손실은 모델의 예측이 얼마나 잘못되었는지를 설명하는 수치 측정항목입니다. 손실은 모델의 예측과 실제 라벨 간의 거리를 측정합니다. 모델 학습의 목표는 손실을 최소화하여 가능한 가장 낮은 값으로 줄이는 것입니다.
다음 이미지에서 데이터 포인트에서 모델로 그려진 화살표로 손실을 시각화할 수 있습니다. 화살표는 모델의 예측이 실제 값과 얼마나 차이가 나는지 보여줍니다.
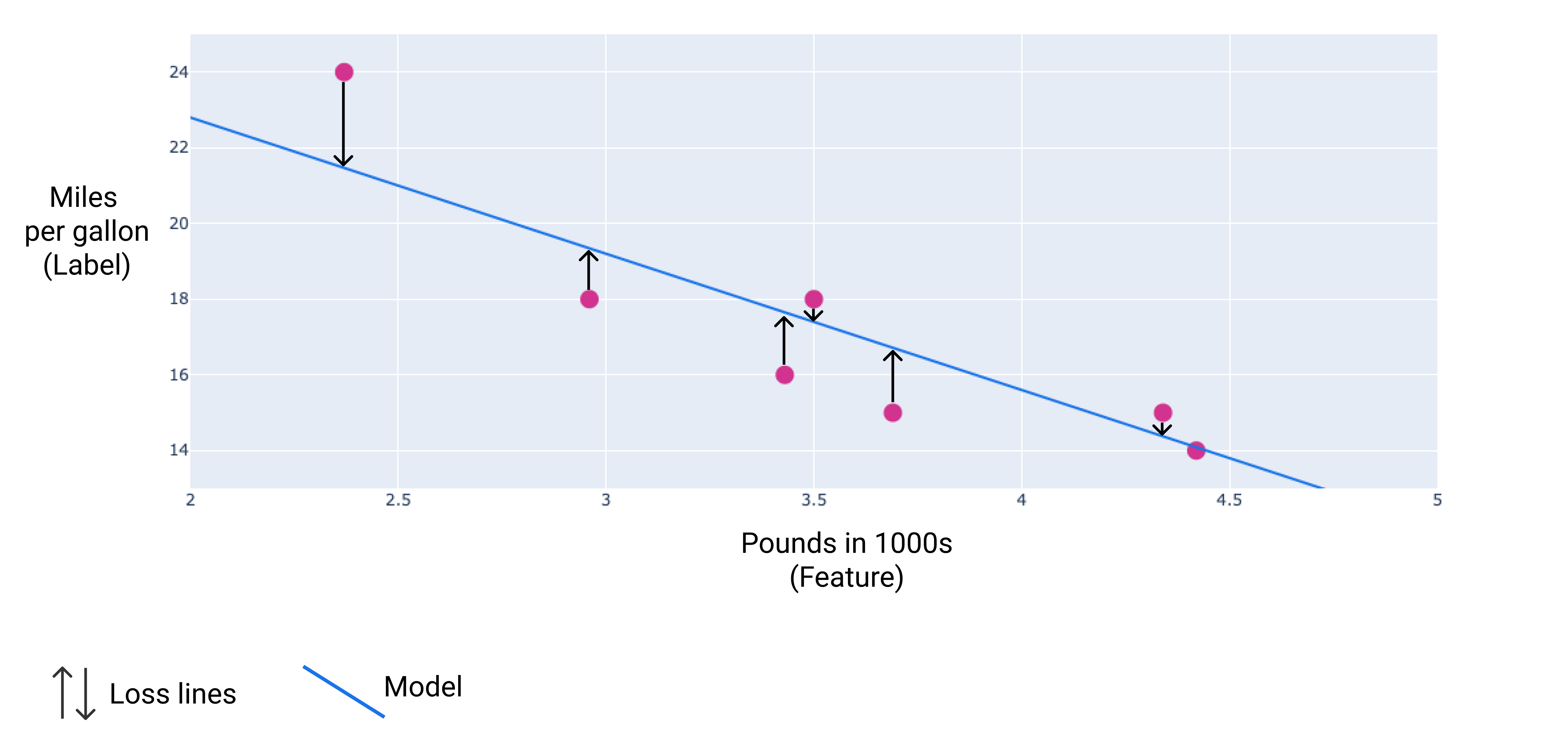
그림 8. 손실은 실제 값에서 예측 값으로 측정됩니다.
손실 거리
통계 및 머신러닝에서 손실은 예측값과 실제 값 간의 차이를 측정합니다. 손실은 방향이 아닌 값 간의 거리에 중점을 둡니다. 예를 들어 모델이 2를 예측했지만 실제 값은 5인 경우 손실이 음수 (2~5=-3)인지는 중요하지 않습니다. 대신 값 사이의 거리가 3인지 확인합니다. 따라서 손실을 계산하는 모든 메서드는 부호를 삭제합니다.
