Siêu tham số là các biến kiểm soát nhiều khía cạnh của quá trình huấn luyện. 3 siêu tham số phổ biến là:
Ngược lại, tham số là các biến (chẳng hạn như trọng số và độ lệch) thuộc chính mô hình. Nói cách khác, siêu tham số là những giá trị mà bạn kiểm soát; tham số là những giá trị mà mô hình tính toán trong quá trình huấn luyện.
Tốc độ học
Tốc độ học tập là một số thực mà bạn đặt để ảnh hưởng đến tốc độ hội tụ của mô hình. Nếu tốc độ học quá thấp, mô hình có thể mất nhiều thời gian để hội tụ. Tuy nhiên, nếu tốc độ học tập quá cao, mô hình sẽ không bao giờ hội tụ, mà thay vào đó sẽ dao động xung quanh các trọng số và độ lệch giúp giảm thiểu tổn thất. Mục tiêu là chọn tốc độ học tập không quá cao cũng không quá thấp để mô hình hội tụ nhanh chóng.
Tốc độ học xác định mức độ thay đổi cần thực hiện đối với các trọng số và độ lệch trong mỗi bước của quy trình hạ độ dốc. Mô hình nhân độ dốc với tốc độ học để xác định các tham số của mô hình (giá trị trọng số và độ lệch) cho lần lặp lại tiếp theo. Trong bước thứ ba của hạ dốc theo độ dốc, "một lượng nhỏ" cần di chuyển theo hướng dốc âm đề cập đến tốc độ học.
Sự khác biệt giữa các tham số mô hình cũ và các tham số mô hình mới tỷ lệ thuận với độ dốc của hàm tổn thất. Ví dụ: nếu độ dốc lớn, mô hình sẽ thực hiện một bước lớn. Nếu nhỏ, hãy thực hiện một bước nhỏ. Ví dụ: nếu độ lớn của độ dốc là 2,5 và tốc độ học là 0,01, thì mô hình sẽ thay đổi tham số theo 0,025.
Tốc độ học tập lý tưởng giúp mô hình hội tụ trong một số lần lặp lại hợp lý. Trong Hình 20, đường cong tổn thất cho thấy mô hình cải thiện đáng kể trong 20 lần lặp đầu tiên trước khi bắt đầu hội tụ:
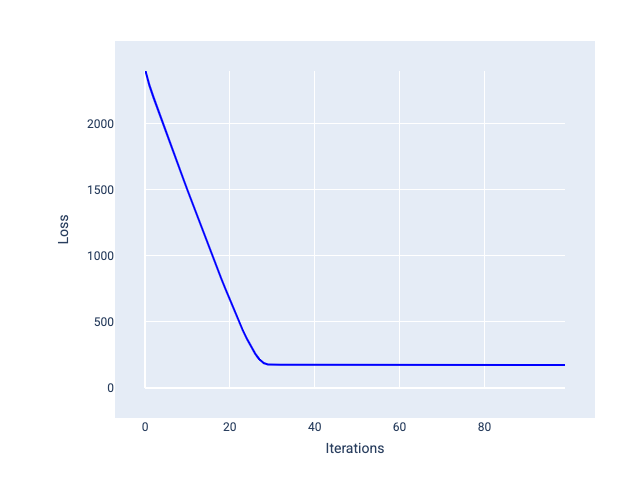
Hình 20. Biểu đồ tổn thất cho thấy một mô hình được huấn luyện với tốc độ học tập hội tụ nhanh chóng.
