Une technologie plus récente, les grands modèles de langage (LLM), prédit un jeton ou une séquence de jetons, parfois plusieurs paragraphes de jetons prédits. N'oubliez pas qu'un jeton peut être un mot, un sous-mot (un sous-ensemble d'un mot) ou même un seul caractère. Les LLM font de bien meilleures prédictions que les modèles de langage N-gram ou les réseaux de neurones récurrents, car :
- Les LLM contiennent beaucoup plus de paramètres que les modèles récurrents.
- Les LLM recueillent beaucoup plus de contexte.
Cette section présente l'architecture la plus efficace et la plus utilisée pour créer des LLM : Transformer.
Qu'est-ce qu'un Transformer ?
Les Transformers sont l'architecture de pointe pour une grande variété d'applications de modèles de langage, comme la traduction :

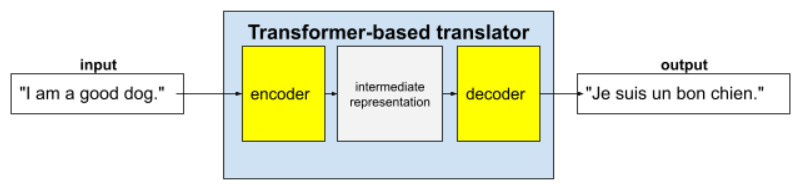
Les Transformers complets se composent d'un encodeur et d'un décodeur :
- Un encodeur convertit le texte d'entrée en une représentation intermédiaire. Un encodeur est un énorme réseau de neurones.
- Un décodeur convertit cette représentation intermédiaire en texte utile. Un décodeur est également un énorme réseau de neurones.
Par exemple, dans un traducteur :
- L'encodeur traite le texte d'entrée (par exemple, une phrase en anglais) pour obtenir une représentation intermédiaire.
- Le décodeur convertit cette représentation intermédiaire en texte de sortie (par exemple, la phrase française équivalente).
Qu'est-ce que l'auto-attention ?
Pour améliorer le contexte, les Transformers s'appuient fortement sur un concept appelé auto-attention. En fait, pour chaque jeton d'entrée, l'auto-attention pose la question suivante :
"Dans quelle mesure chaque autre jeton d'entrée affecte-t-il l'interprétation de ce jeton ?"
Le terme "auto" dans "auto-attention" fait référence à la séquence d'entrée. Certains mécanismes d'attention pondèrent les relations entre les jetons d'entrée et les jetons d'une séquence de sortie (comme une traduction) ou les jetons d'une autre séquence. Toutefois, l'auto-attention ne tient compte que de l'importance des relations entre les jetons de la séquence d'entrée.
Pour simplifier les choses, supposons que chaque jeton est un mot et que le contexte complet n'est qu'une seule phrase. Considérez la phrase suivante :
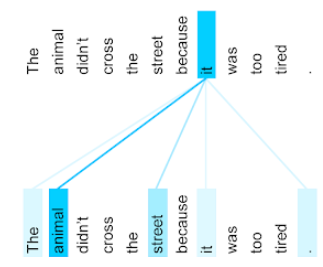
The animal didn't cross the street because it was too tired.
La phrase précédente contient onze mots. Chacun des onze mots prête attention aux dix autres, en se demandant dans quelle mesure chacun de ces dix mots compte pour lui. Par exemple, notez que la phrase contient le pronom it. Les pronoms sont souvent ambigus. Le pronom it (il) fait généralement référence à un nom ou un syntagme nominal récent. Dans l'exemple de phrase, à quel nom récent it fait-il référence : l'animal ou la rue ?
Le mécanisme d'auto-attention détermine la pertinence de chaque mot proche par rapport au pronom il. La figure 3 montre les résultats : plus la ligne est bleue, plus le mot est important pour le pronom it. Autrement dit, animal est plus important que rue pour le pronom il.
Inversement, supposons que le dernier mot de la phrase change comme suit :
The animal didn't cross the street because it was too wide.
Dans cette phrase révisée, l'auto-attention devrait, espérons-le, considérer rue comme plus pertinent que animal pour le pronom il.
Certains mécanismes d'auto-attention sont bidirectionnels, ce qui signifie qu'ils calculent les scores de pertinence pour les jetons précédant et suivant le mot auquel l'attention est portée. Par exemple, sur la figure 3, notez que les mots des deux côtés de it sont examinés. Ainsi, un mécanisme d'auto-attention bidirectionnel peut recueillir le contexte des mots situés de part et d'autre du mot auquel l'attention est portée. En revanche, un mécanisme d'auto-attention unidirectionnel ne peut collecter le contexte que des mots situés d'un seul côté du mot auquel il s'intéresse. L'auto-attention bidirectionnelle est particulièrement utile pour générer des représentations de séquences entières, tandis que les applications qui génèrent des séquences jeton par jeton nécessitent une auto-attention unidirectionnelle. C'est pourquoi les encodeurs utilisent l'auto-attention bidirectionnelle, tandis que les décodeurs utilisent l'auto-attention unidirectionnelle.
