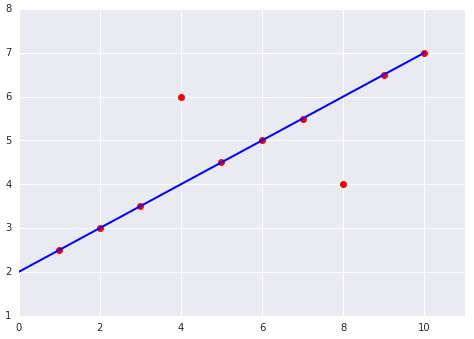
الخسارة هي مقياس رقمي يصف مدى خطأ توقّعات النموذج. تقيس دالة الخسارة المسافة بين التوقعات التي يقدّمها النموذج والتصنيفات الفعلية. والهدف من تدريب النموذج هو تقليل الخسارة إلى أدنى قيمة ممكنة.
في الصورة التالية، يمكنك تصوّر الخسارة على شكل أسهم مرسومة من نقاط البيانات إلى النموذج. توضّح الأسهم مدى بُعد التوقّعات التي يقدّمها النموذج عن القيم الفعلية.
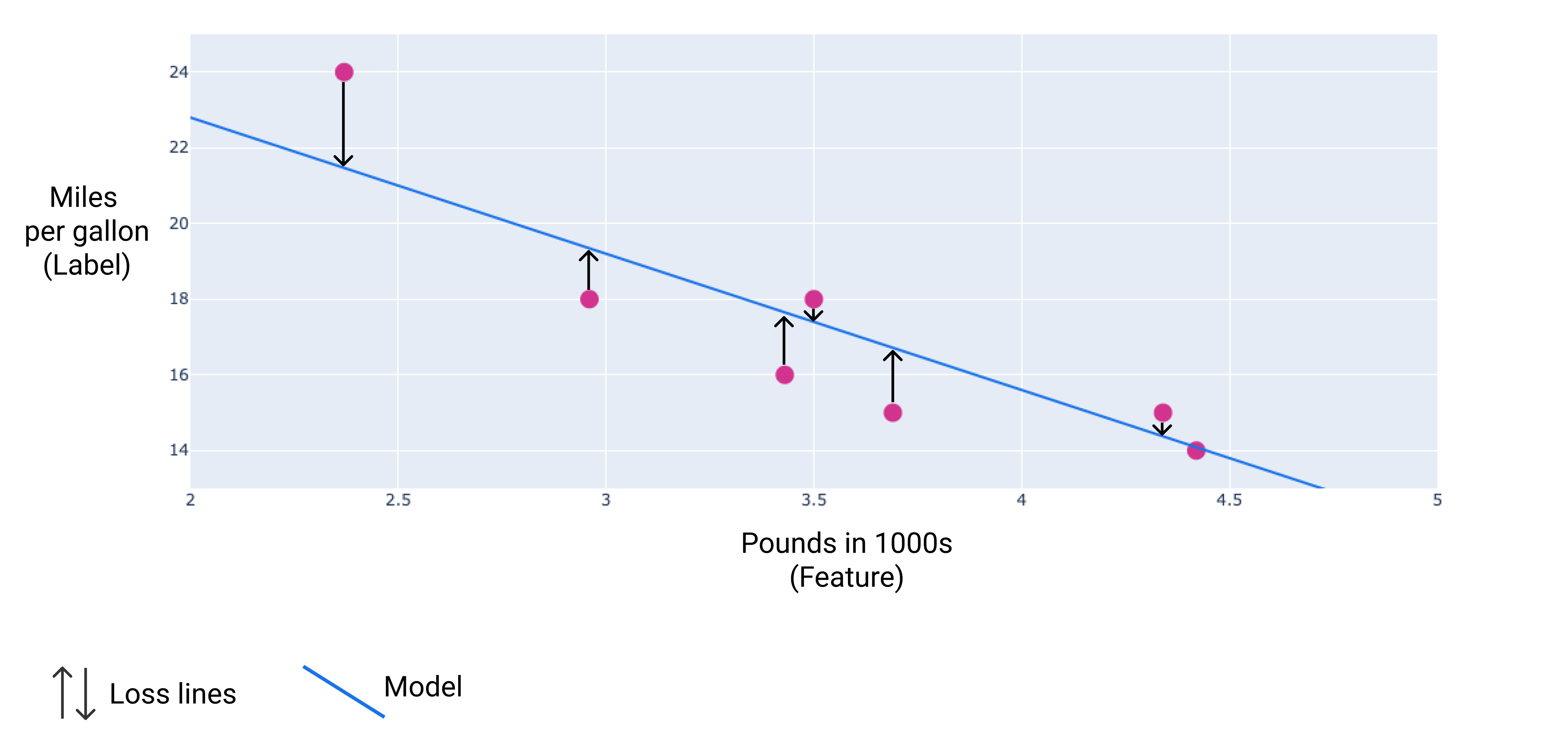
الشكل 8 يتم قياس الخسارة من القيمة الفعلية إلى القيمة المتوقّعة.