Ngược lại, tốc độ học tập quá nhỏ có thể mất quá nhiều lần lặp lại để hội tụ. Trong Hình 21, đường cong tổn thất cho thấy mô hình chỉ cải thiện một chút sau mỗi lần lặp lại:
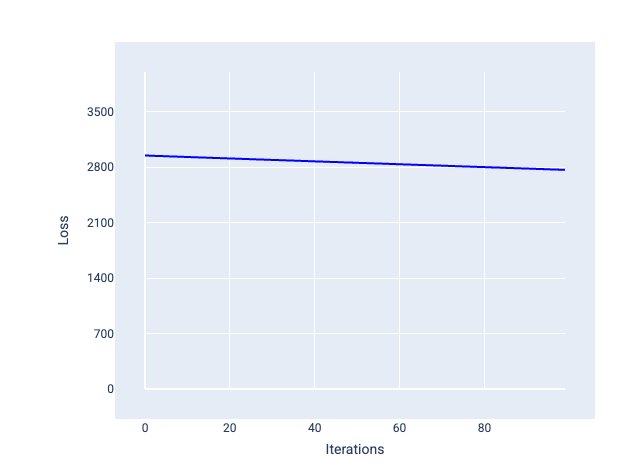
Hình 21. Biểu đồ tổn thất cho thấy một mô hình được huấn luyện với tốc độ học tập nhỏ.
Tốc độ học tập quá lớn sẽ không bao giờ hội tụ vì mỗi lần lặp lại đều khiến tổn thất tăng lên hoặc liên tục tăng. Trong Hình 22, đường cong tổn thất cho thấy mô hình giảm rồi tăng tổn thất sau mỗi lần lặp lại, còn trong Hình 23, tổn thất tăng ở các lần lặp lại sau:
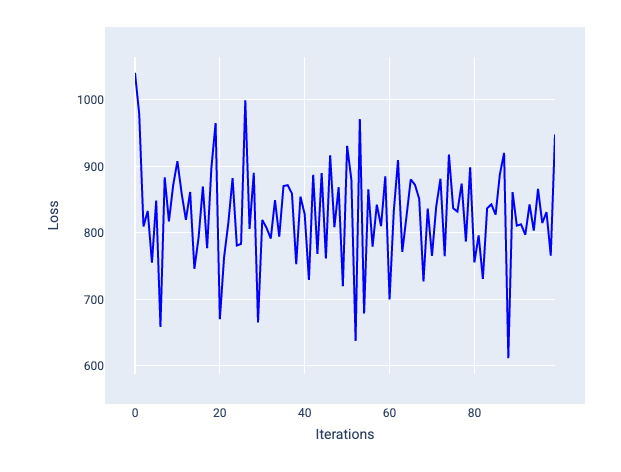
Hình 22. Biểu đồ tổn thất cho thấy một mô hình được huấn luyện với tốc độ học tập quá lớn, trong đó đường cong tổn thất biến động mạnh, tăng và giảm khi số lần lặp lại tăng lên.
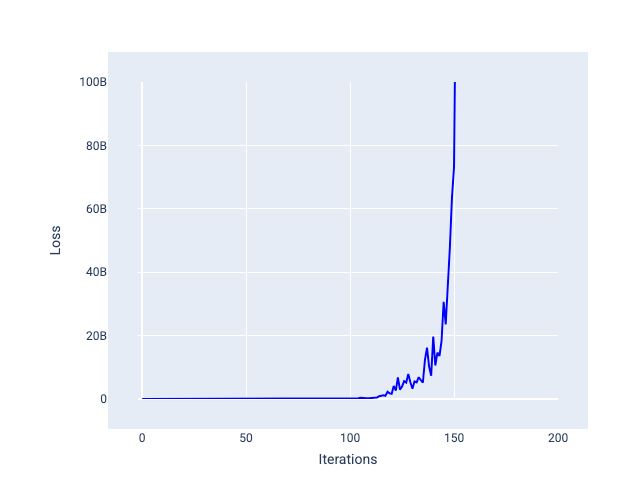
Hình 23. Biểu đồ tổn thất cho thấy một mô hình được huấn luyện với tốc độ học tập quá lớn, trong đó đường cong tổn thất tăng lên đáng kể trong các lần lặp lại sau này.
