טכנולוגיה חדשה יותר, מודלים גדולים של שפה (LLM), חוזה טוקן או רצף של טוקנים, לפעמים טוקנים חזויים באורך של כמה פסקאות. חשוב לזכור שטוקן יכול להיות מילה, תת-מילה (קבוצת משנה של מילה) או אפילו תו בודד. מודלים גדולים של שפה (LLM) מספקים תחזיות טובות בהרבה ממודלים של שפה מסוג N-gram או מרשתות נוירונים חוזרות, כי:
- מודלים גדולים של שפה (LLM) מכילים הרבה יותר פרמטרים ממודלים חוזרים.
- מודלי שפה גדולים אוספים הרבה יותר הקשר.
בקטע הזה נציג את הארכיטקטורה הכי מוצלחת ונפוצה לבניית מודלים של שפה גדולה (LLM): טרנספורמר.
מה זה טרנספורמר?
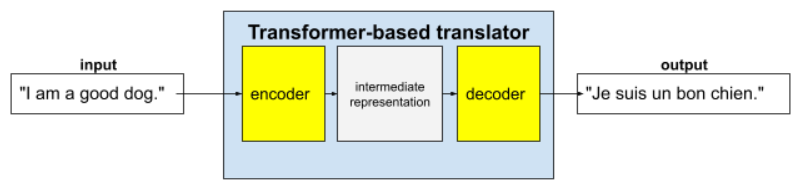
טרנספורמרים הם ארכיטקטורה מתקדמת למגוון רחב של יישומי מודלים של שפה, כמו תרגום:

טרנספורמרים מלאים מורכבים ממקודד ומפענח:
- מקודד ממיר טקסט קלט לייצוג ביניים. מקודד הוא רשת נוירונים עצומה.
- מפענח ממיר את הייצוג הזה לטקסט שימושי. מפענח הוא גם רשת נוירונים עצומה.
לדוגמה, בכלי תרגום:
- המקודד מעבד את טקסט הקלט (לדוגמה, משפט באנגלית) לייצוג ביניים כלשהו.
- המפענח ממיר את הייצוג הזה לטקסט פלט (לדוגמה, המשפט המקביל בצרפתית).
מהו קשב עצמי?
כדי לשפר את ההקשר, מודלים מסוג טרנספורמר מסתמכים במידה רבה על קונספט שנקרא קשב עצמי. למעשה, בשם כל טוקן של קלט, מנגנון תשומת הלב העצמית שואל את השאלה הבאה:
"How much does each other token of input affect the interpretation of this token?"
התחילית 'עצמי' במונח 'קשב עצמי' מתייחסת לרצף הקלט. חלק ממנגנוני הקשב שוקלים את היחסים בין טוקנים של קלט לבין טוקנים ברצף של פלט, כמו תרגום, או לבין טוקנים ברצף אחר. אבל תשומת לב עצמית בלבד שוקלת את חשיבות היחסים בין טוקנים ברצף הקלט.
כדי לפשט את הדברים, נניח שכל טוקן הוא מילה וההקשר המלא הוא רק משפט אחד. נניח שיש לכם את המשפט הבא:
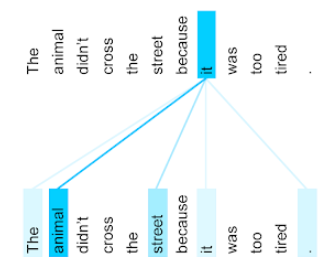
The animal didn't cross the street because it was too tired.
המשפט הקודם מכיל 11 מילים. כל אחת מ-11 המילים מתייחסת ל-10 המילים האחרות, וחושבת כמה כל אחת מ-10 המילים האלה חשובה לה. לדוגמה, שימו לב שהמשפט מכיל את כינוי הגוף it. לשון הפנייה היא לרוב דו-משמעית. בדרך כלל, כינוי הגוף it מתייחס לשם עצם או לצירוף שם עצם מהזמן האחרון, אבל במשפט לדוגמה, לאיזה שם עצם מהזמן האחרון מתייחס it – לחיה או לרחוב?