مسافة الفقدان
في الإحصاء وتعلُّم الآلة، يقيس مقياس الخسارة الفرق بين القيم المتوقّعة والفعلية. يركّز مقياس الخسارة على المسافة بين القيم، وليس على الاتجاه. على سبيل المثال، إذا توقّع نموذج القيمة 2، ولكن القيمة الفعلية هي 5، لا يهمّنا أن تكون الخسارة سالبة (2 – 5 = -3). بدلاً من ذلك، يهمّنا أن تكون المسافة بين القيم 3. وبالتالي، فإنّ جميع طرق حساب الخسارة تزيل الإشارة.
في ما يلي الطريقتان الأكثر شيوعًا لإزالة العلامة:
- يتم احتساب القيمة المطلقة للفرق بين القيمة الفعلية والقيمة المتوقّعة.
- ربِّع الفرق بين القيمة الفعلية والقيمة المتوقّعة.
أنواع الخسارة
في الانحدار الخطي، هناك خمسة أنواع رئيسية من الخسائر، وهي موضّحة في الجدول التالي.
| نوع الخسارة | التعريف | معادلة |
|---|---|---|
| فقدان1 | يشير ذلك المصطلح إلى مجموع القيم المطلقة للفرق بين القيم المتوقَّعة والقيم الفعلية. | $ ∑ | actual\ value - predicted\ value | $ |
| متوسّط الخطأ المطلق (MAE) | متوسط خسائر L1 على مجموعة من N الأمثلة | $ \frac{1}{N} ∑ | actual\ value - predicted\ value | $ |
| فقدان L2 | يشير ذلك المصطلح إلى مجموع الفَرق التربيعي بين القيم المتوقَّعة والقيم الفعلية. | $ ∑(actual\ value - predicted\ value)^2 $ |
| الخطأ التربيعي المتوسّط (MSE) | متوسط خسائر L2 على مجموعة من N الأمثلة | $ \frac{1}{N} ∑ (actual\ value - predicted\ value)^2 $ |
| جذر الخطأ التربيعي المتوسّط (RMSE) | الجذر التربيعي لمتوسط الخطأ التربيعي (MSE) | $ \sqrt{\frac{1}{N} ∑ (actual\ value - predicted\ value)^2} $ |
الفرق الوظيفي بين خسارة L1 وخسارة L2 (أو بين MAE/RMSE وMSE) هو التربيع. عندما يكون الفرق بين التوقّع والتصنيف كبيرًا، يؤدي التربيع إلى زيادة الخسارة. عندما يكون الفرق صغيرًا (أقل من 1)، يؤدي التربيع إلى تقليل الخسارة.
قد تكون مقاييس الخسارة، مثل MAE وRMSE، أفضل من خسارة L2 أو MSE في بعض حالات الاستخدام لأنّها تميل إلى أن تكون أكثر قابلية للتفسير من قِبل الإنسان، إذ إنّها تقيس الخطأ باستخدام المقياس نفسه الذي تستخدمه القيمة المتوقّعة للنموذج.
