本模块将介绍线性回归概念。
线性回归是一种用于查找变量之间关系的统计技术。在机器学习背景下,线性回归用于查找特征与标签之间的关系。
例如,假设我们想根据汽车的重量预测汽车的燃油效率(以每加仑英里数表示),并且我们有以下数据集:
| 以千为单位的磅数(特征) | 每加仑英里数(标签) |
|---|---|
| 3.5 | 18 |
| 3.69 | 15 |
| 3.44 | 18 |
| 3.43 | 16 |
| 4.34 | 15 |
| 4.42 | 14 |
| 2.37 | 24 |
如果我们绘制这些点,会得到以下图表:
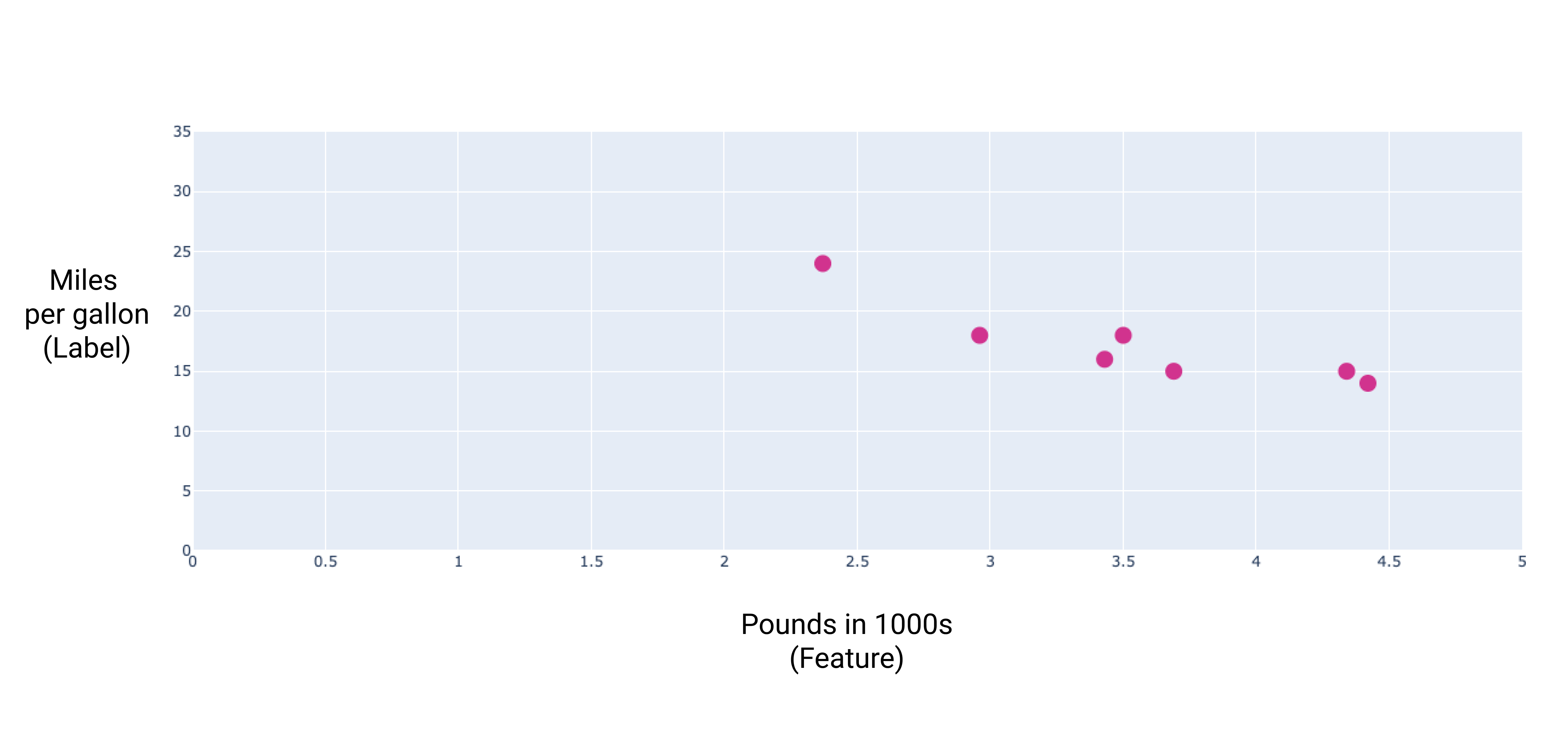
图 1. 汽车重量(以磅为单位)与每加仑汽油能行驶的英里数评级。汽车越重,每加仑燃油行驶里程数通常越低。
我们可以通过在这些点之间绘制最佳拟合线来创建自己的模型:
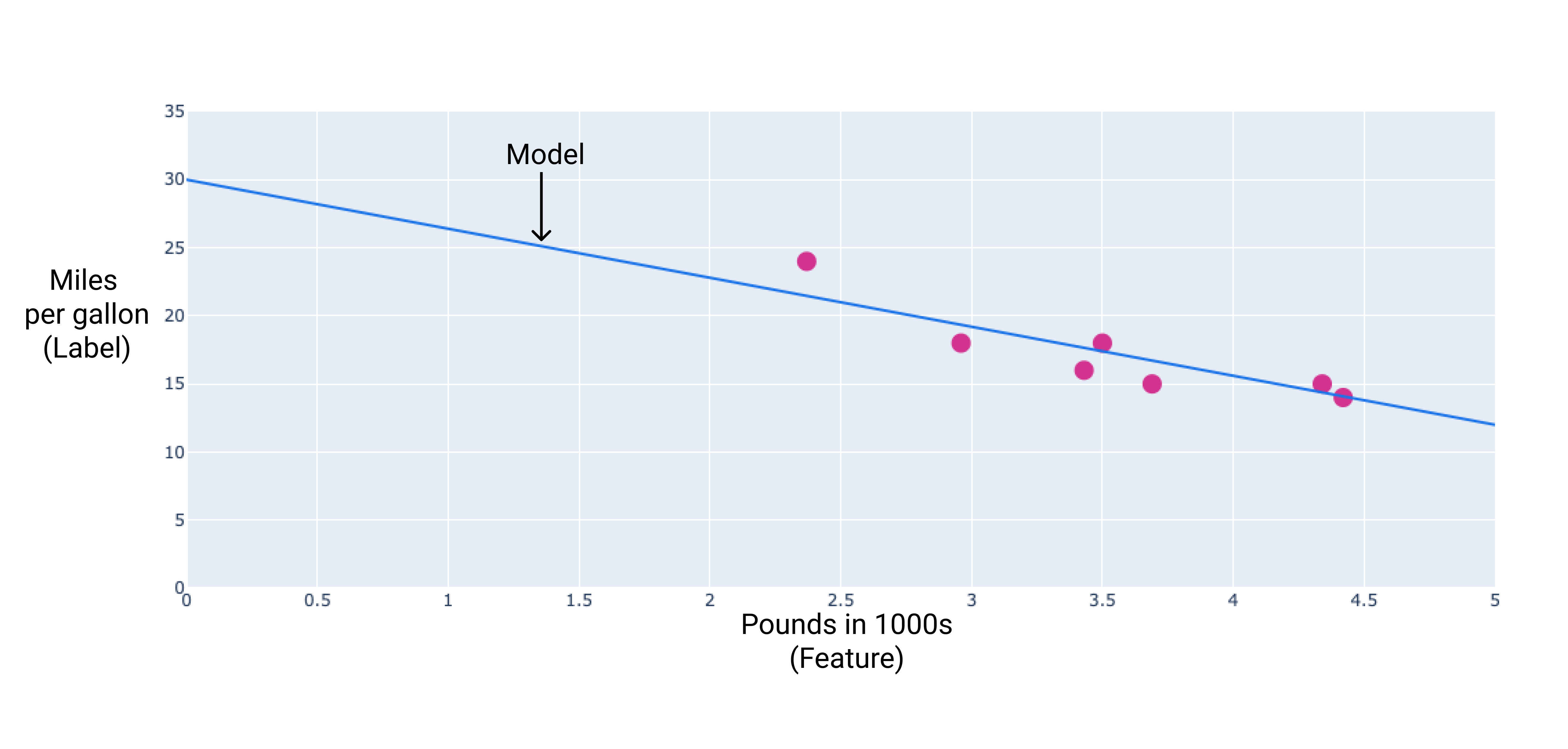
图 2. 通过上图数据绘制的最佳拟合线。
线性回归方程
用代数术语来说,该模型可定义为 $ y = mx + b $,其中
- $ y $ 是每加仑燃油行驶里程数,即我们要预测的值。
- $ m $ 是直线的斜率。
