नई टेक्नोलॉजी, लार्ज लैंग्वेज मॉडल (एलएलएम), टोकन या टोकन के क्रम का अनुमान लगाते हैं. कभी-कभी, अनुमानित टोकन कई पैराग्राफ़ के बराबर होते हैं. ध्यान रखें कि टोकन कोई शब्द, सबवर्ड (किसी शब्द का सबसेट) या कोई वर्ण भी हो सकता है. एलएलएम, एन-ग्राम लैंग्वेज मॉडल या रिकरंट न्यूरल नेटवर्क की तुलना में बेहतर अनुमान लगाते हैं. इसकी वजह यह है कि:
- एलएलएम में, रिकरंट मॉडल की तुलना में कहीं ज़्यादा पैरामीटर होते हैं.
- एलएलएम, ज़्यादा जानकारी इकट्ठा करते हैं.
इस सेक्शन में, एलएलएम बनाने के लिए सबसे ज़्यादा इस्तेमाल किए जाने वाले और सबसे असरदार आर्किटेक्चर के बारे में बताया गया है: ट्रांसफ़ॉर्मर.
ट्रांसफ़ॉर्मर क्या है?
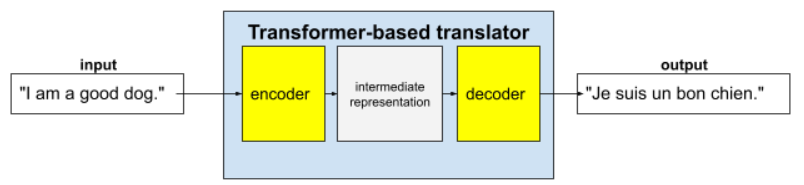
ट्रांसफ़ॉर्मर, कई तरह के लैंग्वेज मॉडल ऐप्लिकेशन के लिए सबसे बेहतरीन आर्किटेक्चर हैं. जैसे, अनुवाद करना:

पूरे ट्रांसफ़ॉर्मर में एक एन्कोडर और एक डिकोडर होता है:
- एनकोडर, इनपुट टेक्स्ट को इंटरमीडिएट फ़ॉर्मैट में बदलता है. एन्कोडर एक बहुत बड़ा न्यूरल नेट होता है.
- डिकोडर, उस इंटरमीडिएट रिप्रेजेंटेशन को काम के टेक्स्ट में बदलता है. डिकोडर भी एक बहुत बड़ा न्यूरल नेट होता है.
उदाहरण के लिए, अनुवादक में:
- एनकोडर, इनपुट टेक्स्ट (उदाहरण के लिए, अंग्रेज़ी का कोई वाक्य) को किसी इंटरमीडिएट फ़ॉर्मैट में बदलता है.
- डिकोडर, इंटरमीडिएट रिप्रज़ेंटेशन को आउटपुट टेक्स्ट में बदलता है. उदाहरण के लिए, फ़्रेंच में मौजूद वाक्य.
सेल्फ़-अटेंशन क्या है?
टेक्स्ट के कॉन्टेक्स्ट को बेहतर बनाने के लिए, ट्रांसफ़ॉर्मर सेल्फ़-अटेंशन नाम के कॉन्सेप्ट पर काफ़ी हद तक निर्भर करते हैं. असल में, हर इनपुट टोकन की ओर से, सेल्फ़-अटेंशन यह सवाल पूछता है:
"इनपुट के हर दूसरे टोकन का, इस टोकन की व्याख्या पर कितना असर पड़ता है?"
"सेल्फ़-अटेंशन" में "सेल्फ़" का मतलब इनपुट सीक्वेंस से है. अटेंशन मैकेनिज़्म के कुछ तरीके, इनपुट टोकन के संबंधों को आउटपुट सीक्वेंस में मौजूद टोकन के साथ तौलते हैं. जैसे, अनुवाद या किसी अन्य सीक्वेंस में मौजूद टोकन. हालांकि, सेल्फ़-अटेंशन सिर्फ़ इनपुट सीक्वेंस में मौजूद टोकन के बीच के संबंधों को ध्यान में रखता है.
आसानी से समझने के लिए, मान लें कि हर टोकन एक शब्द है और पूरा कॉन्टेक्स्ट सिर्फ़ एक वाक्य है. इस वाक्य पर ध्यान दें:
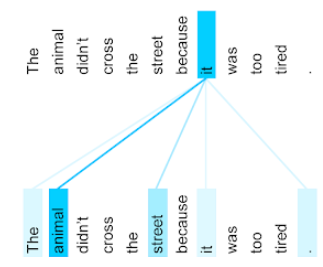
The animal didn't cross the street because it was too tired.
