In diesem Modul werden die Konzepte der linearen Regression vorgestellt.
Die lineare Regression ist ein statistisches Verfahren, mit dem die Beziehung zwischen Variablen ermittelt wird. Im Kontext von ML wird bei der linearen Regression die Beziehung zwischen Features und einem Label ermittelt.
Angenommen, wir möchten den Kraftstoffverbrauch eines Autos in Meilen pro Gallone auf Grundlage des Gewichts des Autos vorhersagen und haben das folgende Dataset:
| Pfund in Tausend (Funktion) | Meilen pro Gallone (Label) |
|---|---|
| 3,5 | 18 |
| 3,69 | 15 |
| 3.44 | 18 |
| 3.43 | 16 |
| 4.34 | 15 |
| 4,42 | 14 |
| 2,37 | 24 |
Wenn wir diese Punkte in einem Diagramm darstellen, erhalten wir Folgendes:
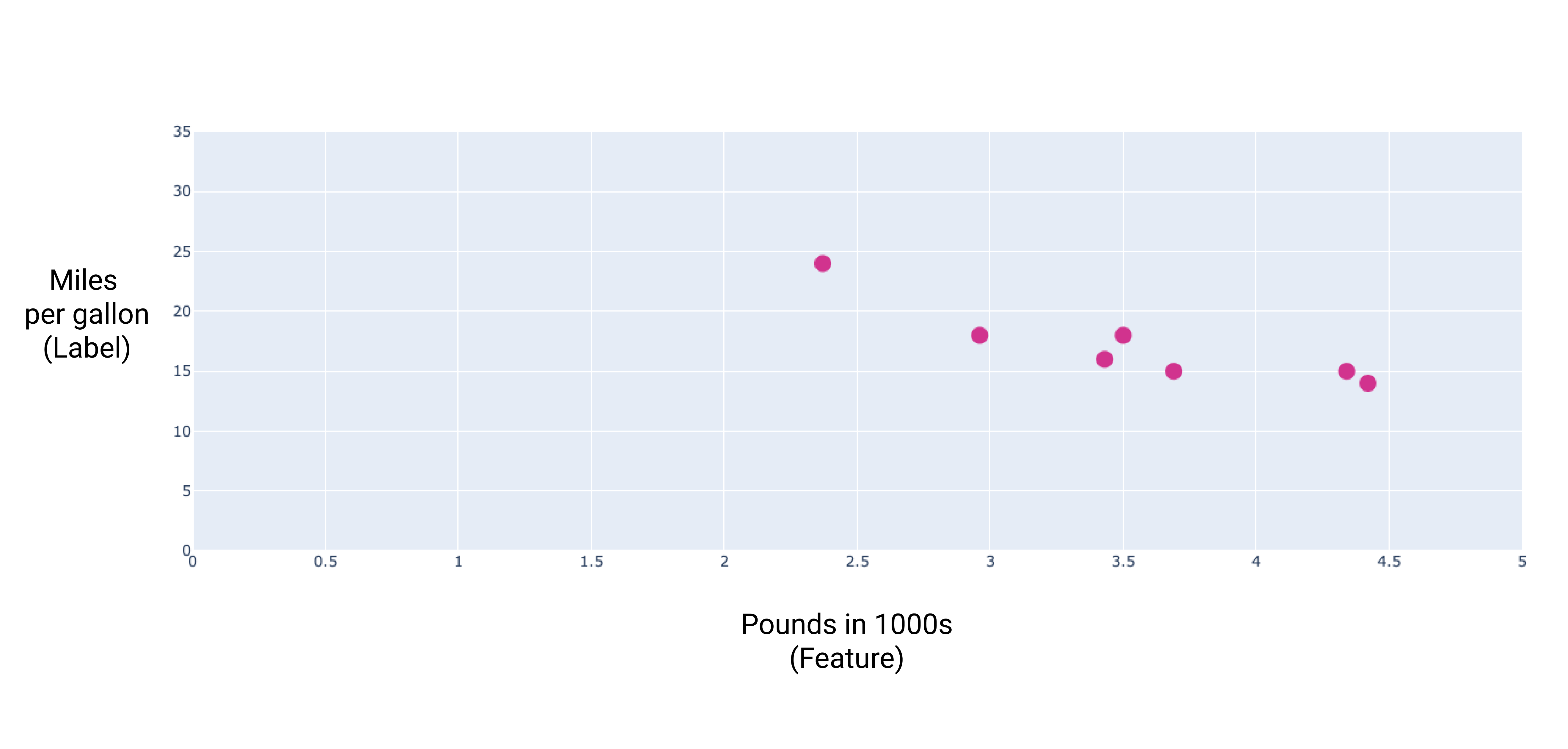
Abbildung 1. Gewicht des Autos (in Pfund) im Vergleich zum Durchschnittsverbrauch (in Meilen pro Gallone). Je schwerer ein Auto ist, desto geringer ist in der Regel die Anzahl der Meilen, die es pro Gallone zurücklegen kann.
