Les hyperparamètres sont des variables qui contrôlent différents aspects de l'entraînement. Voici trois hyperparamètres courants :
En revanche, les paramètres sont les variables, comme les pondérations et le biais, qui font partie du modèle lui-même. En d'autres termes, les hyperparamètres sont des valeurs que vous contrôlez, tandis que les paramètres sont des valeurs que le modèle calcule pendant l'entraînement.
Taux d'apprentissage
Le taux d'apprentissage est un nombre à virgule flottante que vous définissez et qui influence la vitesse de convergence du modèle. Si le taux d'apprentissage est trop faible, le modèle peut mettre beaucoup de temps à converger. Toutefois, si le taux d'apprentissage est trop élevé, le modèle ne converge jamais. Au lieu de cela, il rebondit autour des pondérations et du biais qui minimisent la perte. L'objectif est de choisir un taux d'apprentissage qui n'est ni trop élevé ni trop faible afin que le modèle converge rapidement.
Le taux d'apprentissage détermine l'ampleur des modifications à apporter aux pondérations et au biais à chaque étape du processus de descente de gradient. Le modèle multiplie le gradient par le taux d'apprentissage pour déterminer les paramètres du modèle (valeurs de pondération et de biais) pour la prochaine itération. Dans la troisième étape de la descente de gradient, la "petite quantité" à déplacer dans la direction de la pente négative fait référence au taux d'apprentissage.
La différence entre les anciens et les nouveaux paramètres du modèle est proportionnelle à la pente de la fonction de perte. Par exemple, si la pente est forte, le modèle effectue un grand pas. Si elle est petite, elle fait un petit pas. Par exemple, si l'amplitude du gradient est de 2,5 et que le taux d'apprentissage est de 0,01, le modèle modifiera le paramètre de 0,025.
Le taux d'apprentissage idéal aide le modèle à converger dans un nombre raisonnable d'itérations. Dans la figure 20, la courbe de perte montre que le modèle s'améliore considérablement au cours des 20 premières itérations avant de commencer à converger :
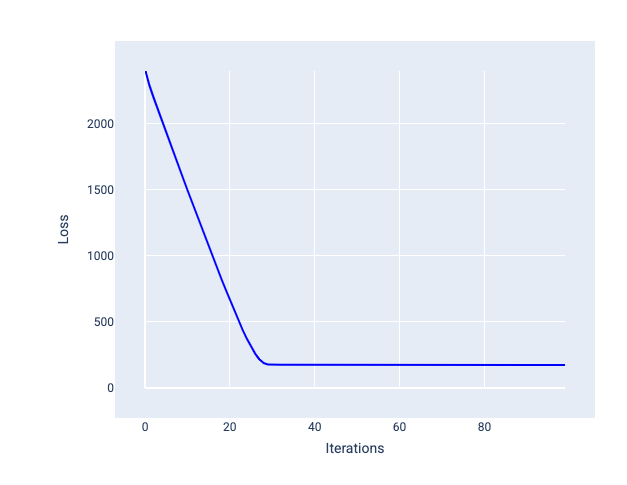
Figure 20. Graphique de perte montrant un modèle entraîné avec un taux d'apprentissage qui converge rapidement.
En revanche, un taux d'apprentissage trop faible peut nécessiter trop d'itérations pour converger. Dans la figure 21, la courbe de perte montre que le modèle ne s'améliore que légèrement après chaque itération :
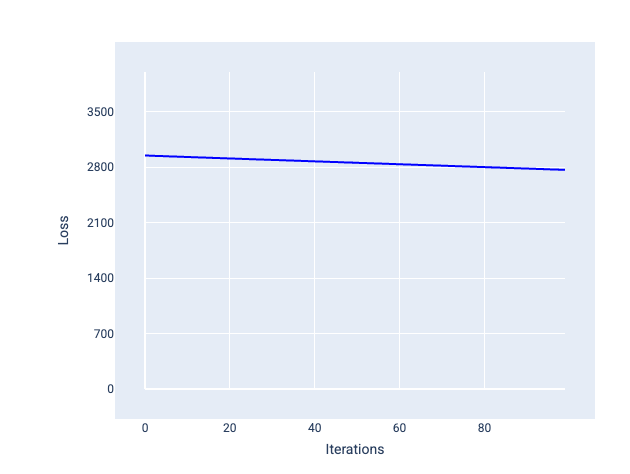
Figure 21. Graphique de perte montrant un modèle entraîné avec un faible taux d'apprentissage.