- $ x $ 是磅,即我们的输入值。
- $ b $ 是 y 轴截距。
在机器学习中,线性回归模型的方程式如下所示:
其中:
- $ y' $ 是预测标签(输出)。
- $ b $ 是模型的偏差。偏差与直线代数方程式中的 y 轴截距概念相同。在机器学习中,偏差有时称为 $ w_0$。偏差是模型的形参,在训练期间计算得出。
- $ w_1 $ 是特征的权重。权重与线性代数方程式中的斜率 $ m $ 的概念相同。权重是模型的形参,在训练期间计算得出。
- $ x_1 $ 是一个特征,即输入。
在训练期间,模型会计算出可生成最佳模型的权重和偏差。

图 3. 线性模型的数学表示法。
在我们的示例中,我们将根据绘制的直线计算权重和偏差。偏差为 34(直线与 y 轴的交点),权重为 -4.6(直线的斜率)。该模型可定义为 $ y' = 34 + (-4.6)(x_1) $,我们可以使用它进行预测。例如,使用此模型,一辆 4,000 磅的汽车的预测燃油效率为每加仑 15.6 英里。
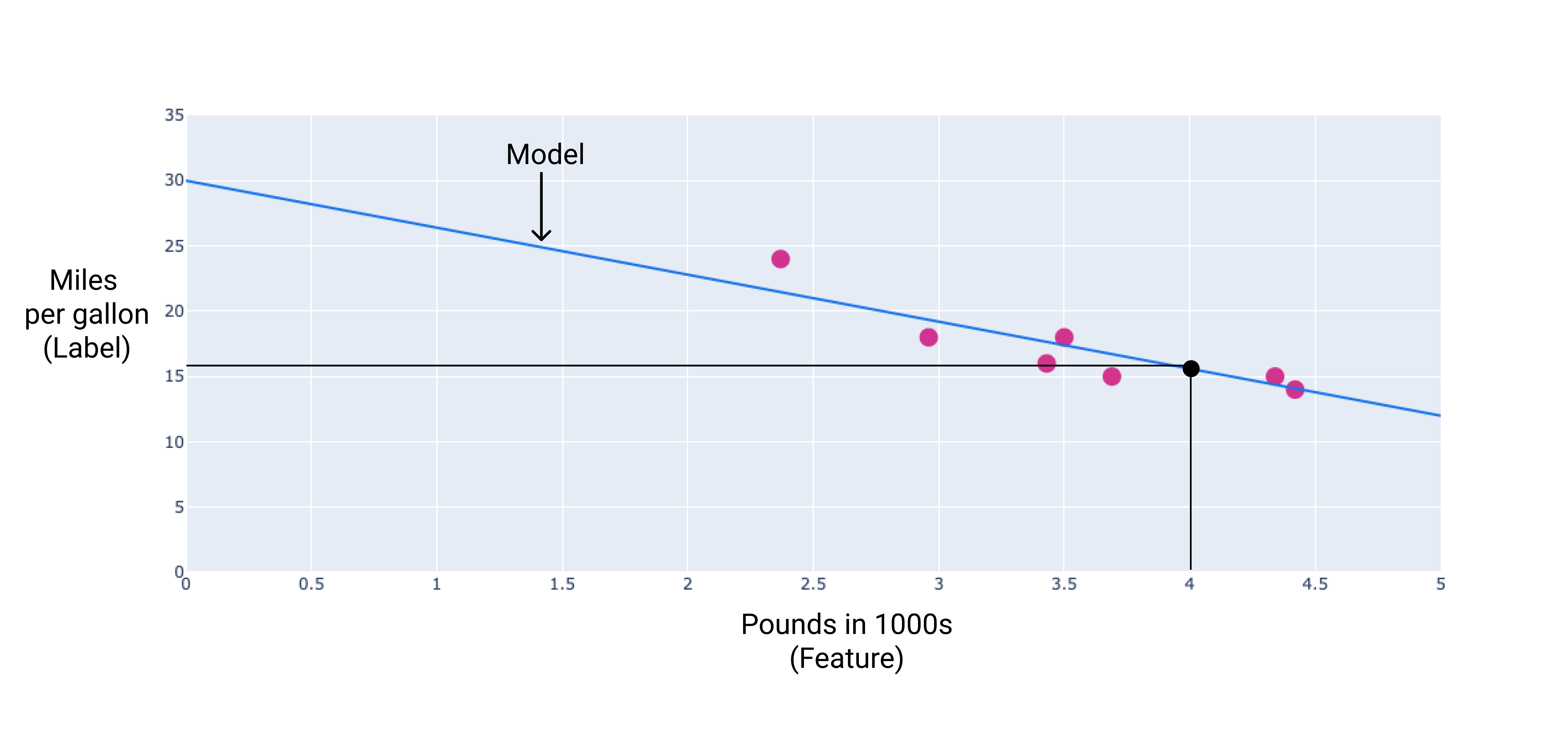
图 4. 根据该模型,一辆 4,000 磅的汽车的预测燃油效率为每加仑 15.6 英里。
具有多种特征的模型