표시를 삭제하는 가장 일반적인 두 가지 방법은 다음과 같습니다.
- 실제 값과 예측 값의 차이의 절대값을 취합니다.
- 실제 값과 예측값의 차이를 제곱합니다.
손실 유형
선형 회귀에는 다음 표에 설명된 5가지 주요 손실 유형이 있습니다.
| 손실 유형 | 정의 | 등식 |
|---|---|---|
| L1 손실 | 예측값과 실제 값 간 차이의 절대값의 합계입니다. | $ ∑ | 실제값 - 예측값 | $ |
| 평균 절대 오차 (MAE) | N개의 예시 집합에서 L1 손실의 평균입니다. | $ \frac{1}{N} ∑ | 실제\ 값 - 예측\ 값 | $ |
| L2 손실 | 예측값과 실제 값 간 제곱 차이의 합계입니다. | $ ∑(실제\ 값 - 예측\ 값)^2 $ |
| 평균 제곱 오차 (MSE) | N개의 예시 집합에 걸친 L2 손실의 평균입니다. | $ \frac{1}{N} ∑ (실제\ 값 - 예측\ 값)^2 $ |
| 평균 제곱근 오차 (RMSE) | 평균 제곱 오차 (MSE)의 제곱근입니다. | $ \sqrt{\frac{1}{N} ∑ (실제\ 값 - 예측\ 값)^2} $ |
L1 손실과 L2 손실(또는 MAE/RMSE와 MSE) 간의 기능적 차이는 제곱입니다. 예측과 라벨 간의 차이가 클 때 제곱하면 손실이 훨씬 커집니다. 차이가 작으면 (1 미만) 제곱하면 손실이 더 작아집니다.
MAE 및 RMSE와 같은 손실 측정항목은 모델의 예측 값과 동일한 스케일을 사용하여 오류를 측정하므로 일부 사용 사례에서는 L2 손실 또는 MSE보다 더 선호될 수 있습니다.
MAE, MSE, RMSE 중 무엇을 사용하든 한 번에 여러 예시를 처리할 때는 모든 예시에서 손실을 평균하는 것이 좋습니다.
손실 계산 예
이전 섹션에서는 자동차 중량에 따라 연비를 예측하는 다음 모델을 만들었습니다.
- 모델: $ y' = 34 + (-4.6)(x_1) $
- 가중치: $ –4.6 $
- 편향: $ 34 $
모델에서 2,370파운드 자동차의 연비를 갤런당 23.1마일로 예측했지만 실제 연비가 갤런당 24마일인 경우 L2 손실은 다음과 같이 계산됩니다.
| 값 | 등식 | 결과 |
|---|---|---|
| 예측 | $\small{bias + (weight * feature\ value)}$ $\small{34 + (-4.6*2.37)}$ |
$\small{23.1}$ |
| 실제 금액 | $ \small{ label } $ | $ \small{ 24 } $ |
| L2 손실 | $ \small{ (실제\ 값 - 예측\ 값)^2 } $ $\small{ (24 - 23.1)^2 }$ |
$\small{0.81}$ |
이 예에서 해당 단일 데이터 포인트의 L2 손실은 0.81입니다.
손실 선택
MAE 또는 MSE 사용 여부는 데이터 세트와 특정 예측을 처리하는 방식에 따라 달라질 수 있습니다. 데이터 세트의 대부분의 특성 값은 일반적으로 고유한 범위에 속합니다. 예를 들어 자동차는 일반적으로 2,000~5,000파운드이며 갤런당 8~50마일을 주행합니다. 8,000파운드 자동차나 갤런당 100마일을 주행하는 자동차는 일반적인 범위를 벗어나므로 이상치로 간주됩니다.
이상치는 모델의 예측이 실제 값에서 얼마나 벗어났는지를 나타낼 수도 있습니다. 예를 들어 3,000파운드는 일반적인 자동차 무게 범위에 속하고 갤런당 40마일은 일반적인 연비 범위에 속합니다. 하지만 갤런당 40마일을 주행하는 3,000파운드 자동차는 모델의 예측 측면에서 이상치입니다. 모델은 3,000파운드 자동차가 갤런당 약 20마일을 주행할 것으로 예측하기 때문입니다.