Un taux d'apprentissage trop élevé ne converge jamais, car chaque itération entraîne une perte qui fluctue ou augmente continuellement. Dans la figure 22, la courbe de perte montre que la perte du modèle diminue, puis augmente après chaque itération. Dans la figure 23, la perte augmente lors des dernières itérations :
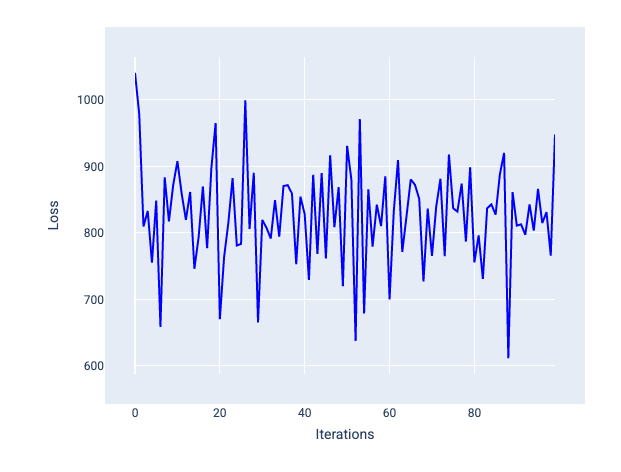
Figure 22. Graphique de perte montrant un modèle entraîné avec un taux d'apprentissage trop élevé, où la courbe de perte fluctue énormément, montant et descendant à mesure que les itérations augmentent.
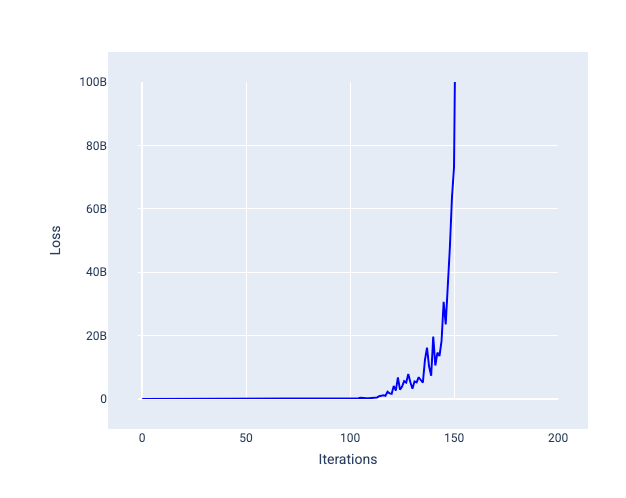
Figure 23. Graphique de perte montrant un modèle entraîné avec un taux d'apprentissage trop élevé, où la courbe de perte augmente considérablement lors des dernières itérations.
Exercice : Vérifier vos connaissances
Taille de lot
La taille du lot est un hyperparamètre qui fait référence au nombre d'exemples que le modèle traite avant de mettre à jour ses pondérations et son biais. Vous pourriez penser que le modèle devrait calculer la perte pour chaque exemple de l'ensemble de données avant de mettre à jour les pondérations et le biais. Toutefois, lorsqu'un ensemble de données contient des centaines de milliers, voire des millions d'exemples, il n'est pas pratique d'utiliser le lot complet.
Deux techniques courantes permettent d'obtenir le bon gradient moyen sans avoir à examiner chaque exemple du jeu de données avant de mettre à jour les pondérations et le biais : la descente de gradient stochastique et la descente de gradient stochastique par mini-lots.
Descente de gradient stochastique (SGD) : la descente de gradient stochastique n'utilise qu'un seul exemple (une taille de lot de un) par itération. Avec suffisamment d'itérations, la descente de gradient stochastique fonctionne, mais elle est très bruyante. Le "bruit" fait référence aux variations pendant l'entraînement qui entraînent une augmentation de la perte plutôt qu'une diminution lors d'une itération. Le terme "stochastique" indique que l'exemple qui compose chaque lot est choisi au hasard.