Bài tập: Kiểm tra mức độ hiểu biết của bạn
Kích thước lô
Kích thước lô là một siêu tham số đề cập đến số lượng ví dụ mà mô hình xử lý trước khi cập nhật trọng số và độ lệch. Bạn có thể nghĩ rằng mô hình sẽ tính toán tổn thất cho mọi ví dụ trong tập dữ liệu trước khi cập nhật trọng số và độ lệch. Tuy nhiên, khi một tập dữ liệu chứa hàng trăm nghìn hoặc thậm chí hàng triệu ví dụ, việc sử dụng toàn bộ lô là không thực tế.
Hai kỹ thuật phổ biến để có được độ dốc phù hợp trên trung bình mà không cần xem xét mọi ví dụ trong tập dữ liệu trước khi cập nhật trọng số và độ lệch là phương pháp hạ độ dốc ngẫu nhiên và phương pháp hạ độ dốc ngẫu nhiên theo lô nhỏ:
Giảm độ dốc ngẫu nhiên (SGD): Giảm độ dốc ngẫu nhiên chỉ sử dụng một ví dụ (kích thước lô là một) cho mỗi lần lặp. Với đủ số lần lặp lại, SGD sẽ hoạt động nhưng rất ồn. "Nhiễu" đề cập đến các biến thể trong quá trình huấn luyện khiến tổn thất tăng thay vì giảm trong một lần lặp. Thuật ngữ "ngẫu nhiên" cho biết một ví dụ bao gồm mỗi lô được chọn ngẫu nhiên.
Hãy lưu ý trong hình ảnh sau đây cách tổn thất dao động nhẹ khi mô hình cập nhật trọng số và độ lệch bằng cách sử dụng SGD, điều này có thể dẫn đến nhiễu trong biểu đồ tổn thất:
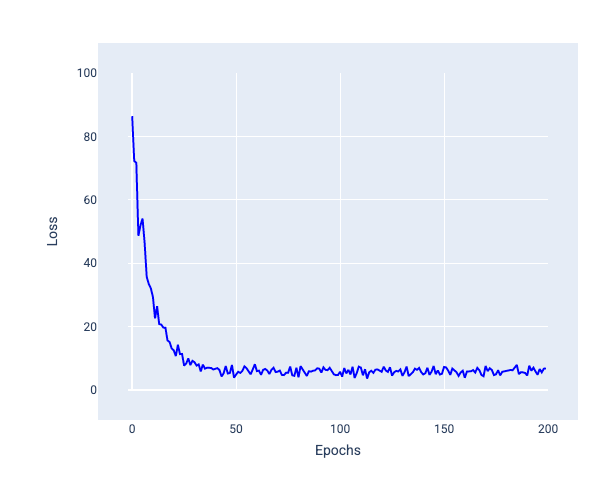
Hình 24. Mô hình được huấn luyện bằng phương pháp giảm độ dốc ngẫu nhiên (SGD) cho thấy nhiễu trong đường cong tổn thất.
Xin lưu ý rằng việc sử dụng phương pháp hạ dốc ngẫu nhiên có thể tạo ra nhiễu trong toàn bộ đường cong tổn thất, chứ không chỉ gần điểm hội tụ.
Phương pháp giảm độ dốc ngẫu nhiên trên gói nhỏ (mini-batch SGD): Phương pháp giảm độ dốc ngẫu nhiên trên gói nhỏ là một giải pháp thoả hiệp giữa phương pháp giảm độ dốc ngẫu nhiên trên toàn bộ lô và phương pháp giảm độ dốc ngẫu nhiên. Đối với $ N $ số điểm dữ liệu, kích thước lô có thể là bất kỳ số nào lớn hơn 1 và nhỏ hơn $ N $. Mô hình chọn ngẫu nhiên các ví dụ có trong mỗi lô, tính trung bình các độ dốc của chúng, rồi cập nhật trọng số và độ lệch một lần cho mỗi lần lặp.
Việc xác định số lượng ví dụ cho mỗi lô phụ thuộc vào tập dữ liệu và tài nguyên điện toán có sẵn. Nhìn chung, kích thước lô nhỏ hoạt động như SGD và kích thước lô lớn hoạt động như phương pháp hạ độ dốc theo lô đầy đủ.