虽然本部分中的示例仅使用一项特征(汽车的重量),但更复杂的模型可能依赖于多项特征,每项特征都有一个单独的权重($ w_1 $、$ w_2 $ 等)。例如,依赖于 5 个特征的模型可以写成如下形式:
$ y' = b + w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4 + w_5x_5 $
例如,预测燃油效率的模型还可以使用以下特征:
- 发动机排量
- 加速
- 圆柱数
- 马力
此模型可写为:
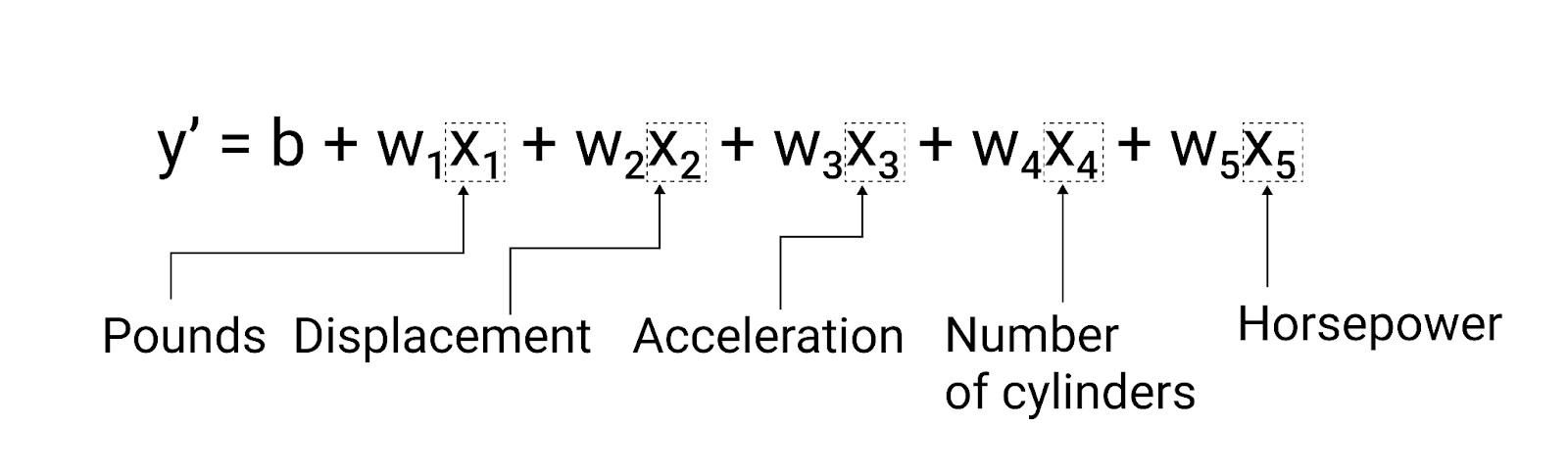
