本單元將介紹線性迴歸概念。
線性迴歸是一種統計技術,用於找出變數之間的關係。在機器學習環境中,線性迴歸會找出特徵與標籤之間的關係。
舉例來說,假設我們想根據車輛重量預測車輛的燃油效率 (以每加侖行駛的英里數為單位),並有以下資料集:
| 以千為單位的磅數 (功能) | 每加侖英里數 (標籤) |
|---|---|
| 3.5 | 18 |
| 3.69 | 15 |
| 3.44 | 18 |
| 3.43 | 16 |
| 4.34 | 15 |
| 4.42 | 14 |
| 2.37 | 24 |
如果我們繪製這些點,會得到下列圖表:
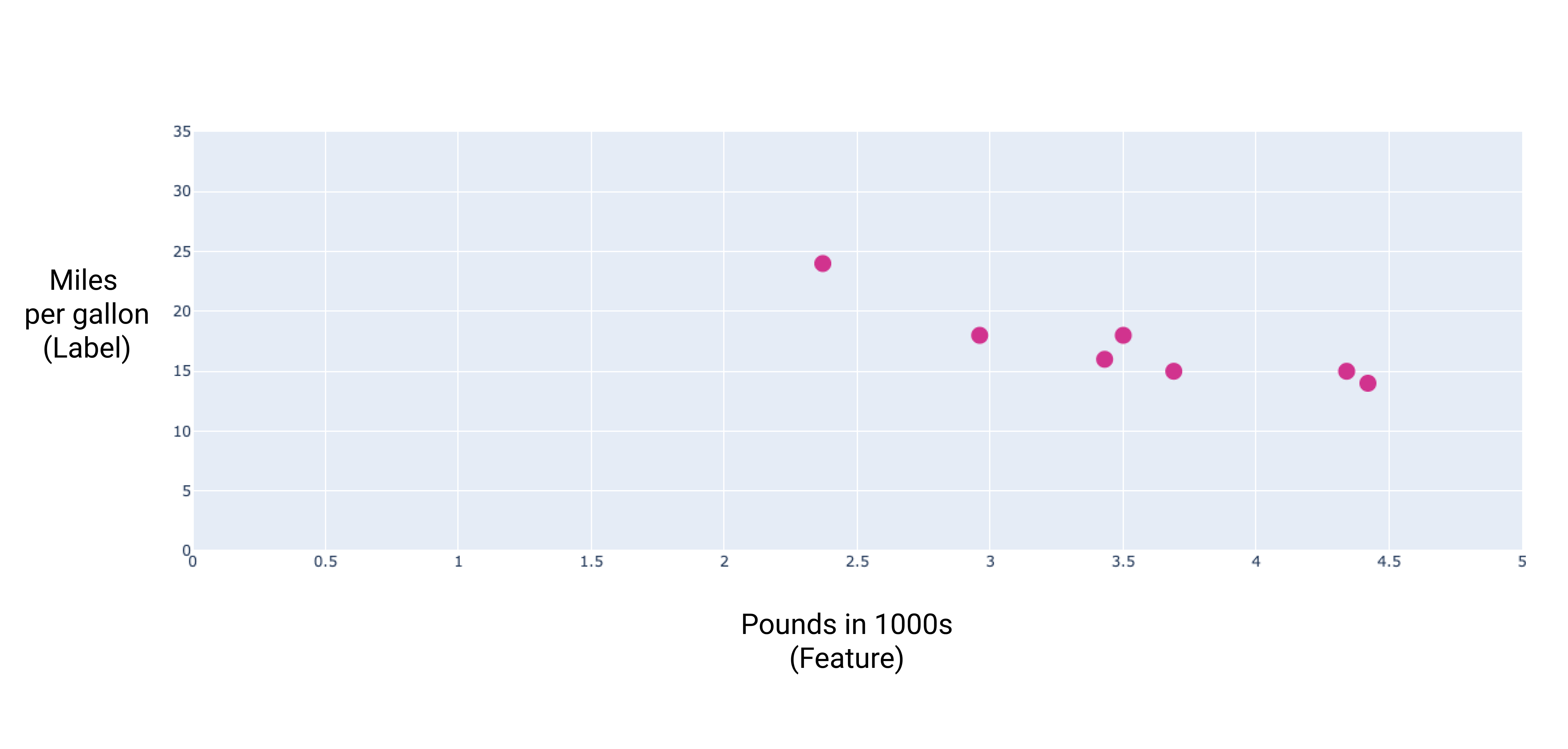
圖 1. 車輛重量 (磅) 與每加侖英里數評等。車輛越重,每加侖汽油行駛里程的評等通常會越低。
我們可以透過在點之間繪製最佳配適線,建立自己的模型:
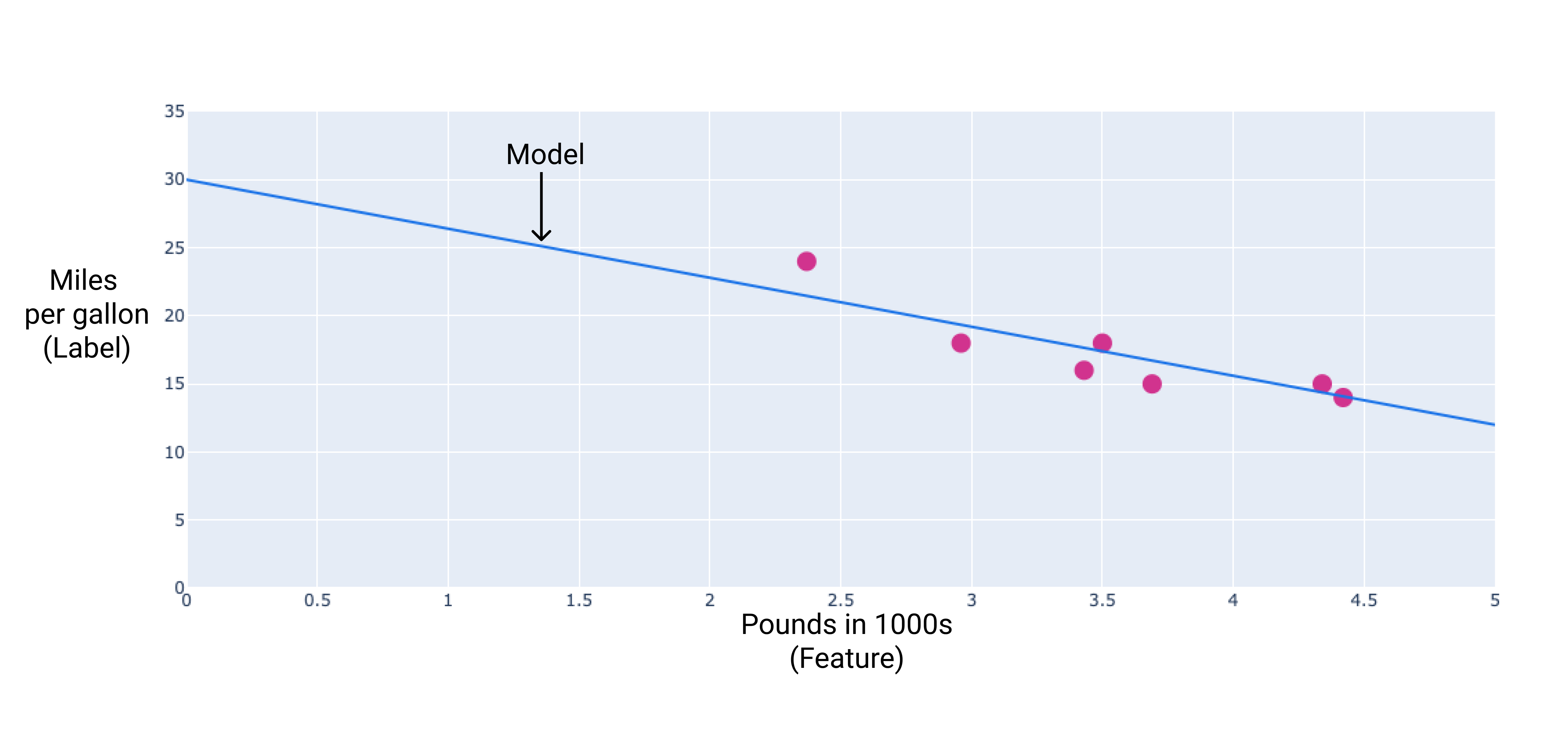
圖 2. 透過上圖資料繪製的最佳配適線。
線性迴歸方程式