מנגנון הקשב העצמי קובע את הרלוונטיות של כל מילה סמוכה לכינוי it. באיור 3 מוצגות התוצאות – ככל שהקו כחול יותר, המילה חשובה יותר לכינוי it. כלומר, animal חשוב יותר מ-street לכינוי it.
לעומת זאת, נניח שהמילה האחרונה במשפט משתנה באופן הבא:
The animal didn't cross the street because it was too wide.
במשפט המתוקן הזה, מנגנון הקשב העצמי ידרג את המילה street כרלוונטית יותר מהמילה animal לכינוי הגוף it.
חלק ממנגנוני תשומת הלב העצמית הם דו-כיווניים, כלומר הם מחשבים ציוני רלוונטיות לטוקנים שלפני המילה שמתמקדים בה ואחריה. לדוגמה, באיור 3 אפשר לראות שהמילים משני הצדדים של it נבדקות. לכן, מנגנון דו-כיווני של תשומת לב עצמית יכול לאסוף הקשר ממילים משני הצדדים של המילה שמתמקדים בה. לעומת זאת, מנגנון חד-כיווני של תשומת לב עצמית יכול לאסוף הקשר רק ממילים בצד אחד של המילה שמופנית אליה תשומת הלב. מנגנון תשומת הלב העצמית הדו-כיוונית שימושי במיוחד ליצירת ייצוגים של רצפים שלמים, בעוד שאפליקציות שיוצרות רצפים של טוקנים דורשות מנגנון תשומת לב עצמית חד-כיוונית. לכן, מקודדים משתמשים בתשומת לב עצמית דו-כיוונית, ומפענחים משתמשים בתשומת לב עצמית חד-כיוונית.
מהו מנגנון קשב עצמי עם מספר ראשים ומספר שכבות?
כל שכבת קשב עצמי מורכבת בדרך כלל מכמה ראשי קשב עצמי. הפלט של שכבה הוא פעולה מתמטית (לדוגמה, ממוצע משוקלל או מכפלה סקלרית) של הפלט של הראשים השונים.
מכיוון שהפרמטרים של כל ראש מאותחלים לערכים אקראיים, ראשי תשומת לב שונים יכולים ללמוד קשרים שונים בין כל מילה שמופנית אליה תשומת הלב לבין המילים הסמוכות. לדוגמה, ראש תשומת הלב העצמית שמתואר בקטע הקודם התמקד בקביעה לאיזה שם עצם מתייחסת מילת הגוף it. עם זאת, ראשי קשב עצמי אחרים באותה שכבה עשויים ללמוד את הרלוונטיות הדקדוקית של כל מילה לכל מילה אחרת, או ללמוד אינטראקציות אחרות.
מודל טרנספורמר מלא כולל כמה שכבות של קשב עצמי שמונחות אחת על השנייה. הפלט מהשכבה הקודמת הופך לקלט של השכבה הבאה. השילוב הזה מאפשר למודל לבנות הבנות מורכבות ואבסטרקטיות יותר של הטקסט. יכול להיות ששכבות מוקדמות יותר יתמקדו בתחביר בסיסי, אבל שכבות עמוקות יותר יכולות לשלב את המידע הזה כדי להבין מושגים מורכבים יותר כמו סנטימנט, הקשר וקשרים נושאיים בכל הקלט.
למה טרנספורמרים כל כך גדולים?
מודלי טרנספורמר מכילים מאות מיליארדים או אפילו טריליונים של פרמטרים. בקורס הזה מומלץ בדרך כלל לבנות מודלים עם מספר קטן יותר של פרמטרים, ולא עם מספר גדול יותר של פרמטרים. בסופו של דבר, מודל עם מספר קטן יותר של פרמטרים משתמש בפחות משאבים כדי ליצור תחזיות בהשוואה למודל עם מספר גדול יותר של פרמטרים. עם זאת, מחקרים מראים שטרנספורמרים עם יותר פרמטרים משיגים ביצועים טובים יותר באופן עקבי בהשוואה לטרנספורמרים עם פחות פרמטרים.