Wir könnten ein eigenes Modell erstellen, indem wir eine Linie für die beste Anpassung durch die Punkte ziehen:
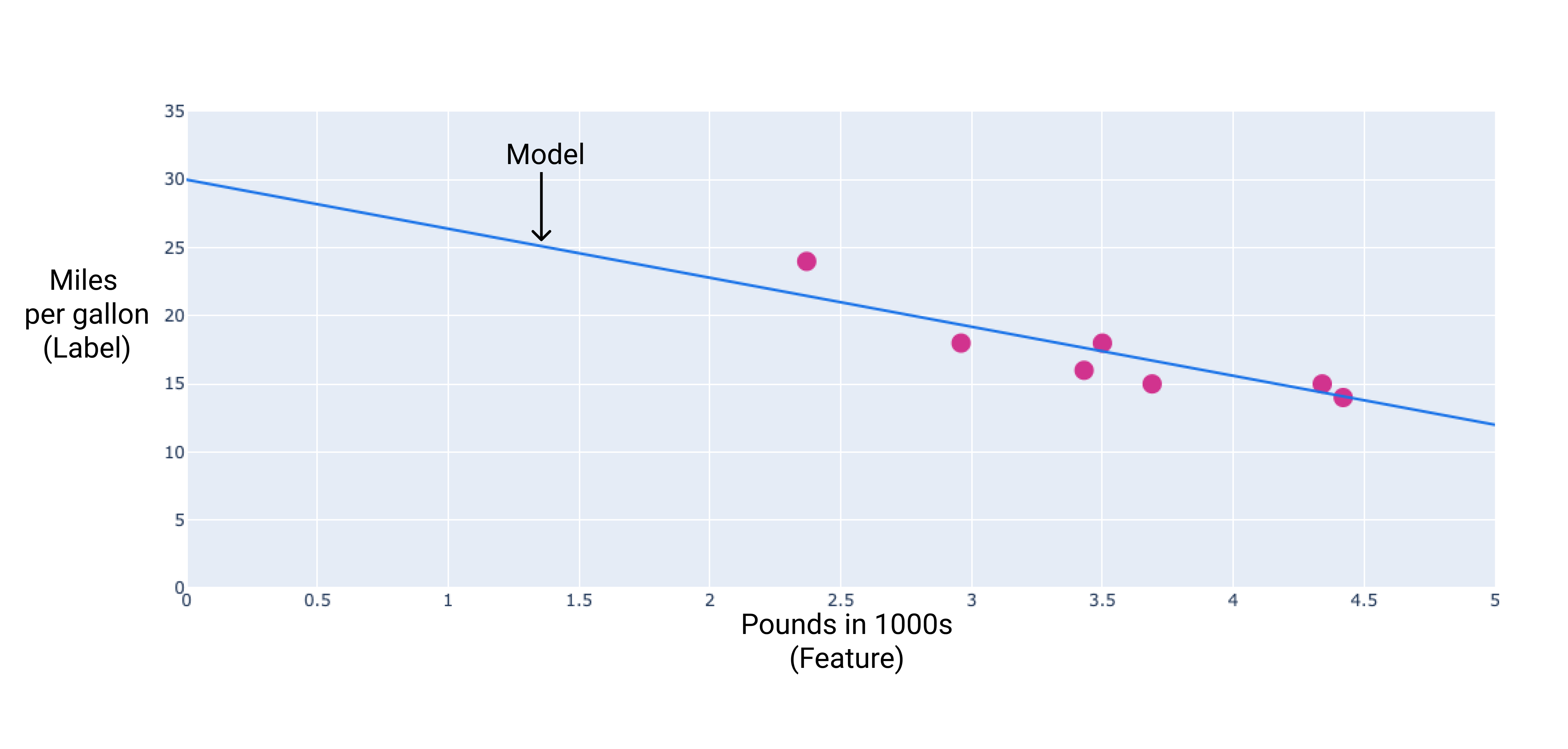
Abbildung 2. Eine Linie, die am besten durch die Daten aus der vorherigen Abbildung passt.