以代數來說,模型會定義為 $ y = mx + b $,其中
- $ y $ 是每加侖汽油可跑的英里數,也就是我們想預測的值。
- $ m $ 是直線的斜率。
- $ x $ 是磅,也就是輸入值。
- $ b $ 是 y 截距。
在機器學習中,線性迴歸模型的方程式如下:
其中:
- $ y' $ 是預測標籤,也就是輸出內容。
- $ b $ 是模型的偏差。偏差與直線代數方程式中的 y 截距概念相同。在機器學習中,偏誤有時稱為 $ w_0 $。偏誤是模型的參數,會在訓練期間計算。
- $ w_1 $ 是特徵的權重。權重與代數方程式中直線的斜率 $ m $ 概念相同。權重是模型的參數,會在訓練期間計算。
- $ x_1 $ 是特徵,也就是輸入內容。
在訓練期間,模型會計算產生最佳模型的權重和偏差。
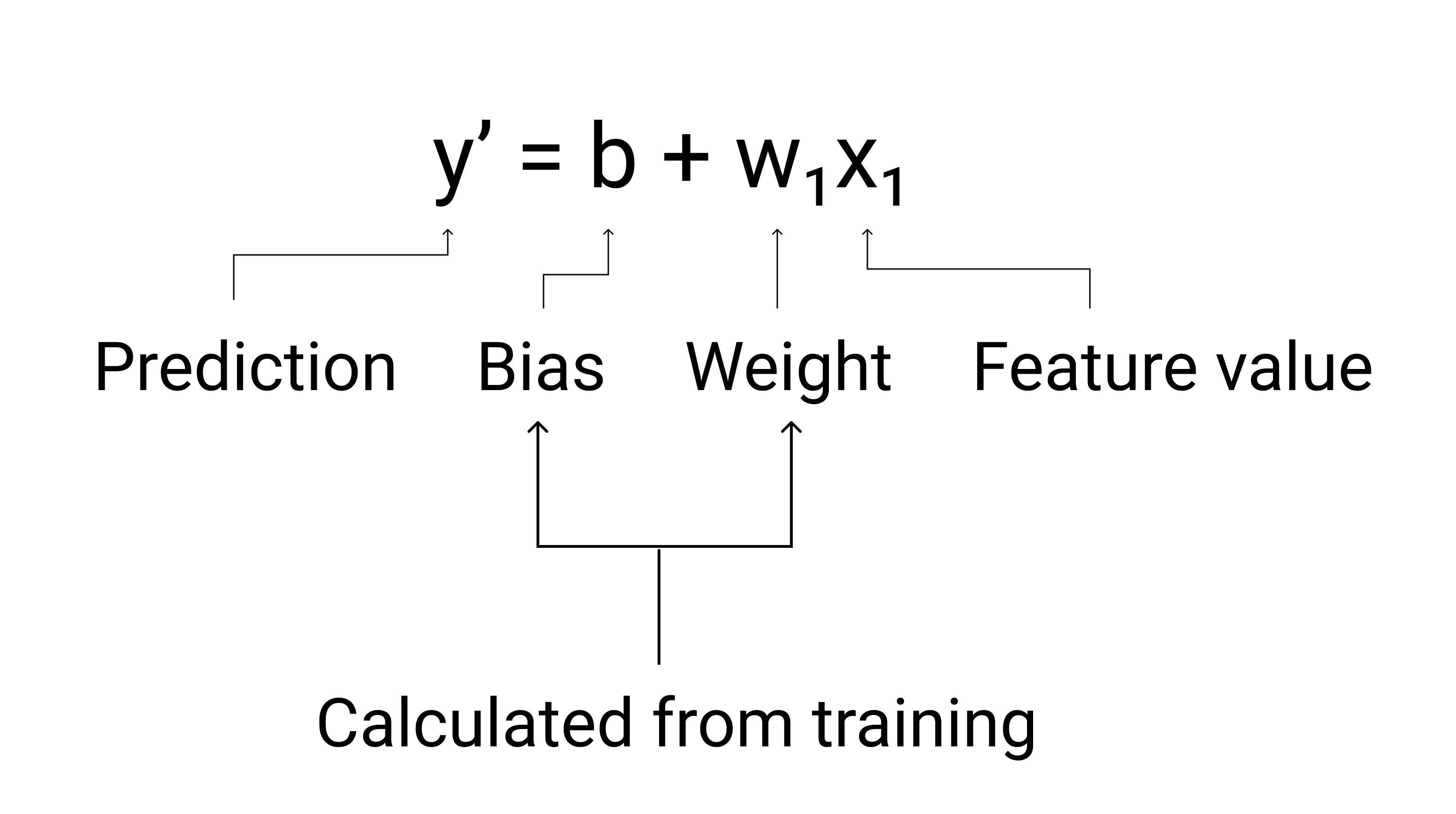
圖 3. 線性模型的數學表示法。
在本例中,我們會根據繪製的線條計算權重和偏差。偏差值為 34 (直線與 y 軸的交點),權重為 -4.6 (直線的斜率)。