Strata to wartość liczbowa, która opisuje, jak bardzo prognozy modelu są błędne. Funkcja straty mierzy odległość między prognozami modelu a rzeczywistymi etykietami. Celem trenowania modelu jest zminimalizowanie straty, czyli zmniejszenie jej do najniższej możliwej wartości.
Na poniższym obrazie możesz zobaczyć funkcję straty jako strzałki narysowane od punktów danych do modelu. Strzałki pokazują, jak bardzo prognozy modelu odbiegają od rzeczywistych wartości.
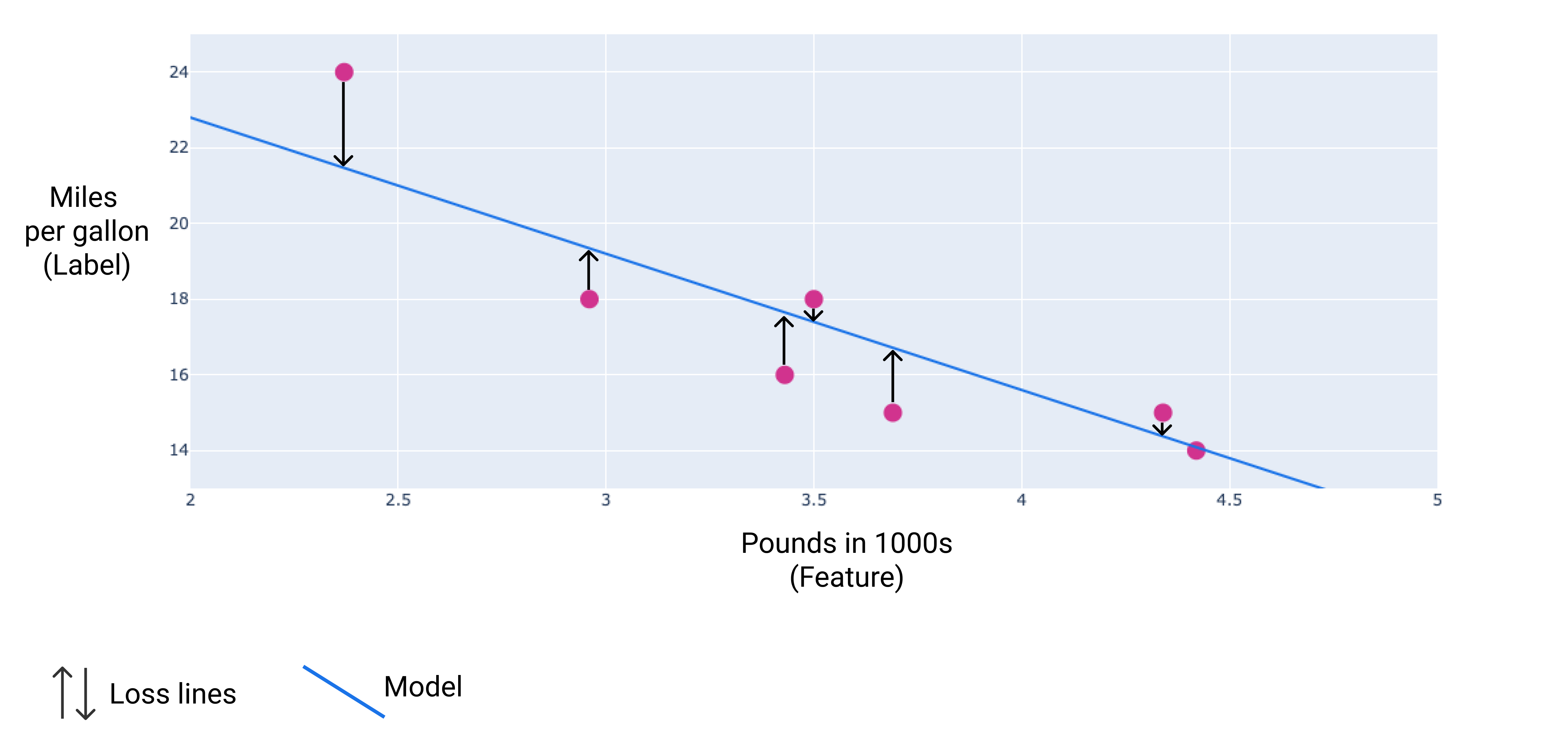
Rysunek 8. Utrata jest mierzona od wartości rzeczywistej do wartości przewidywanej.
Odległość utraty
W statystyce i uczeniu maszynowym funkcja straty mierzy różnicę między wartościami prognozowanymi a rzeczywistymi. Funkcja straty koncentruje się na odległości między wartościami, a nie na kierunku. Jeśli na przykład model przewiduje wartość 2, ale rzeczywista wartość to 5, nie ma znaczenia, że strata jest ujemna (2 – 5= –3). Zamiast tego zależy nam na tym, aby odległość między wartościami wynosiła 3. Dlatego wszystkie metody obliczania straty usuwają znak.