Qu'est-ce que l'auto-attention multicouche et multi-tête ?
Chaque couche d'auto-attention est généralement composée de plusieurs têtes d'auto-attention. La sortie d'un calque est une opération mathématique (par exemple, une moyenne pondérée ou un produit scalaire) de la sortie des différentes têtes.
Étant donné que les paramètres de chaque tête sont initialisés avec des valeurs aléatoires, différentes têtes peuvent apprendre différentes relations entre chaque mot auquel l'attention est portée et les mots proches. Par exemple, le mécanisme d'auto-attention décrit dans la section précédente visait à déterminer à quel nom se référait le pronom il. Toutefois, d'autres têtes d'auto-attention au sein de la même couche peuvent apprendre la pertinence grammaticale de chaque mot par rapport à tous les autres mots, ou apprendre d'autres interactions.
Un modèle Transformer complet empile plusieurs couches d'auto-attention les unes sur les autres. La sortie de la couche précédente devient l'entrée de la suivante. Cette superposition permet au modèle de développer une compréhension de plus en plus complexe et abstraite du texte. Alors que les couches précédentes peuvent se concentrer sur la syntaxe de base, les couches plus profondes peuvent intégrer ces informations pour saisir des concepts plus nuancés comme le sentiment, le contexte et les liens thématiques dans l'ensemble de l'entrée.
Pourquoi les Transformers sont-ils si grands ?
Les Transformers contiennent des centaines de milliards, voire des milliers de milliards de paramètres. Ce cours recommande généralement de créer des modèles avec un nombre de paramètres plus petit plutôt qu'avec un nombre de paramètres plus grand. En effet, un modèle avec un nombre de paramètres plus petit utilise moins de ressources pour faire des prédictions qu'un modèle avec un nombre de paramètres plus grand. Toutefois, les études montrent que les Transformers avec plus de paramètres surpassent systématiquement ceux avec moins de paramètres.
Mais comment un LLM génère-t-il du texte ?
Vous avez vu comment les chercheurs entraînent les LLM à prédire un ou deux mots manquants, et vous n'êtes peut-être pas impressionné. Après tout, prédire un mot ou deux est essentiellement la fonctionnalité de saisie semi-automatique intégrée à divers logiciels de texte, de messagerie et de création. Vous vous demandez peut-être comment les LLM peuvent générer des phrases, des paragraphes ou des haïkus sur l'arbitrage.
En fait, les LLM sont essentiellement des mécanismes de saisie automatique qui peuvent prédire (compléter) automatiquement des milliers de jetons. Prenons l'exemple d'une phrase suivie d'une phrase masquée :
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
Un LLM peut générer des probabilités pour la phrase masquée, y compris :
| Probabilité | Mot(s) |
|---|---|
| 3,1 % | Par exemple, il peut s'asseoir, rester en place et se retourner. |
| 2,9 % | Par exemple, il sait s'asseoir, rester en place et se retourner. |
Un LLM suffisamment grand peut générer des probabilités pour des paragraphes et des essais entiers. Vous pouvez considérer les questions d'un utilisateur à un LLM comme la phrase "donnée" suivie d'un masque imaginaire. Exemple :
User's question: What is the easiest trick to teach a dog? LLM's response: ___
Le LLM génère des probabilités pour différentes réponses possibles.
Par exemple, un LLM entraîné sur un grand nombre de problèmes de mathématiques peut donner l'impression d'effectuer un raisonnement mathématique sophistiqué. Toutefois, ces LLM se contentent essentiellement de compléter une invite de problème de mot.
Avantages des LLM
Les LLM peuvent générer du texte clair et facile à comprendre pour une grande variété d'audiences cibles. Les LLM peuvent faire des prédictions sur les tâches pour lesquelles ils sont explicitement entraînés. Certains chercheurs affirment que les LLM peuvent également faire des prédictions pour des entrées sur lesquelles ils n'ont pas été explicitement entraînés, mais d'autres chercheurs ont réfuté cette affirmation.
Problèmes liés aux LLM
L'entraînement d'un LLM implique de nombreux problèmes, y compris :
- Rassembler un énorme ensemble d'entraînement.
- Cela nécessite plusieurs mois, ainsi que d'énormes ressources de calcul et d'électricité.
- Résoudre les problèmes de parallélisme.
L'utilisation de LLM pour inférer des prédictions pose les problèmes suivants :
- Les LLM hallucinent, ce qui signifie que leurs prédictions contiennent souvent des erreurs.
- Les LLM consomment d'énormes quantités de ressources de calcul et d'électricité. L'entraînement des LLM sur des ensembles de données plus volumineux réduit généralement la quantité de ressources requises pour l'inférence, bien que les ensembles d'entraînement plus volumineux nécessitent davantage de ressources d'entraînement.
- Comme tous les modèles de ML, les LLM peuvent présenter toutes sortes de biais.