模型會定義為 $ y' = 34 + (-4.6)(x_1) $,我們可以藉此進行預測。舉例來說,根據這個模型,4,000 磅的車輛預測燃油效率為每加侖 15.6 英里。
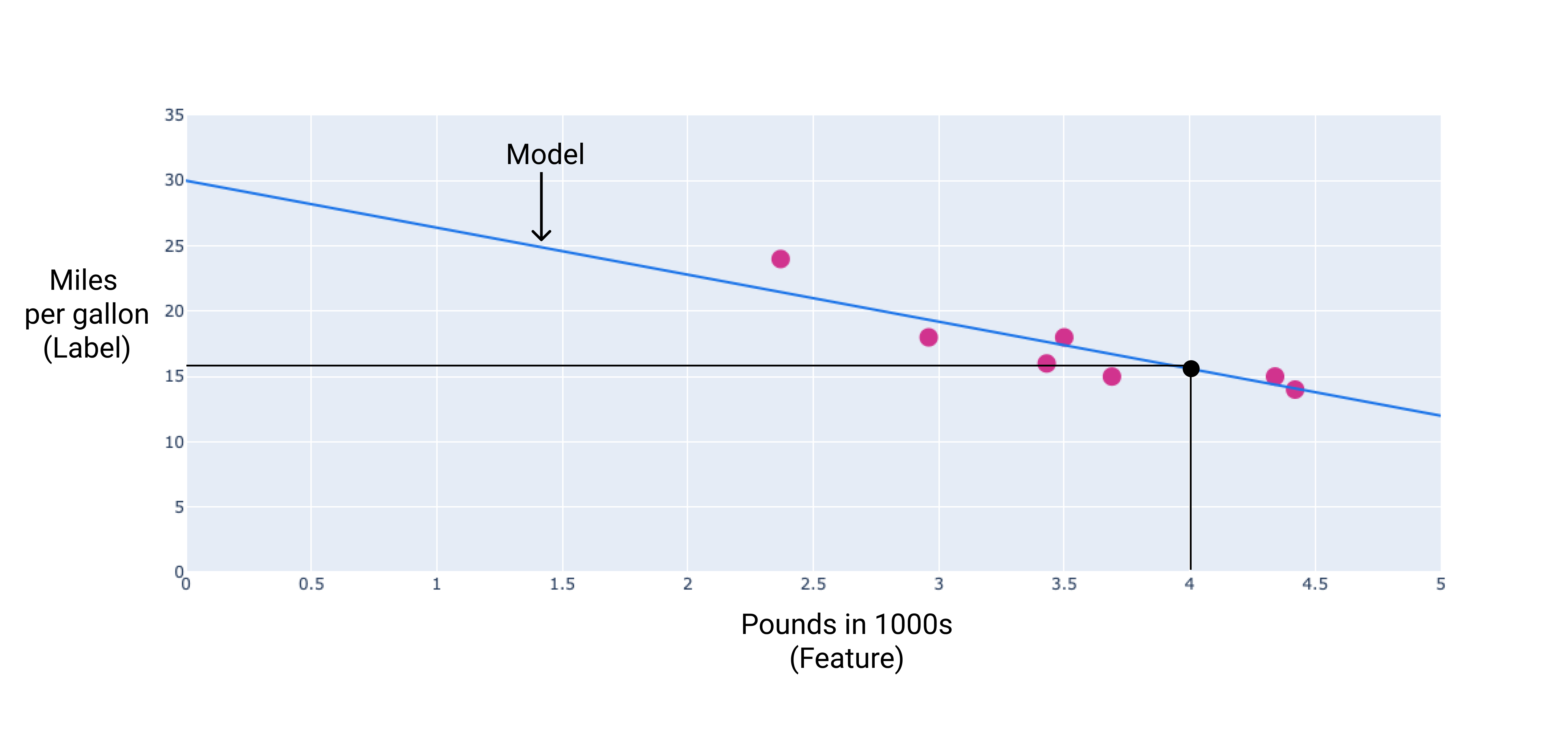
圖 4. 根據這個模型,4,000 磅的車輛預測燃油效率為每加侖 15.6 英里。
具備多項功能的模型
雖然本節的範例只使用一項特徵 (車輛重量),但更精密的模型可能會依賴多項特徵,每項特徵都有個別的權重 ($ w_1 $、$ w_2 $ 等)。舉例來說,如果模型依附五項特徵,寫法如下:
$ y' = b + w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4 + w_5x_5 $
舉例來說,預測油耗的模型可以額外使用下列特徵:
- 引擎排氣量
- 加速
- 汽缸數
- 馬力
這個模型會編寫如下:
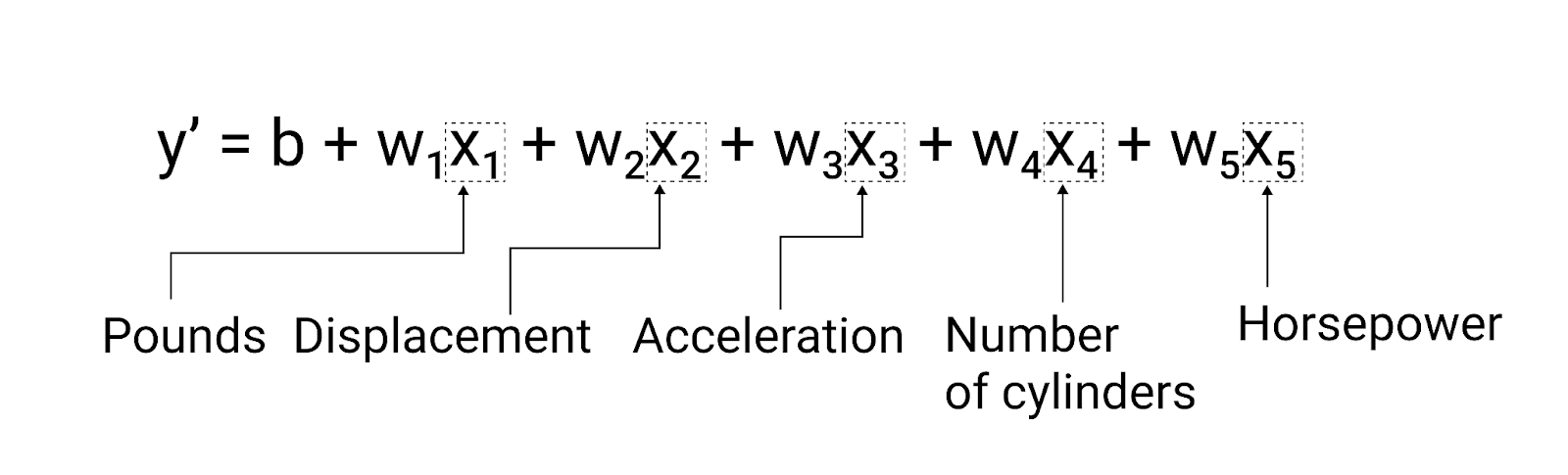
圖 5:這個模型有五項特徵,可預測車輛的每加侖英里數評等。