图 5. 一个包含 5 个特征的模型,用于预测汽车的每加仑燃油行驶里程评级。
通过绘制这几个额外特征的图表,我们可以看到它们与标签(每加仑行驶里程数)也存在线性关系:
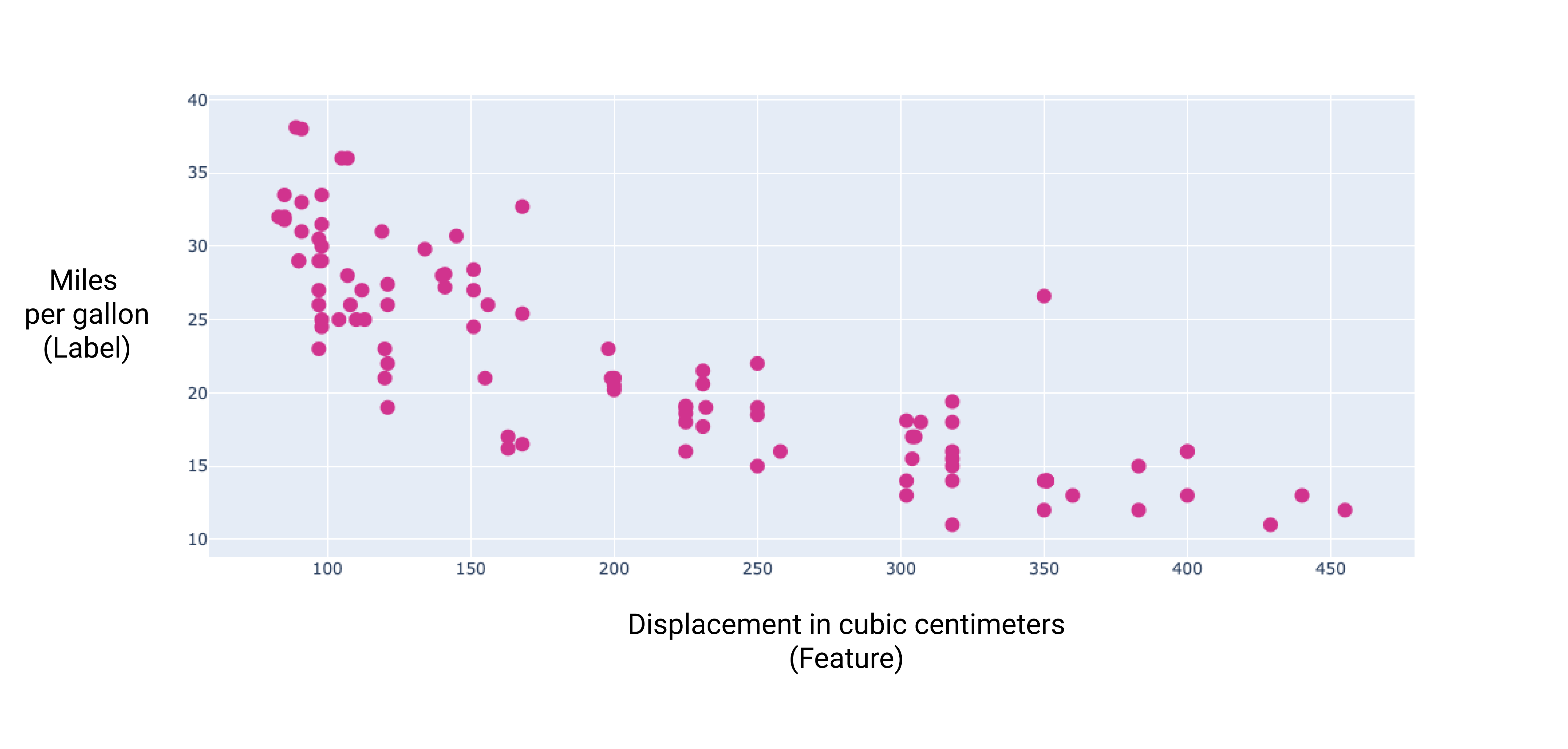
图 6. 汽车的排量(以立方厘米为单位)及其每加仑燃油行驶里程数评级。一般来说,汽车的发动机越大,每加仑燃油行驶里程就越低。
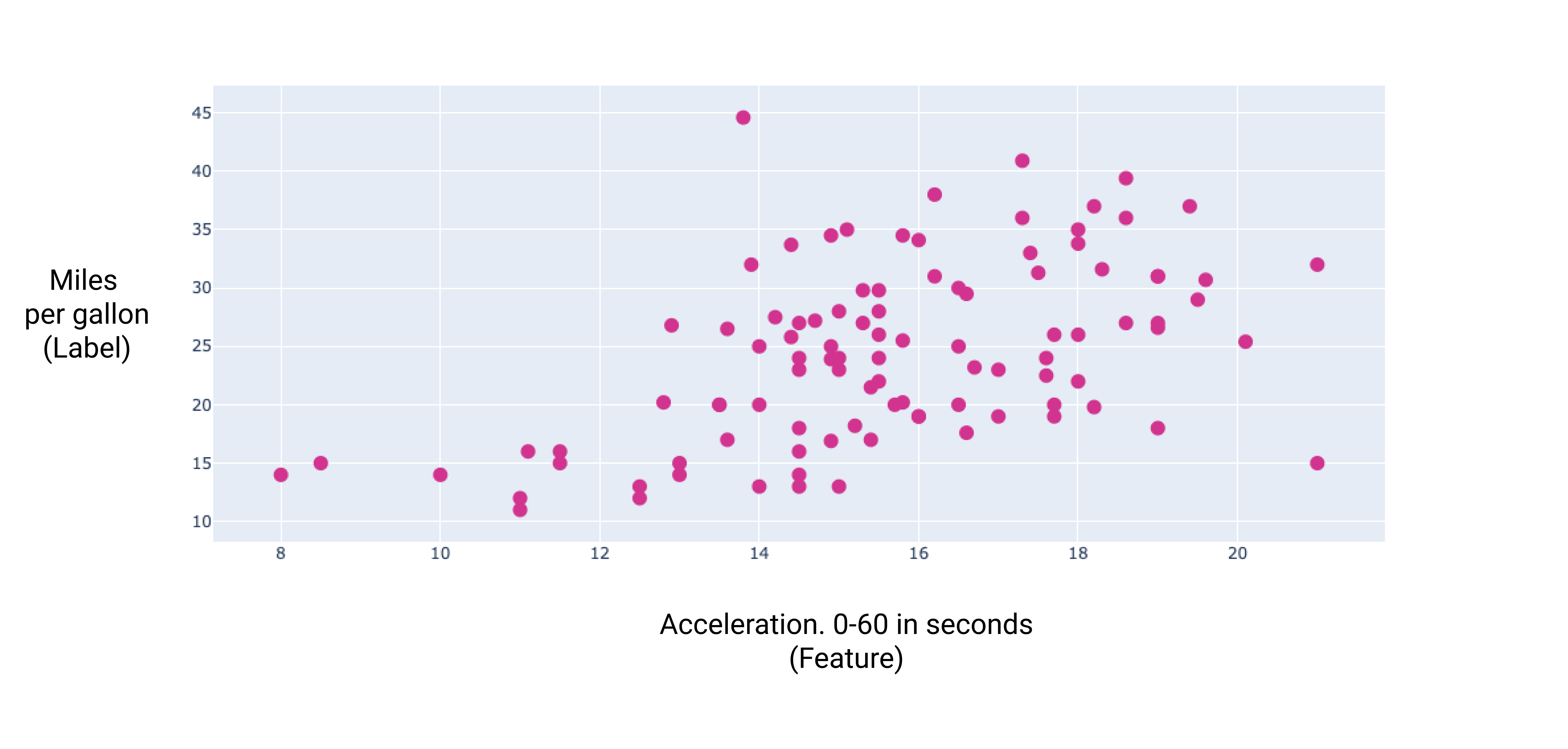
图 7. 汽车的加速度及其每加仑英里数评级。汽车的加速时间越长,每加仑燃油行驶里程评级通常越高。