Lineare Regressionsgleichung
In algebraischer Hinsicht wird das Modell als $ y = mx + b $ definiert, wobei
- $ y $ ist der Wert, den wir vorhersagen möchten, nämlich Meilen pro Gallone.
- $ m $ ist die Steigung der Geraden.
- $ x $ ist das Gewicht in Pfund – unser Eingabewert.
- $ b $ ist der Y-Achsenabschnitt.
In ML wird die Gleichung für ein lineares Regressionsmodell so geschrieben:
Dabei gilt:
- $ y' $ ist das vorhergesagte Label – die Ausgabe.
- $ b $ ist der Bias des Modells. Der Bias entspricht dem y-Achsenabschnitt in der algebraischen Gleichung für eine Linie. In ML wird der Bias manchmal auch als $ w_0 $ bezeichnet. Der Bias ist ein Parameter des Modells und wird während des Trainings berechnet.
- $ w_1 $ ist das Gewicht des Merkmals. Die Gewichtung entspricht der Steigung $ m $ in der algebraischen Gleichung für eine Gerade. Die Gewichtung ist ein Parameter des Modells und wird während des Trainings berechnet.
- $ x_1 $ ist ein Feature – die Eingabe.
Während des Trainings berechnet das Modell das Gewicht und den Bias, die das beste Modell ergeben.
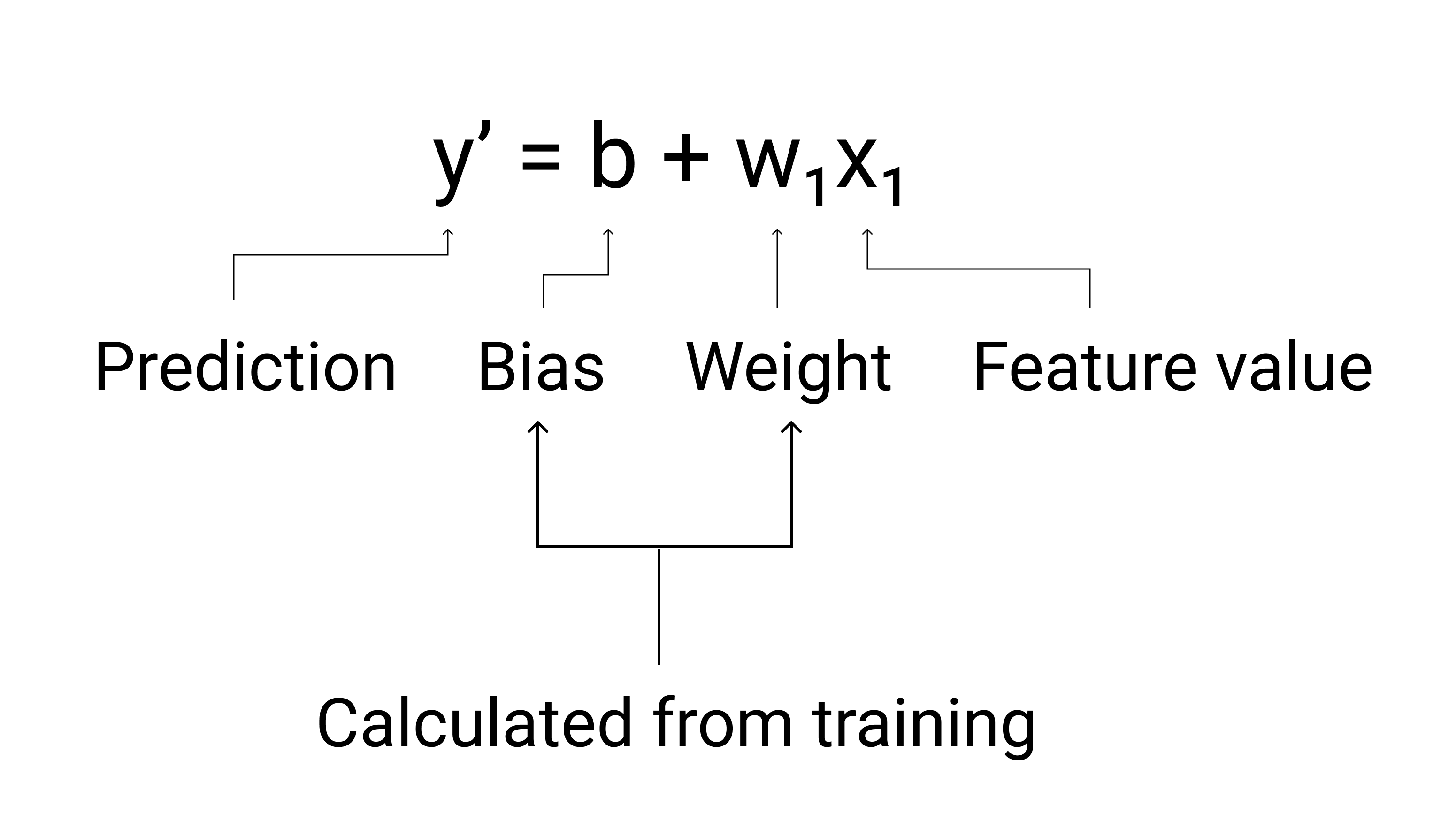
Abbildung 3. Mathematische Darstellung eines linearen Modells.
In unserem Beispiel würden wir das Gewicht und den Bias aus der von uns gezeichneten Linie berechnen. Der Bias beträgt 34 (Schnittpunkt der Linie mit der y-Achse) und die Gewichtung –4,6 (Steigung der Linie). Das Modell würde als $ y' = 34 + (-4.6)(x_1) $ definiert und könnte für Vorhersagen verwendet werden. Mit diesem Modell würde ein 1.814 kg schweres Auto beispielsweise einen geschätzten Kraftstoffverbrauch von 6,6 km pro Liter haben.
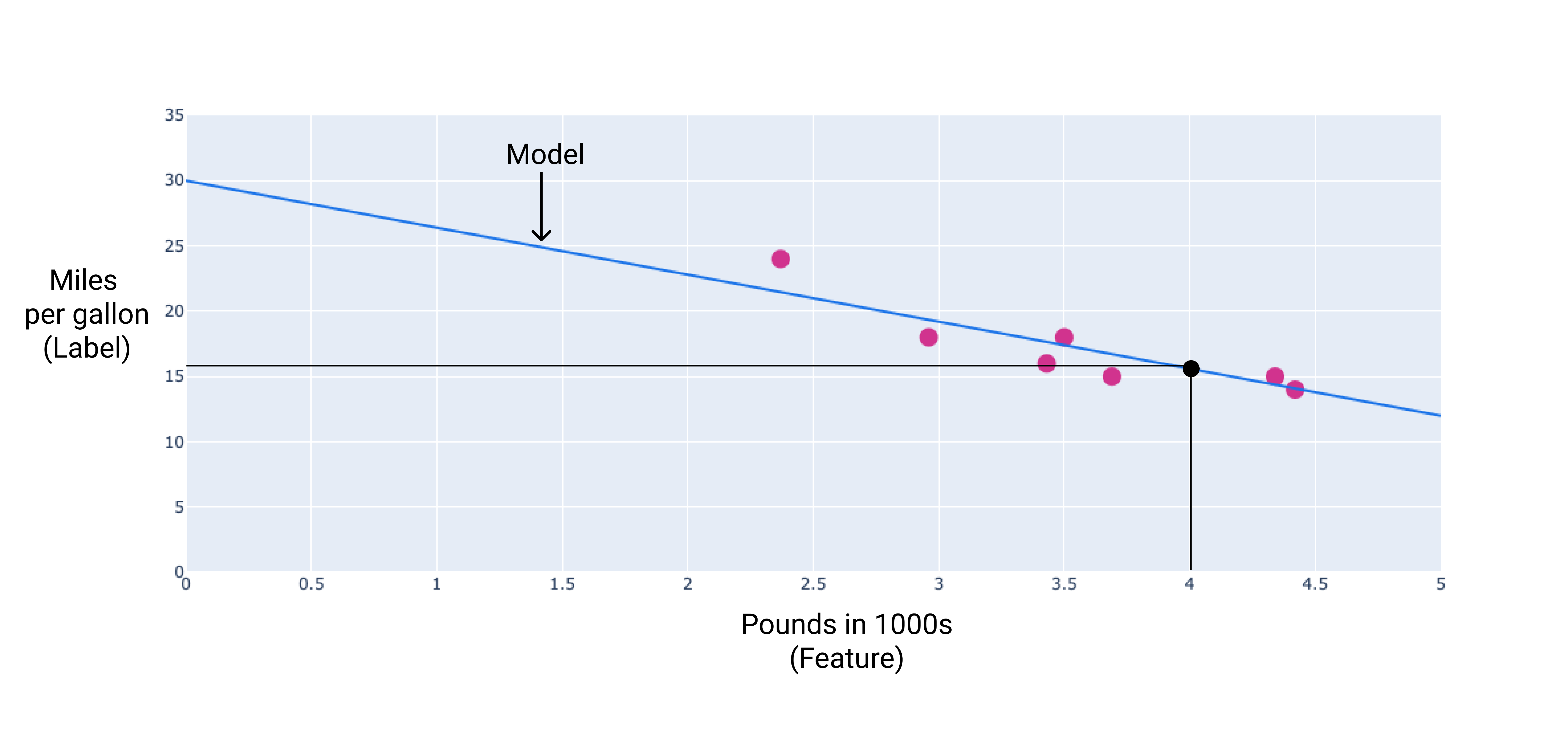