عند معالجة أمثلة متعددة في الوقت نفسه، ننصحك بحساب متوسط الخسائر على مستوى جميع الأمثلة، سواء كنت تستخدم MAE أو MSE أو RMSE.
مثال على احتساب الخسارة
في القسم السابق، أنشأنا النموذج التالي للتنبؤ بكفاءة استهلاك الوقود استنادًا إلى وزن السيارة:
- النموذج: $ y' = 34 + (-4.6)(x_1) $
- الوزن: $ –4.6 $
- التحيز: $ 34 $
إذا توقّع النموذج أنّ سيارة تزن 2,370 رطلاً ستقطع 23.1 ميلاً لكل غالون، ولكنها في الواقع تقطع 24 ميلاً لكل غالون، سنحسب خسارة L2 على النحو التالي:
| القيمة | معادلة | النتيجة |
|---|---|---|
| التوقّع | $\small{bias + (weight * feature\ value)}$ $\small{34 + (-4.6*2.37)}$ |
$\small{23.1}$ |
| القيمة الفعلية | $ \small{ label } $ | $ \small{ 24 } $ |
| خسارة 2 | $ \small{ (actual\ value - predicted\ value)^2 } $ $\small{ (24 - 23.1)^2 }$ |
$\small{0.81}$ |
في هذا المثال، تبلغ خسارة L2 لنقطة البيانات الفردية هذه 0.81.
اختيار خسارة
يمكن أن يعتمد قرار استخدام MAE أو MSE على مجموعة البيانات والطريقة التي تريد بها التعامل مع بعض التوقعات. عادةً ما تندرج معظم قيم الميزات في مجموعة البيانات ضمن نطاق مميّز. على سبيل المثال، يتراوح وزن السيارات عادةً بين 2000 و5000 رطل، وتستهلك ما بين 8 و50 ميلاً لكل غالون. تُعتبر السيارة التي يبلغ وزنها 8,000 رطل أو السيارة التي تقطع 100 ميل لكل غالون قيمة متطرفة لأنّها خارج النطاق المعتاد.
يمكن أن يشير المصطلح "قيمة متطرفة" أيضًا إلى مدى اختلاف توقّعات النموذج عن القيم الحقيقية. على سبيل المثال، يقع وزن 3,000 رطل ضمن نطاق وزن السيارة العادي، كما أنّ 40 ميلاً لكل غالون يقع ضمن نطاق كفاءة استهلاك الوقود العادي. في المقابل، ستكون السيارة التي يبلغ وزنها 3,000 رطل وتستهلك 40 ميلاً لكل غالون أمريكية قيمة متطرفة في ما يتعلق بتوقّعات النموذج، لأنّ النموذج سيتوقّع أنّ السيارة التي يبلغ وزنها 3,000 رطل ستستهلك حوالي 20 ميلاً لكل غالون أمريكية.
عند اختيار أفضل دالة خسارة، يجب مراعاة الطريقة التي تريد أن يتعامل بها النموذج مع القيم الشاذة. على سبيل المثال، يؤدي MSE إلى توجيه النموذج نحو القيم الشاذة، بينما لا يؤدي MAE إلى ذلك. يؤدي فقدان حزمة L2 إلى فرض عقوبة أكبر بكثير على القيم الشاذة مقارنةً بفقدان حزمة L1. على سبيل المثال، تعرض الصور التالية نموذجًا تم تدريبه باستخدام MAE ونموذجًا تم تدريبه باستخدام MSE. يمثّل الخط الأحمر نموذجًا تم تدريبه بالكامل وسيتم استخدامه لتقديم التوقعات. تكون القيم الشاذة أقرب إلى النموذج المدرَّب باستخدام متوسط الخطأ التربيعي (MSE) مقارنةً بالنموذج المدرَّب باستخدام متوسط الخطأ المطلق (MAE).