Dans l'image suivante, vous pouvez voir comment la perte fluctue légèrement lorsque le modèle met à jour ses pondérations et son biais à l'aide de la descente de gradient stochastique (SGD), ce qui peut entraîner du bruit dans le graphique de perte :
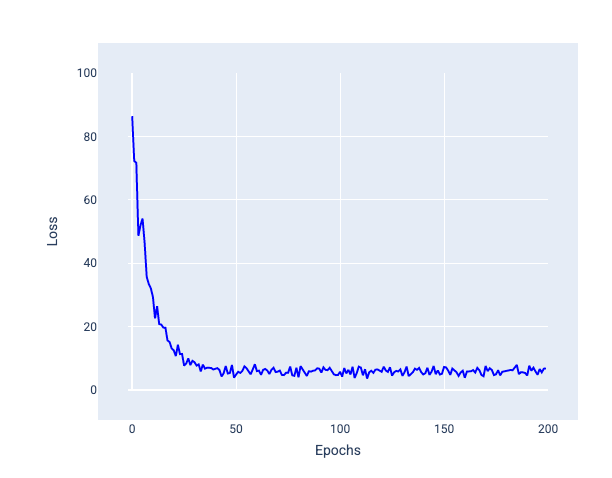
Figure 24. Modèle entraîné avec une descente de gradient stochastique (SGD) montrant du bruit dans la courbe de perte.
Notez que l'utilisation de la descente de gradient stochastique peut générer du bruit tout au long de la courbe de perte, et pas seulement près de la convergence.
Descente de gradient stochastique par mini-lots (mini-batch SGD) : la descente de gradient stochastique par mini-lots est un compromis entre la descente de gradient par lots complets et la descente de gradient stochastique. Pour un nombre de points de données $ N $, la taille du lot peut être n'importe quel nombre supérieur à 1 et inférieur à $ N $. Le modèle choisit au hasard les exemples inclus dans chaque lot, calcule la moyenne de leurs gradients, puis met à jour les pondérations et le biais une fois par itération.
Le nombre d'exemples pour chaque lot dépend de l'ensemble de données et des ressources de calcul disponibles. En général, les petites tailles de lot se comportent comme la descente de gradient stochastique (SGD), et les grandes tailles de lot se comportent comme la descente de gradient par lot complet.
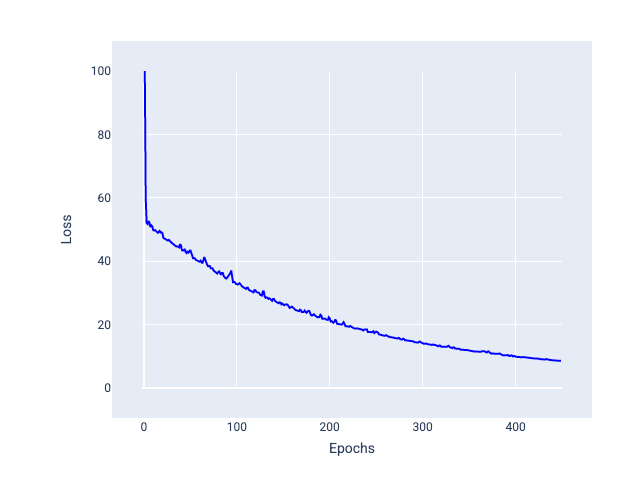
Figure 25 : Modèle entraîné avec SGD par mini-lots.
Lorsque vous entraînez un modèle, vous pouvez penser que le bruit est une caractéristique indésirable qui doit être éliminée. Cependant, un certain niveau de bruit peut être bénéfique. Dans les modules suivants, vous apprendrez comment le bruit peut aider un modèle à mieux généraliser et à trouver les pondérations et le biais optimaux dans un réseau de neurones.
Époques
Lors de l'entraînement, une époque signifie que le modèle a traité une fois chaque exemple de l'ensemble d'entraînement. Par exemple, si un ensemble d'entraînement comporte 1 000 exemples et que la taille du minibatch est de 100 exemples, le modèle aura besoin de 10 itérations pour effectuer une époque.
L'entraînement nécessite généralement de nombreuses époques. Autrement dit, le système doit traiter plusieurs fois chaque exemple de l'ensemble d'entraînement.
Le nombre d'époques est un hyperparamètre que vous définissez avant le début de l'entraînement du modèle. Dans de nombreux cas, vous devrez tester le nombre d'époques nécessaires pour que le modèle converge. En général, plus le nombre d'époques est élevé, meilleur est le modèle, mais plus l'entraînement prend de temps.