Oto 2 najczęstsze metody usuwania znaku:
- Oblicz wartość bezwzględną różnicy między wartością rzeczywistą a prognozą.
- Podnieś do kwadratu różnicę między wartością rzeczywistą a prognozą.
Rodzaje strat
W regresji liniowej występuje 5 głównych rodzajów funkcji straty, które zostały opisane w tej tabeli.
| Typ straty | Definicja | Równanie |
|---|---|---|
| Utrata sygnału L1 | Suma wartości bezwzględnych różnicy między prognozowanymi a rzeczywistymi wartościami. | $ ∑ | actual\ value - predicted\ value | $ |
| Średni błąd bezwzględny (MAE) | Średnia strat L1 w zbiorze N przykładów. | $ \frac{1}{N} ∑ | actual\ value - predicted\ value | $ |
| Utrata L2 | Suma kwadratów różnic między prognozowanymi a rzeczywistymi wartościami. | $ ∑(wartość\ rzeczywista - wartość\ przewidywana)^2 $ |
| Błąd średniokwadratowy (MSE) | Średnia strat L2 w przypadku zbioru N przykładów. | $ \frac{1}{N} ∑ (rzeczywista\ wartość - przewidywana\ wartość)^2 $ |
| Średnia kwadratowa błędów (RMSE) | Pierwiastek kwadratowy z błędu średniokwadratowego (MSE). | $ \sqrt{\frac{1}{N} ∑ (actual\ value - predicted\ value)^2} $ |
Różnica funkcjonalna między funkcją straty L1 a funkcją straty L2 (lub między MAE/RMSE a MSE) polega na podnoszeniu do kwadratu. Gdy różnica między prognozą a etykietą jest duża, podniesienie do kwadratu jeszcze bardziej zwiększa stratę. Gdy różnica jest niewielka (mniejsza niż 1), podniesienie do kwadratu jeszcze bardziej zmniejsza stratę.
W niektórych przypadkach użycia wskaźniki utraty, takie jak MAE i RMSE, mogą być lepsze niż utrata L2 lub MSE, ponieważ są bardziej zrozumiałe dla człowieka. Mierzą one błąd w tej samej skali co przewidywana wartość modelu.
Podczas przetwarzania wielu przykładów naraz zalecamy uśrednianie strat we wszystkich przykładach, niezależnie od tego, czy używasz MAE, MSE czy RMSE.
Przykład obliczania strat
W poprzedniej sekcji utworzyliśmy ten model, aby prognozować zużycie paliwa na podstawie wagi samochodu:
- Model: $ y' = 34 + (-4.6)(x_1) $
- Waga: $ –4,6 $
- Odchylenie: 34 PLN
Jeśli model przewiduje, że samochód o masie 2370 funtów zużywa 23,1 mili na galon, a w rzeczywistości zużywa 24 mile na galon, stratę L2 obliczymy w ten sposób:
| Wartość | Równanie | Wynik |
|---|---|---|
| Prognoza | $\small{bias + (weight * feature\ value)}$ $\small{34 + (-4.6*2.37)}$ |
$\small{23.1}$ |
| Rzeczywista wartość | $ \small{ label } $ | $ \small{ 24 } $ |
| Funkcja straty L2 | $ \small{ (wartość\ rzeczywista - wartość\ przewidywana)^2 } $ $\small{ (24 - 23.1)^2 }$ |
$\small{0,81}$ |
W tym przykładzie strata L2 dla tego pojedynczego punktu danych wynosi 0, 81.
Wybór straty
Decyzja o użyciu MAE lub MSE może zależeć od zbioru danych i sposobu, w jaki chcesz traktować określone prognozy. Większość wartości cech w zbiorze danych zwykle mieści się w określonym zakresie. Na przykład samochody ważą zwykle od 2000 do 5000 funtów i przejeżdżają od 8 do 50 mil na galon. Samochód o masie 8000 funtów lub taki, który przejeżdża 100 mil na galonie, wykracza poza typowy zakres i zostałby uznany za wartość odstającą.
Wartość odstająca może też odnosić się do tego, jak bardzo prognozy modelu odbiegają od rzeczywistych wartości. Na przykład 3000 funtów mieści się w typowym zakresie wagi samochodu, a 40 mil na galon mieści się w typowym zakresie zużycia paliwa. Jednak samochód o wadze 3000 funtów, który przejeżdża 40 mil na galonie, byłby wartością odstającą w prognozie modelu, ponieważ model przewidywałby, że samochód o wadze 3000 funtów przejeżdża około 20 mil na galonie.