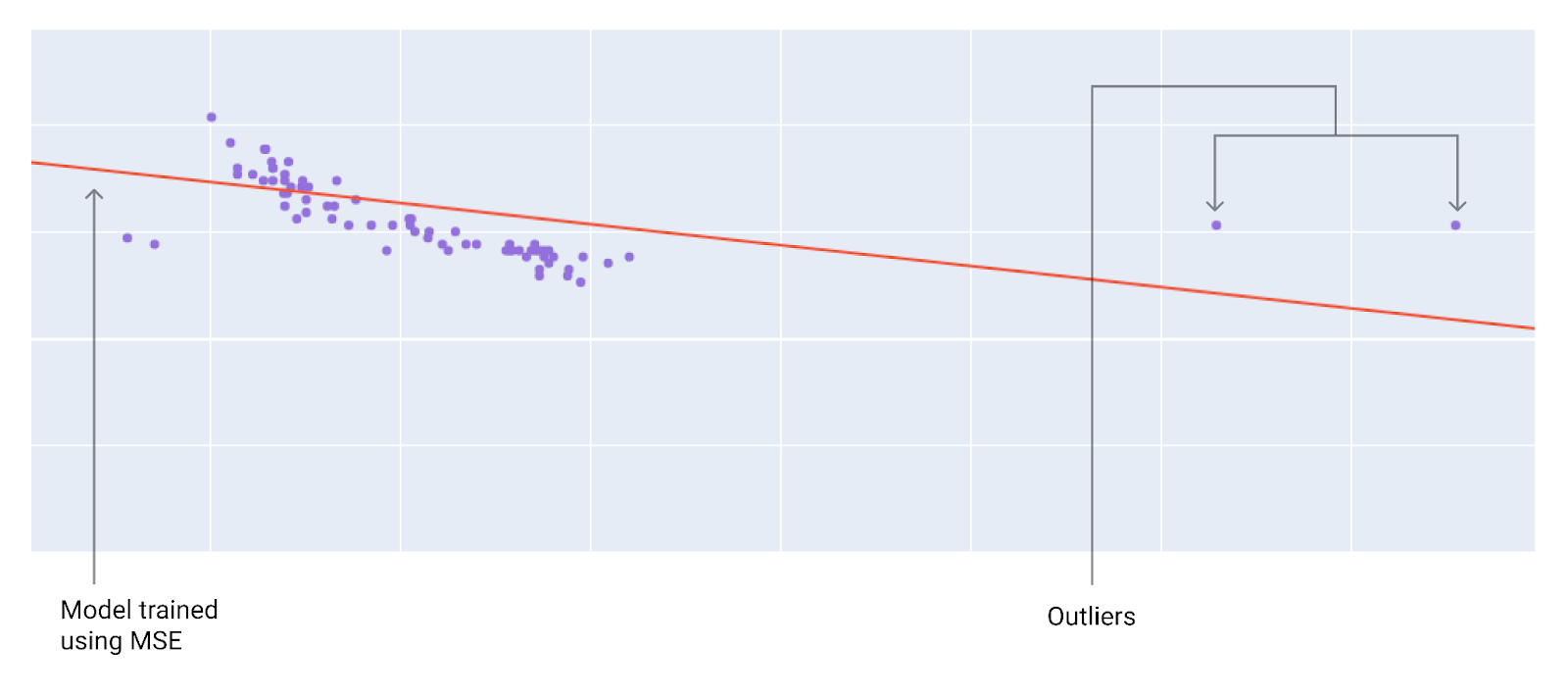
الشكل 9 يؤدي فقدان MSE إلى تقريب النموذج من القيم الشاذة.