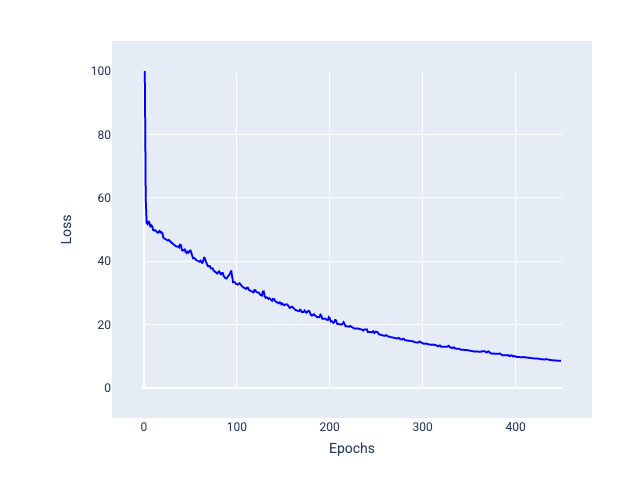
Hình 25. Mô hình được huấn luyện bằng SGD trên gói nhỏ.
Khi huấn luyện một mô hình, bạn có thể cho rằng nhiễu là một đặc điểm không mong muốn cần loại bỏ. Tuy nhiên, một lượng tiếng ồn nhất định có thể là điều tốt. Trong các mô-đun sau, bạn sẽ tìm hiểu cách nhiễu có thể giúp một mô hình khái quát hoá tốt hơn và tìm ra các trọng số và độ lệch tối ưu trong một mạng nơ-ron.
Epoch
Trong quá trình huấn luyện, epoch có nghĩa là mô hình đã xử lý mọi ví dụ trong tập huấn luyện một lần. Ví dụ: với một tập hợp huấn luyện có 1.000 ví dụ và kích thước lô nhỏ là 100 ví dụ, mô hình sẽ mất 10 lần lặp lại để hoàn thành một giai đoạn.
Quá trình huấn luyện thường đòi hỏi nhiều giai đoạn. Tức là hệ thống cần xử lý nhiều lần mọi ví dụ trong tập huấn luyện.
Số lượng epoch là một siêu tham số mà bạn đặt trước khi mô hình bắt đầu huấn luyện. Trong nhiều trường hợp, bạn sẽ cần thử nghiệm với số lượng epoch cần thiết để mô hình hội tụ. Nhìn chung, số lượng giai đoạn càng nhiều thì mô hình càng tốt, nhưng cũng mất nhiều thời gian hơn để huấn luyện.