אבל איך מודל שפה גדול יוצר טקסט?
ראיתם איך חוקרים מאמנים מודלים גדולים של שפה כדי לחזות מילה או שתיים שחסרות, ואולי לא התרשמתם. אחרי הכול, חיזוי של מילה או שתיים הוא בעצם התכונה של השלמה אוטומטית שמוטמעת בתוכנות שונות של טקסט, אימייל וכתיבה. יכול להיות שאתם תוהים איך מודלים גדולים של שפה יכולים ליצור משפטים, פסקאות או שירי הייקו על ארביטראז'.
למעשה, מודלים של שפה גדולה הם מנגנונים של השלמה אוטומטית שיכולים לחזות (להשלים) אלפי טוקנים באופן אוטומטי. לדוגמה, נניח שיש משפט ואחריו משפט עם מסיכה:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
מודל שפה גדול יכול ליצור הסתברויות למשפט עם המילה המוסתרת, כולל:
| Probability | מילה או מילים |
|---|---|
| 3.1% | לדוגמה, הוא יכול לשבת, להישאר במקום ולהתהפך. |
| 2.9% | לדוגמה, הוא יודע לשבת, להישאר במקום ולהתהפך. |
מודל LLM גדול מספיק יכול ליצור הסתברויות לפסקאות ולמאמרים שלמים. אפשר לחשוב על השאלות של המשתמשים למודל שפה גדול כעל המשפט 'נתון' ואחריו מסכה דמיונית. לדוגמה:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
מודל ה-LLM יוצר הסתברויות לתשובות אפשריות שונות.
דוגמה נוספת: מודל שפה גדול שאומן על מספר עצום של בעיות מילוליות במתמטיקה יכול ליצור רושם שהוא מבצע ניתוח מתמטי מורכב. אבל מודלי ה-LLM האלה בעצם רק משלימים אוטומטית הנחיה של בעיה מילולית.
היתרונות של מודלים גדולים של שפה (LLM)
מודלים גדולים של שפה יכולים ליצור טקסט ברור וקל להבנה למגוון רחב של קהלי יעד. מודלים של שפה גדולה יכולים לבצע חיזויים במשימות שהם אומנו עליהן באופן מפורש. חלק מהחוקרים טוענים שמודלים מסוג LLM יכולים גם ליצור תחזיות לגבי קלט שהם לא אומנו עליו באופן מפורש, אבל חוקרים אחרים דחו את הטענה הזו.
בעיות עם מודלים גדולים של שפה (LLM)
אימון של מודל שפה גדול כרוך בבעיות רבות, כולל:
- איסוף מערך אימון עצום.
- השימוש ב-Gemini צורך משאבים חישוביים עצומים וחשמל, ומתבסס על נתונים של כמה חודשים.
- פתרון בעיות שקשורות להרצה מקבילית.
שימוש במודלים גדולים של שפה כדי להסיק תחזיות גורם לבעיות הבאות:
- מודלי שפה גדולים מייצרים תגובות לא תואמות נתונים, כלומר התחזיות שלהם מכילות לעיתים קרובות טעויות.
- מודלי שפה גדולים צורכים כמויות עצומות של משאבי מחשוב וחשמל. בדרך כלל, אימון מודלים מסוג LLM על מערכי נתונים גדולים יותר מצמצם את כמות המשאבים שנדרשים להסקת מסקנות, אבל מערכי אימון גדולים יותר דורשים יותר משאבי אימון.
- כמו כל מודל ML, גם מודלים של LLM יכולים להציג כל מיני סוגים של הטיה.