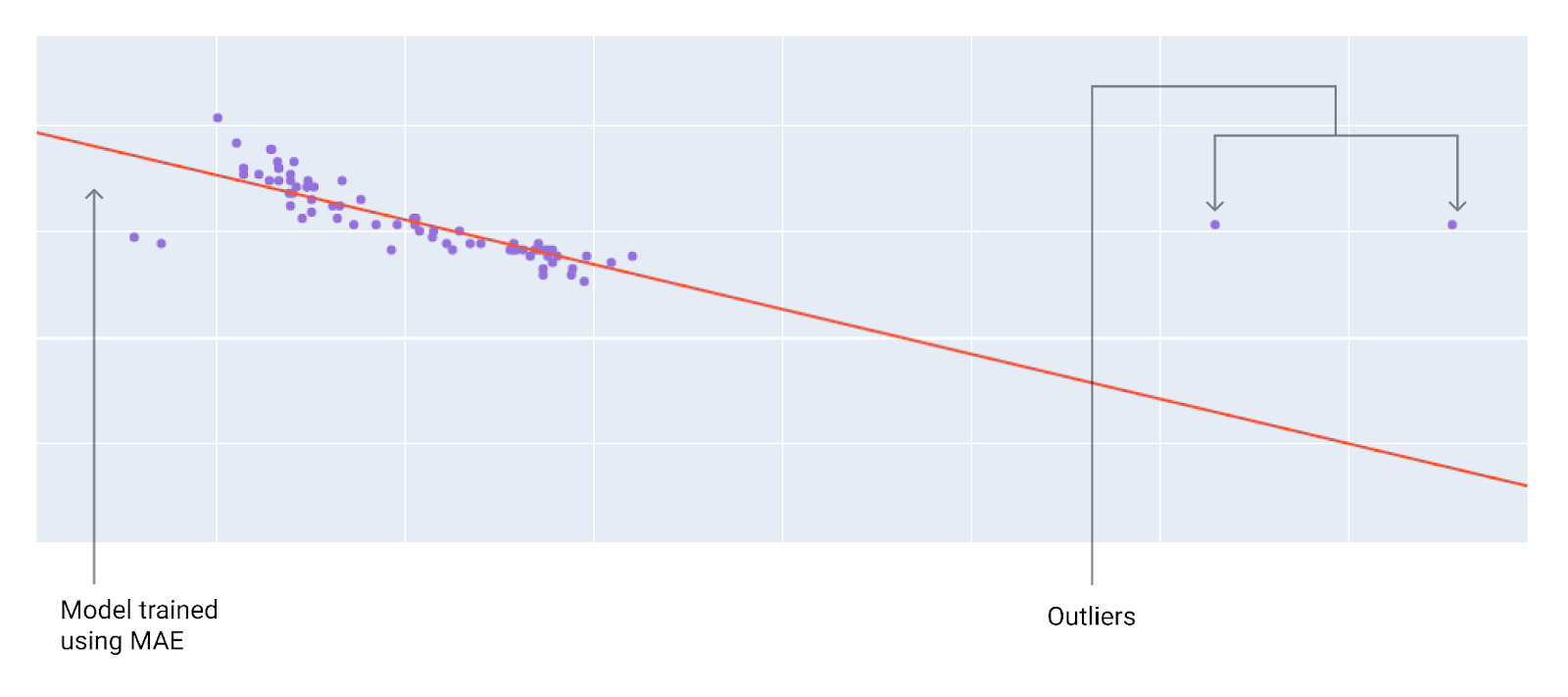
الشكل 10 يُبقي مقياس MAE النموذج بعيدًا عن القيم الشاذة.
لاحظ العلاقة بين النموذج والبيانات:
MSE يكون النموذج أقرب إلى القيم الشاذة وأبعد عن معظم نقاط البيانات الأخرى.
MAE يكون النموذج أبعد عن القيم الشاذة ولكنه أقرب إلى معظم نقاط البيانات الأخرى.
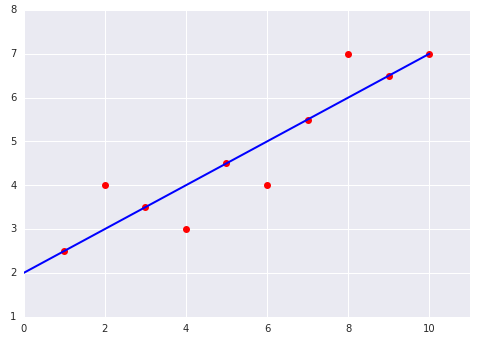
التحقّق من فهمك
ضَع في اعتبارك الرسمَين البيانيَّين التاليَين لنموذج خطي مناسب لمجموعة بيانات:
|
|