Abbildung 4. Mit dem Modell wird für ein 1.814 kg schweres Auto eine Kraftstoffeffizienz von 6,6 km/l prognostiziert.
Modelle mit mehreren Funktionen
Im Beispiel in diesem Abschnitt wird nur ein Merkmal verwendet, nämlich das Gewicht des Autos. Ein komplexeres Modell kann jedoch auf mehreren Merkmalen basieren, die jeweils ein separates Gewicht haben ($ w_1 $, $ w_2 $ usw.). Ein Modell, das auf fünf Features basiert, würde beispielsweise so geschrieben:
$ y' = b + w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4 + w_5x_5 $
Ein Modell, das den Kraftstoffverbrauch vorhersagt, könnte beispielsweise zusätzlich die folgenden Merkmale verwenden:
- Hubraum
- Beschleunigung
- Anzahl der Zylinder
- Pferdestärke
Dieses Modell würde so geschrieben:
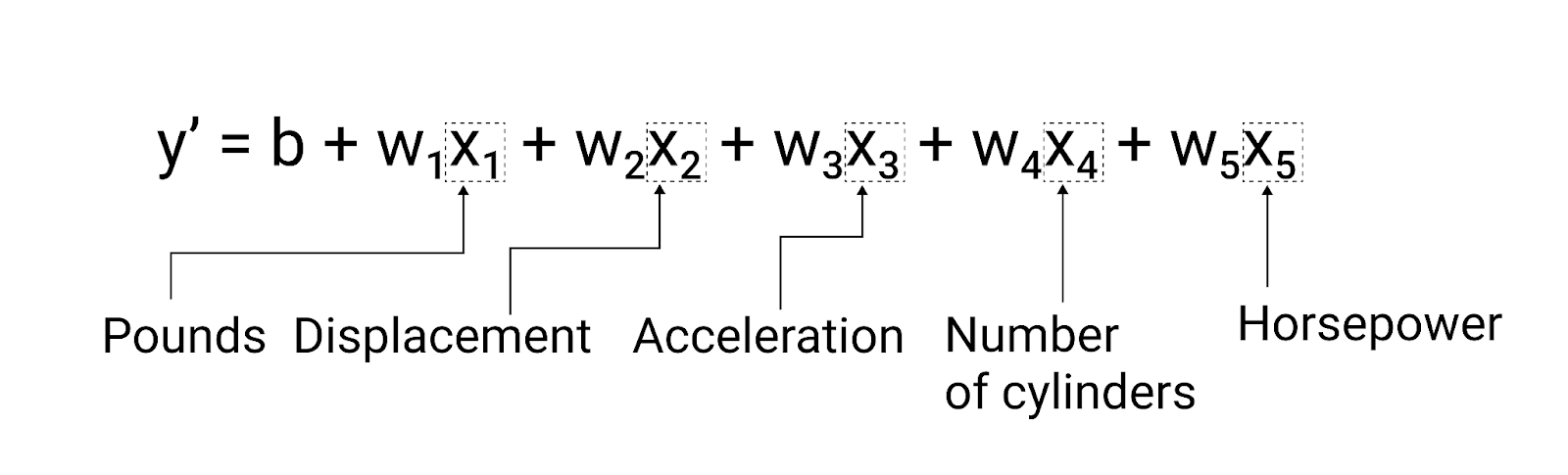
Abbildung 5. Ein Modell mit fünf Features zur Vorhersage der Meilen pro Gallone eines Autos.