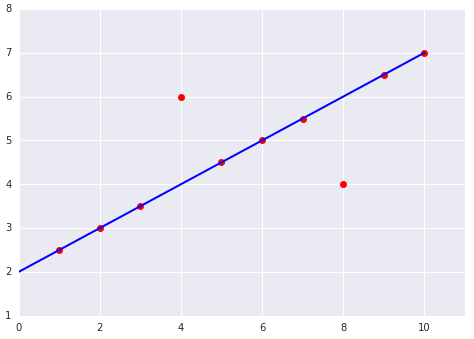
Wybierając najlepszą funkcję straty, zastanów się, jak chcesz, aby model traktował wartości odstające. Na przykład MSE przesuwa model w stronę wartości odstających, a MAE nie. Funkcja straty L2 nakłada na wartość odstającą znacznie większą karę niż funkcja straty L1. Na przykład poniższe obrazy przedstawiają model wytrenowany przy użyciu MAE i model wytrenowany przy użyciu MSE. Czerwona linia reprezentuje w pełni wytrenowany model, który będzie używany do tworzenia prognoz. Wartości odstające są bliższe modelowi wytrenowanemu za pomocą MSE niż modelowi wytrenowanemu za pomocą MAE.
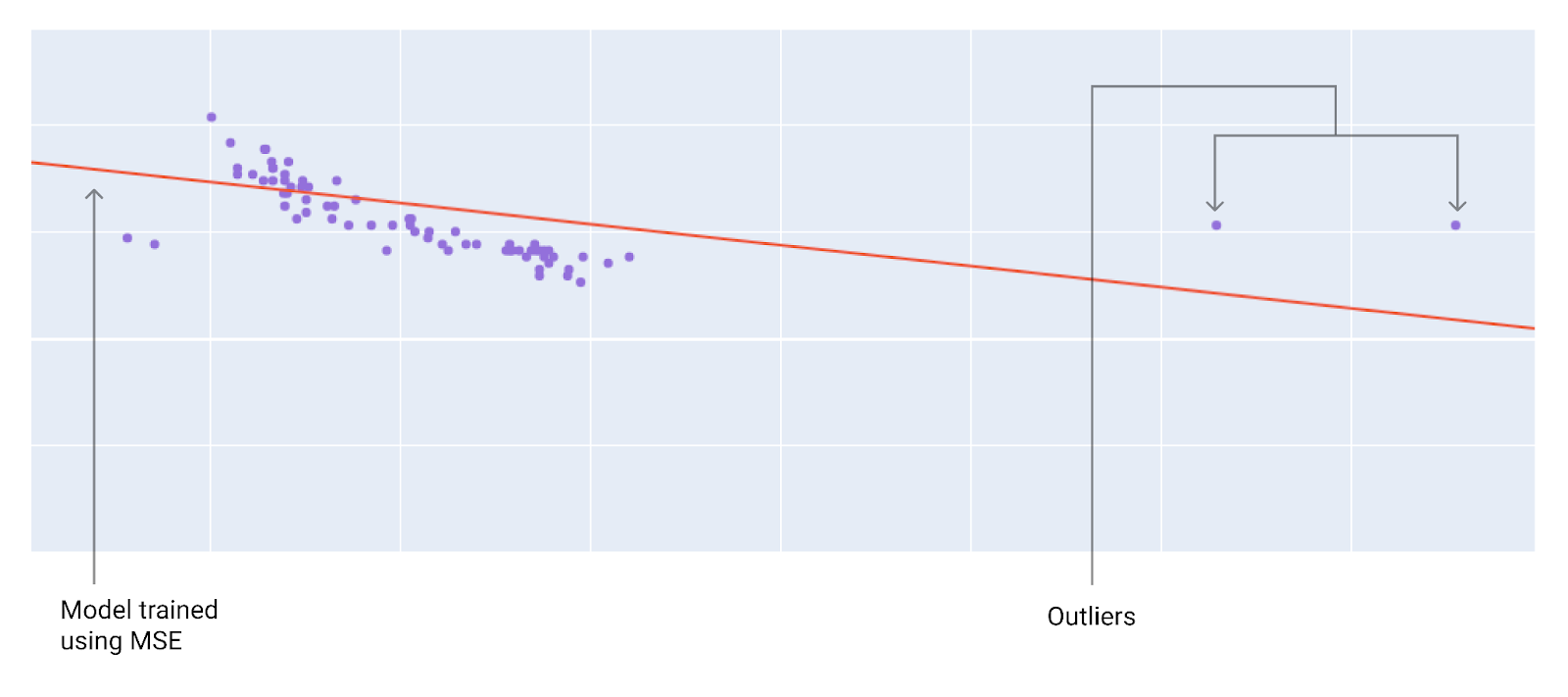
Rysunek 9. Funkcja straty MSE przybliża model do wartości odstających.