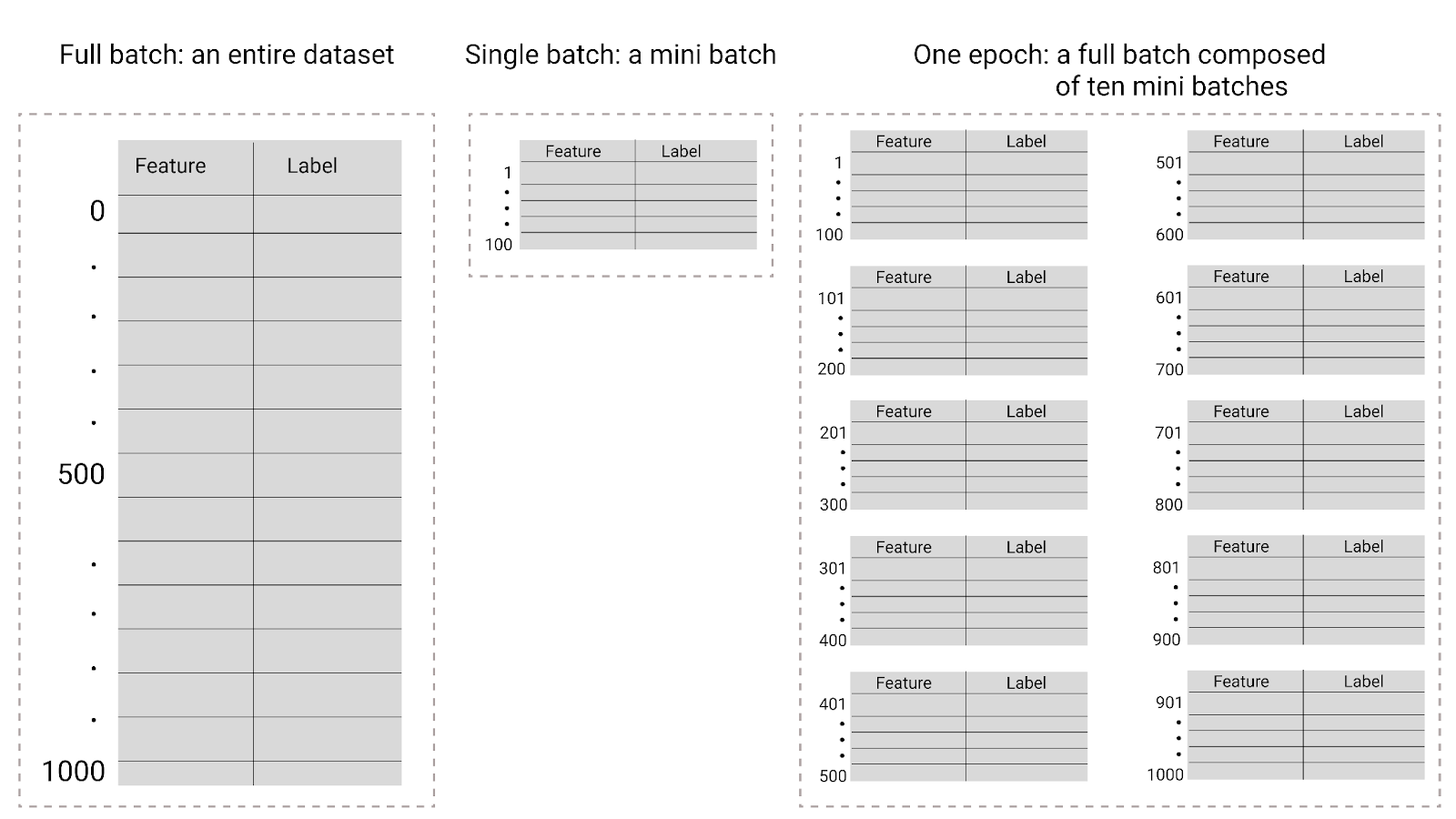
Hình 26. Lô đầy đủ so với lô nhỏ.
Bảng sau đây mô tả mối quan hệ giữa kích thước lô và số lượng giai đoạn huấn luyện với số lần một mô hình cập nhật các tham số của mô hình đó.
| Loại lô | Khi có bản cập nhật về trọng số và độ lệch |
|---|---|
| Toàn bộ lô | Sau khi mô hình xem xét tất cả các ví dụ trong tập dữ liệu. Ví dụ: nếu một tập dữ liệu chứa 1.000 ví dụ và mô hình huấn luyện trong 20 giai đoạn, thì mô hình sẽ cập nhật trọng số và độ lệch 20 lần, mỗi lần một giai đoạn. |
| Phương pháp giảm độ dốc ngẫu nhiên | Sau khi mô hình xem xét một ví dụ duy nhất trong tập dữ liệu. Ví dụ: nếu một tập dữ liệu chứa 1.000 ví dụ và huấn luyện trong 20 giai đoạn, thì mô hình sẽ cập nhật trọng số và độ lệch 20.000 lần. |
| Phương pháp giảm độ dốc ngẫu nhiên trên gói nhỏ | Sau khi mô hình xem xét các ví dụ trong mỗi lô. Ví dụ: nếu một tập dữ liệu chứa 1.000 ví dụ, kích thước lô là 100 và mô hình huấn luyện trong 20 giai đoạn, thì mô hình sẽ cập nhật trọng số và độ lệch 200 lần. |