Wenn wir einige dieser zusätzlichen Funktionen grafisch darstellen, sehen wir, dass sie auch in einem linearen Verhältnis zum Label „Meilen pro Gallone“ stehen:
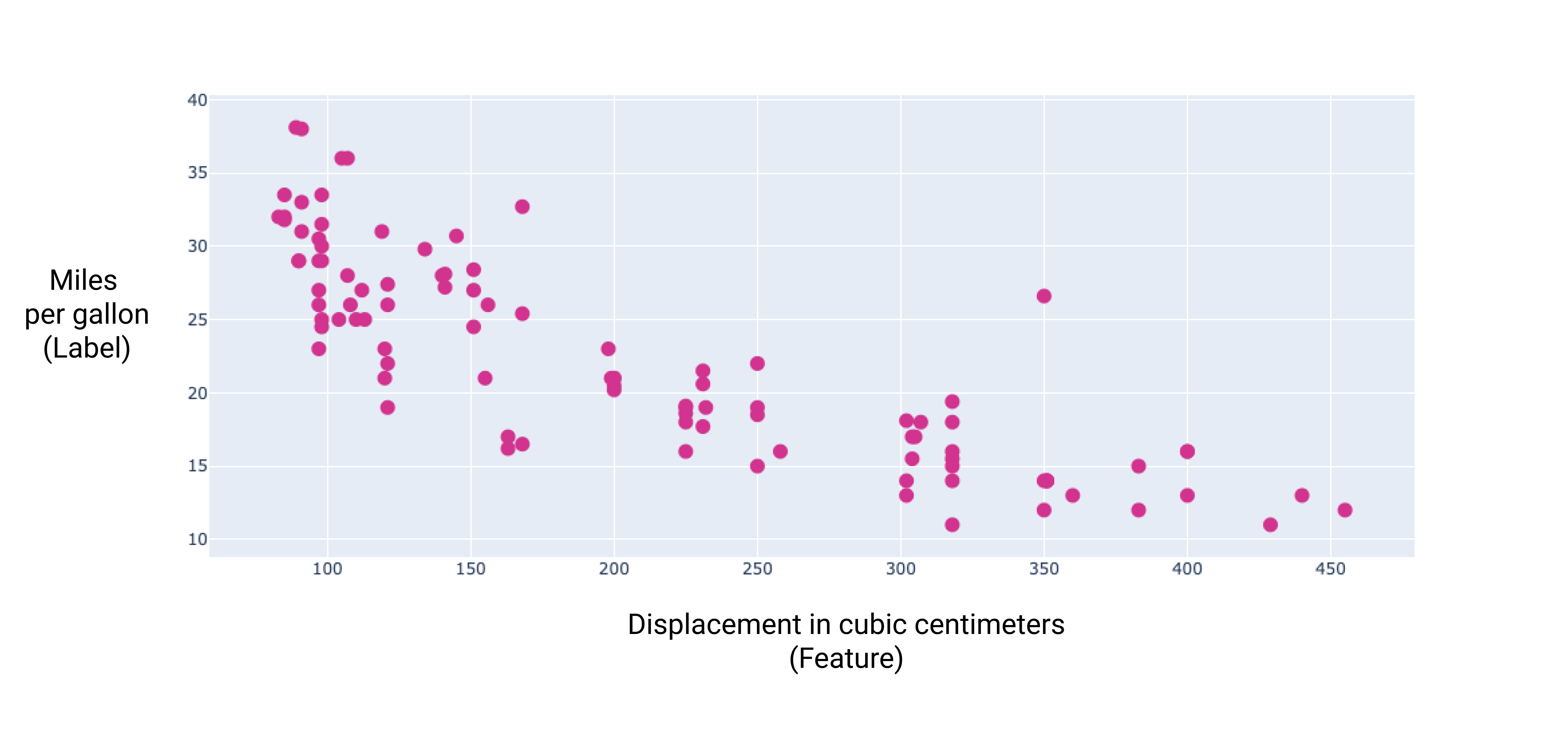
Abbildung 6. Hubraum eines Autos in Kubikzentimetern und die Angabe in Meilen pro Gallone. Je größer der Motor eines Autos ist, desto geringer ist in der Regel der Kraftstoffverbrauch pro Kilometer.