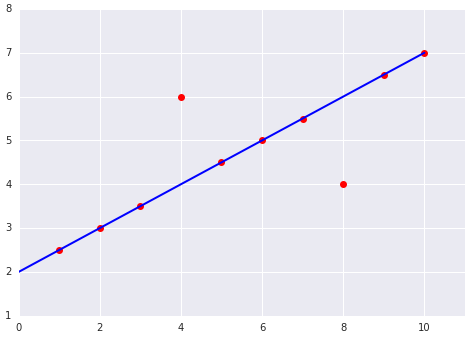
최적의 손실 함수를 선택할 때는 모델이 이상치를 어떻게 처리해야 하는지 고려하세요. 예를 들어 MSE는 모델을 이상치에 더 가깝게 이동하는 반면 MAE는 그렇지 않습니다. L2 손실은 L1 손실보다 이상치에 훨씬 높은 페널티를 적용합니다. 예를 들어 다음 이미지는 MAE를 사용하여 학습된 모델과 MSE를 사용하여 학습된 모델을 보여줍니다. 빨간색 선은 예측을 수행하는 데 사용되는 완전히 학습된 모델을 나타냅니다. 이상치는 MAE로 학습된 모델보다 MSE로 학습된 모델에 더 가깝습니다.
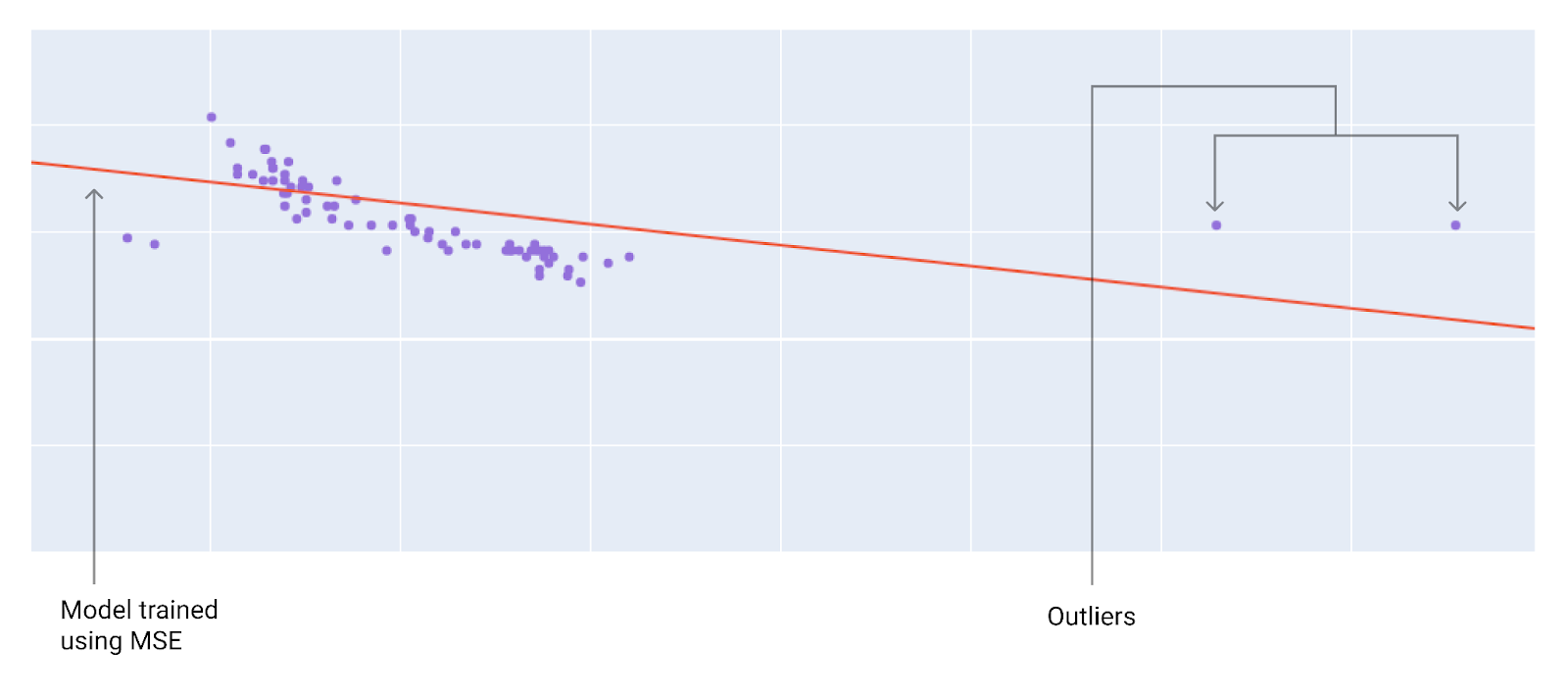
그림 9. MSE 손실은 모델을 이상치에 더 가깝게 이동시킵니다.