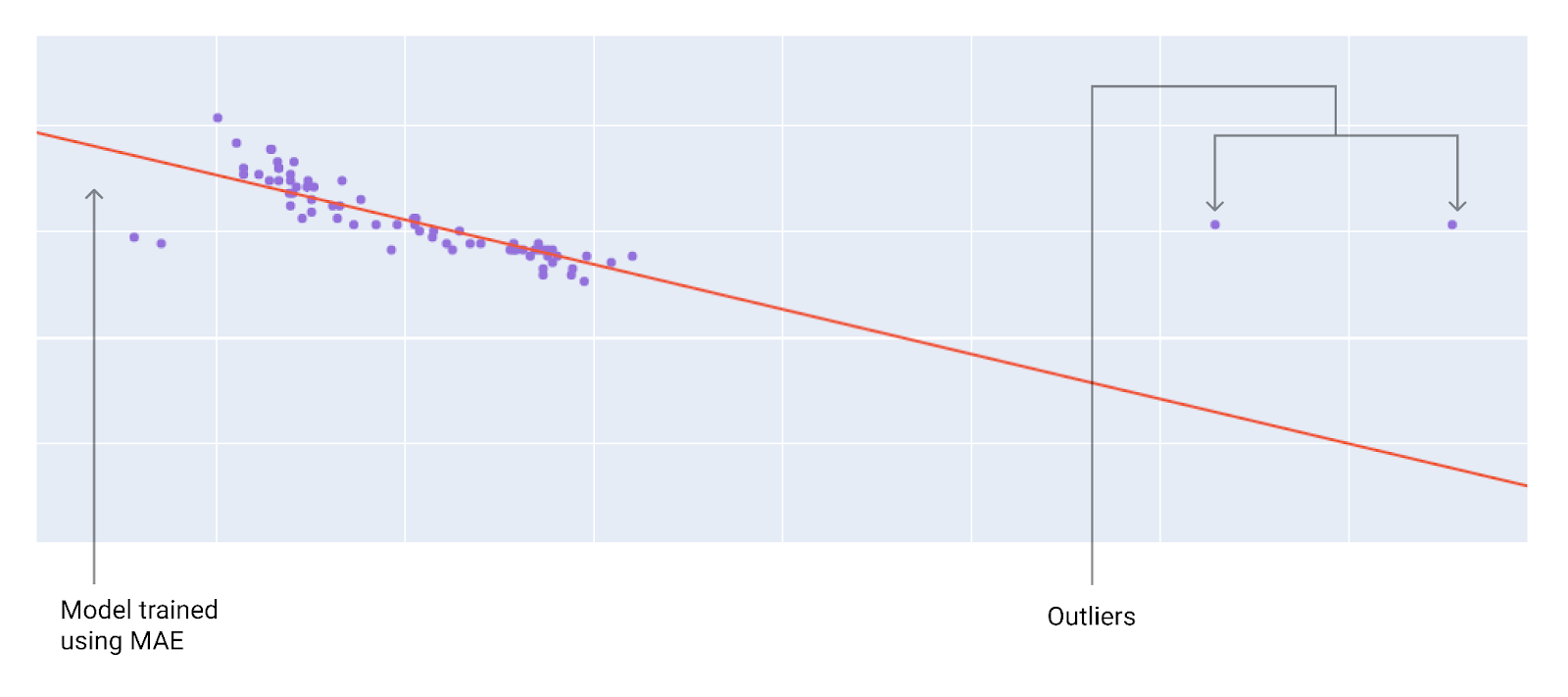
Rysunek 10. Funkcja straty MAE utrzymuje model z dala od wartości odstających.
Zwróć uwagę na relację między modelem a danymi:
MSE Model jest bliżej wartości odstających, ale dalej od większości pozostałych punktów danych.
MAE Model jest bardziej oddalony od wartości odstających, ale bliżej większości pozostałych punktów danych.
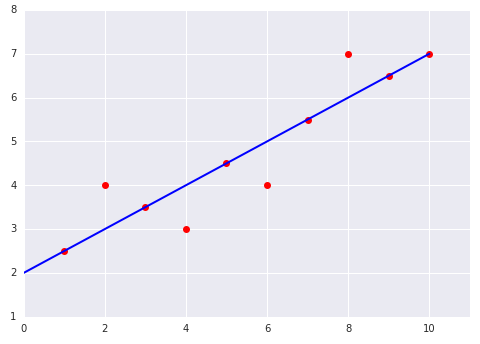
Sprawdź swoją wiedzę
Rozważmy te 2 wykresy modelu liniowego dopasowanego do zbioru danych:
|
|