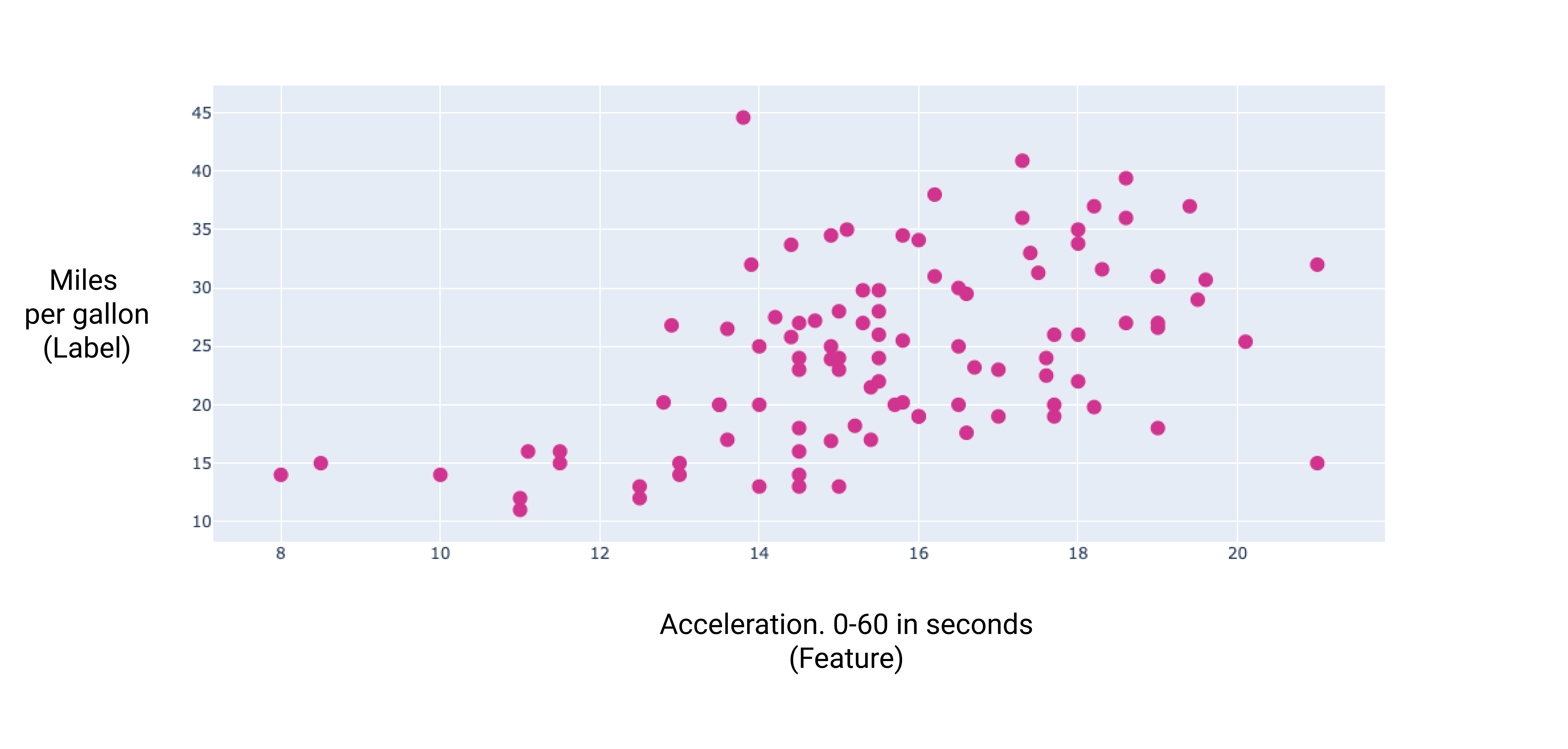
Abbildung 7. Die Beschleunigung eines Autos und sein Kraftstoffverbrauch. Je länger die Beschleunigung eines Autos dauert, desto höher ist in der Regel die Angabe in Meilen pro Gallone.