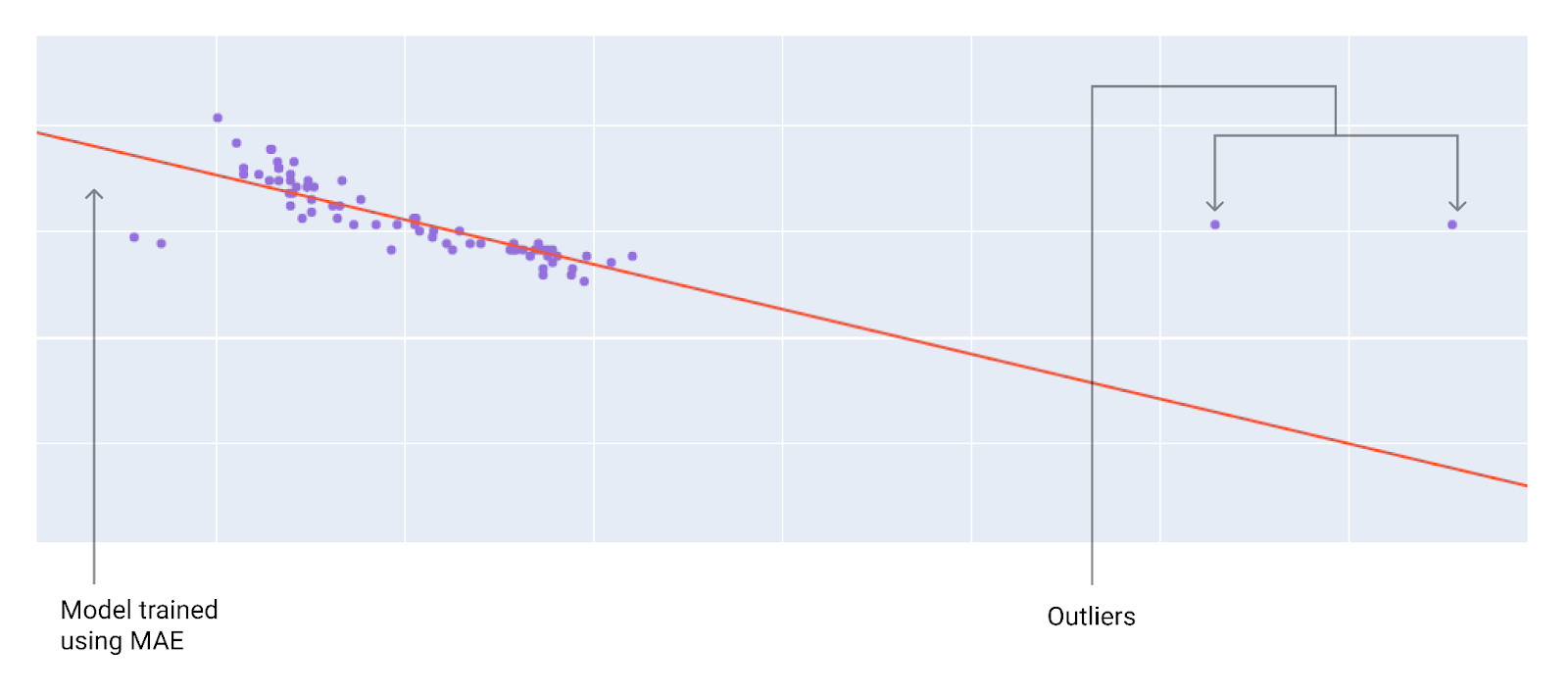
그림 10. MAE 손실은 모델을 이상치에서 더 멀리 유지합니다.
모델과 데이터 간의 관계를 참고하세요.
MSE. 모델이 이상치에 더 가깝지만 다른 대부분의 데이터 포인트와는 더 멀리 떨어져 있습니다.
MAE 모델이 이상치에서 더 멀리 떨어져 있지만 대부분의 다른 데이터 포인트에 더 가깝습니다.
이해도 확인
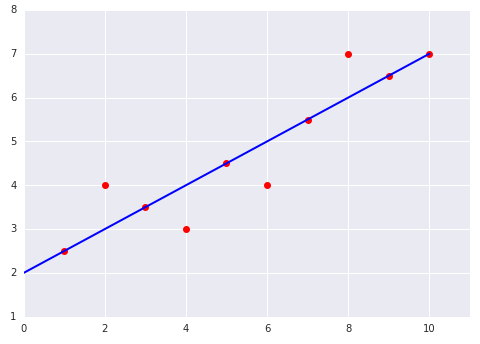
데이터 세트에 적합한 선형 모델의 다음 두 플롯을 살펴보세요.
|
|