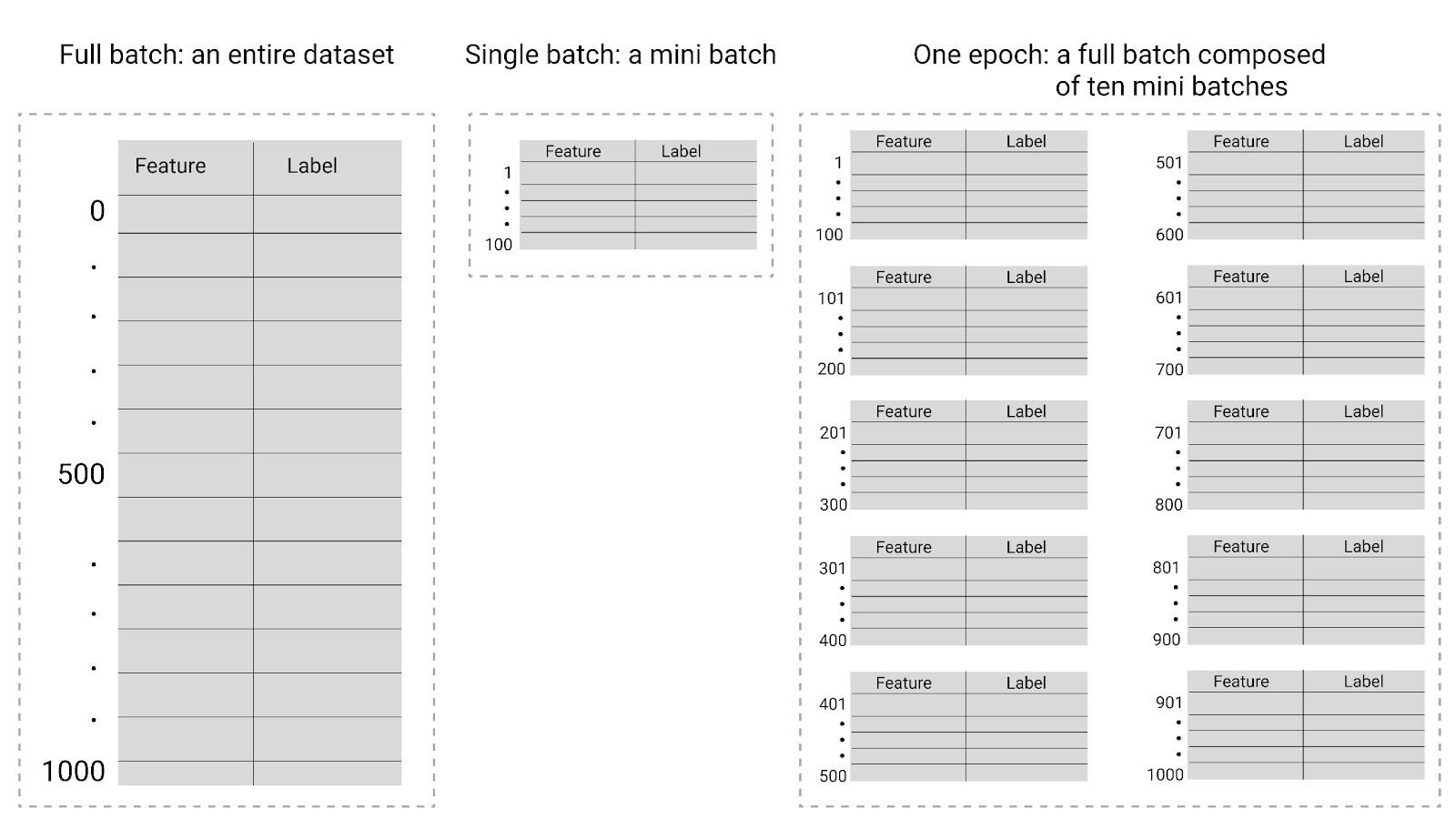
Figure 26. Lot complet ou mini-lot.
Le tableau suivant décrit le lien entre la taille du lot et les époques, et le nombre de fois où un modèle met à jour ses paramètres.
| Type de lot | Quand les pondérations et les biais sont mis à jour |
|---|---|
| Lot complet | Après que le modèle a examiné tous les exemples de l'ensemble de données. Par exemple, si un ensemble de données contient 1 000 exemples et que le modèle s'entraîne pendant 20 époques, il met à jour les pondérations et le biais 20 fois, une fois par époque. |
| Descente de gradient stochastique | Après que le modèle a examiné un seul exemple de l'ensemble de données. Par exemple, si un ensemble de données contient 1 000 exemples et s'entraîne pendant 20 époques, le modèle met à jour les pondérations et le biais 20 000 fois. |
| Descente de gradient stochastique par mini-lots | Après que le modèle a examiné les exemples de chaque lot. Par exemple, si un ensemble de données contient 1 000 exemples, que la taille de lot est de 100 et que le modèle s'entraîne pendant 20 époques, le modèle met à jour les pondérations et le biais 200 fois. |