繪製幾個額外特徵的圖表後,我們可以看到這些特徵與每加侖汽油可行駛里程數標籤之間也存在線性關係:
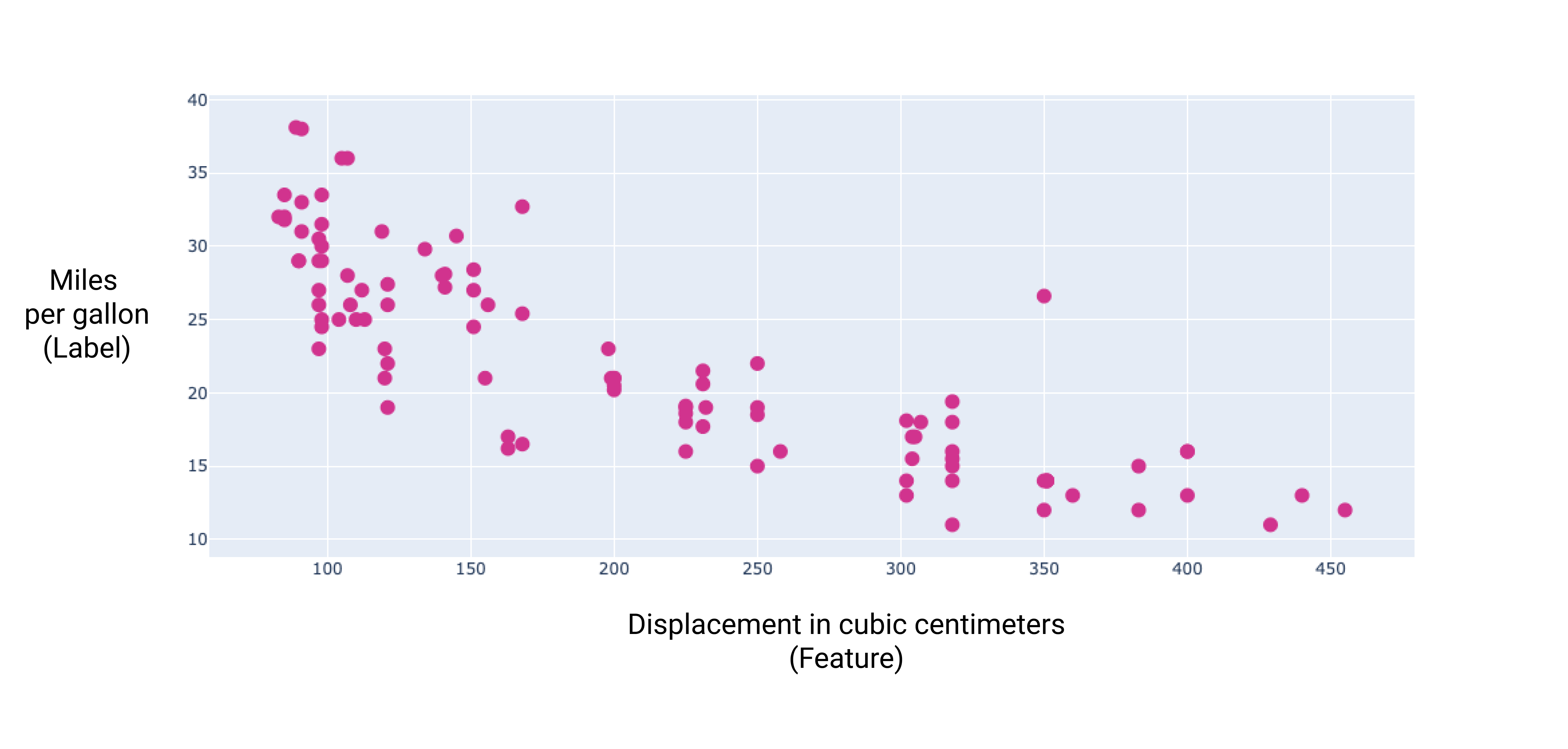
圖 6. 車輛的排氣量 (以立方公分為單位) 和每加侖行駛里程評分。一般來說,引擎越大,每加侖汽油行駛里程數就越低。
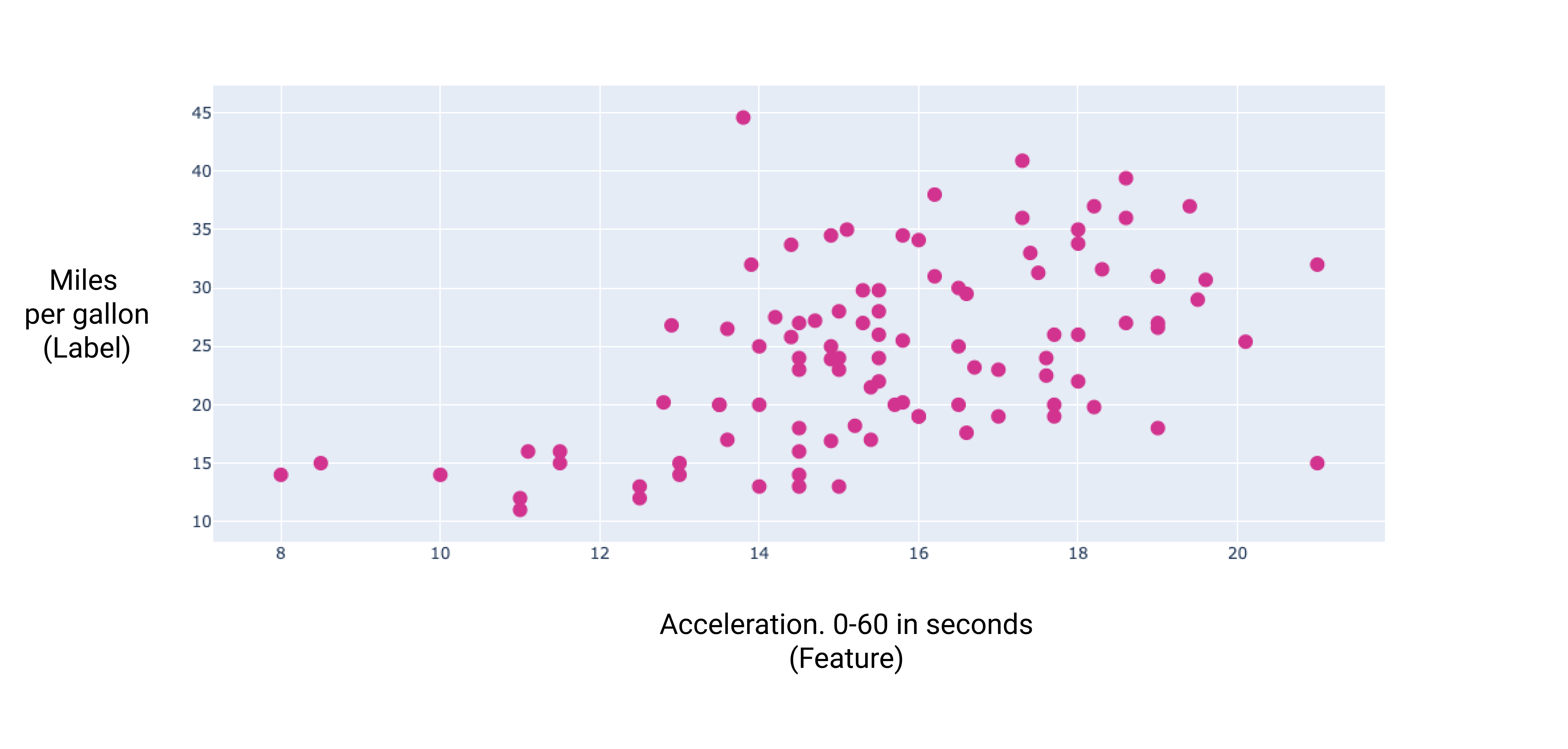
圖 7. 汽車的加速度和每加侖英里數評等。車輛加速時間越長,每加侖汽油行駛里程的評等通常會越高。