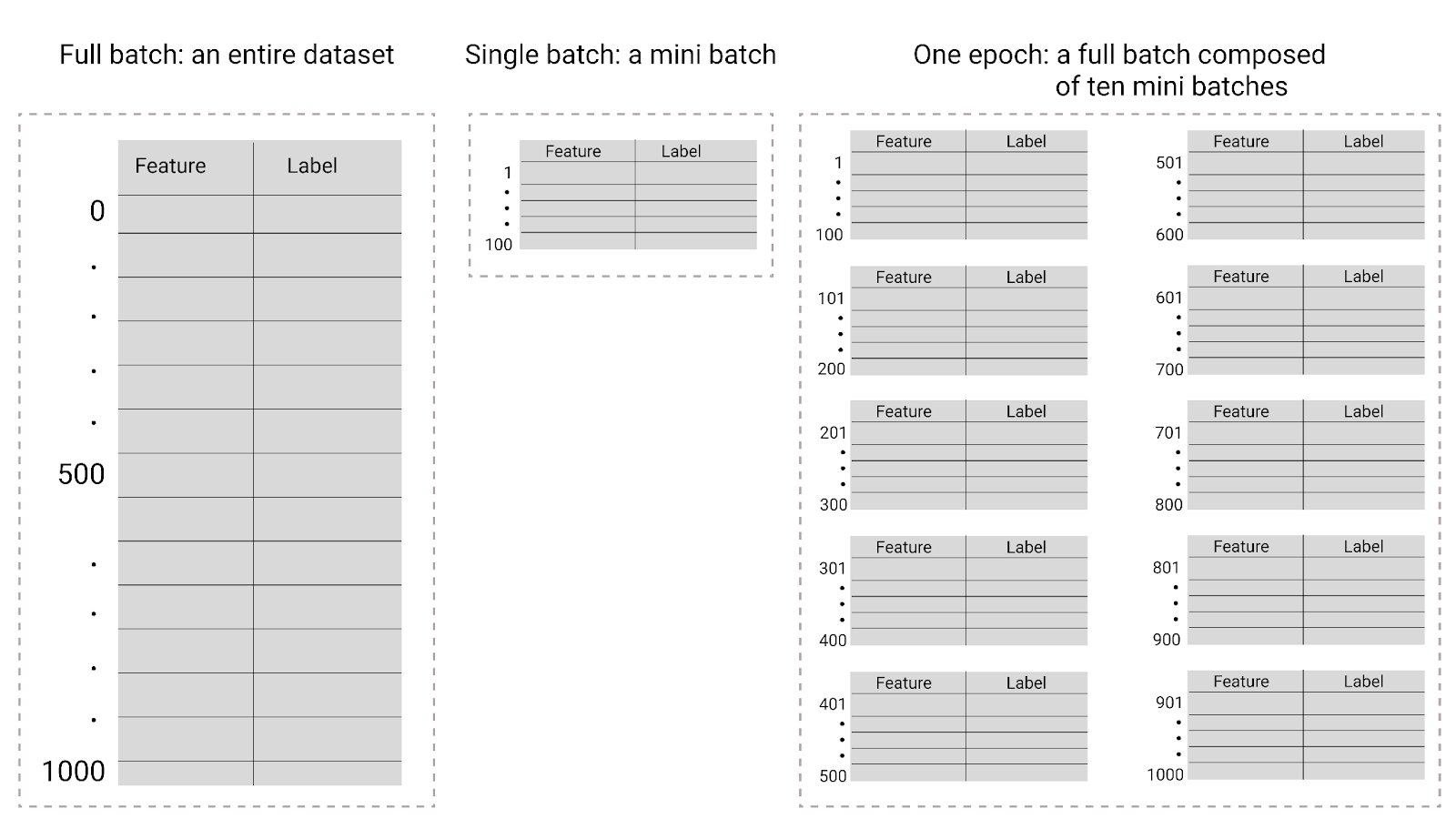
Figura 26. Batch completo e mini-batch.
La tabella seguente descrive la relazione tra le dimensioni del batch e le epoche e il numero di volte in cui un modello aggiorna i suoi parametri.
| Tipo batch | Quando si verificano aggiornamenti di pesi e bias |
|---|---|
| Batch completo | Dopo che il modello ha esaminato tutti gli esempi nel set di dati. Ad esempio, se un set di dati contiene 1000 esempi e il modello viene addestrato per 20 epoche, il modello aggiorna i pesi e il bias 20 volte, una volta per epoca. |
| Discesa stocastica del gradiente | Dopo che il modello ha esaminato un singolo esempio del set di dati. Ad esempio, se un set di dati contiene 1000 esempi e viene addestrato per 20 epoche, il modello aggiorna i pesi e il bias 20.000 volte. |
| Discesa stocastica del gradiente in mini-batch | Dopo che il modello ha esaminato gli esempi in ogni batch. Ad esempio, se un set di dati contiene 1000 esempi e la dimensione del batch è 100 e il modello viene addestrato per 20 epoche, il modello aggiorna i pesi e il bias 200 volte. |