ऊपर दिए गए वाक्य में ग्यारह शब्द हैं. यहां दिए गए ग्यारह शब्दों में से हर शब्द, बाकी दस शब्दों पर ध्यान दे रहा है. साथ ही, यह सोच रहा है कि उन दस शब्दों में से हर शब्द उसके लिए कितना ज़रूरी है. उदाहरण के लिए, ध्यान दें कि वाक्य में सर्वनाम यह शामिल है. सर्वनाम अक्सर अस्पष्ट होते हैं. सर्वनाम it का इस्तेमाल आम तौर पर हाल ही में इस्तेमाल किए गए संज्ञा या संज्ञा वाक्यांश के लिए किया जाता है. हालांकि, उदाहरण के तौर पर दिए गए वाक्य में, it का इस्तेमाल हाल ही में इस्तेमाल की गई किस संज्ञा के लिए किया गया है—जानवर या सड़क?
सेल्फ़-अटेंशन मैकेनिज़्म से यह पता चलता है कि हर आस-पास का शब्द, सर्वनाम यह से कितना मिलता-जुलता है. तीसरी इमेज में नतीजे दिखाए गए हैं. लाइन जितनी नीली होगी, यह सर्वनाम के लिए वह शब्द उतना ही अहम होगा. इसका मतलब है कि सर्वनाम it के लिए, street की तुलना में animal ज़्यादा अहम है.
इसके उलट, मान लें कि वाक्य का आखिरी शब्द इस तरह बदलता है:
The animal didn't cross the street because it was too wide.
बदले गए इस वाक्य में, उम्मीद है कि सेल्फ-अटेंशन, सर्वनाम यह के लिए जानवर की तुलना में सड़क को ज़्यादा काम का मानेगा.
सेल्फ़-अटेंशन के कुछ तरीके द्विदिश होते हैं. इसका मतलब है कि वे उस शब्द से पहले और बाद आने वाले टोकन के लिए, काम के होने के स्कोर का हिसाब लगाते हैं जिस पर ध्यान दिया जा रहा है. उदाहरण के लिए, तीसरे डायग्राम में देखें कि it के दोनों ओर के शब्दों की जांच की गई है. इसलिए, दोनों दिशाओं में काम करने वाला सेल्फ़-अटेंशन मैकेनिज़्म, किसी शब्द के दोनों ओर मौजूद शब्दों से कॉन्टेक्स्ट इकट्ठा कर सकता है. इसके उलट, एकतरफ़ा सेल्फ़-अटेंशन मैकेनिज़्म, सिर्फ़ उन शब्दों से कॉन्टेक्स्ट इकट्ठा कर सकता है जो उस शब्द के एक तरफ़ मौजूद होते हैं जिस पर ध्यान दिया जा रहा है. दोनों दिशाओं में ध्यान देने की सुविधा, पूरी सीक्वेंस के बारे में जानकारी जनरेट करने के लिए खास तौर पर फ़ायदेमंद होती है. वहीं, टोकन-बाय-टोकन सीक्वेंस जनरेट करने वाले ऐप्लिकेशन के लिए, एक ही दिशा में ध्यान देने की सुविधा ज़रूरी होती है. इस वजह से, एनकोडर में दोनों दिशाओं में काम करने वाले सेल्फ़-अटेंशन का इस्तेमाल किया जाता है, जबकि डिकोडर में एक ही दिशा में काम करने वाले सेल्फ़-अटेंशन का इस्तेमाल किया जाता है.
मल्टी-हेड मल्टी-लेयर सेल्फ़-अटेंशन क्या है?
आम तौर पर, हर सेल्फ-अटेंशन लेयर में कई सेल्फ़-अटेंशन हेड होते हैं. किसी लेयर का आउटपुट, अलग-अलग हेड के आउटपुट पर की गई गणितीय कार्रवाई (उदाहरण के लिए, वेटेड एवरेज या डॉट प्रॉडक्ट) होता है.
हर हेड के पैरामीटर को रैंडम वैल्यू पर सेट किया जाता है. इसलिए, अलग-अलग हेड, हर शब्द और उसके आस-पास के शब्दों के बीच अलग-अलग संबंध सीख सकते हैं. उदाहरण के लिए, पिछले सेक्शन में बताए गए सेल्फ़-अटेंशन हेड का फ़ोकस, यह पता लगाने पर था कि सर्वनाम it किस संज्ञा के लिए इस्तेमाल किया गया है. हालांकि, उसी लेयर में मौजूद अन्य सेल्फ़-अटेंशन हेड, हर शब्द के लिए व्याकरण के हिसाब से सही शब्द के बारे में जान सकते हैं या अन्य इंटरैक्शन के बारे में जान सकते हैं.
एक ट्रांसफ़ॉर्मर मॉडल में, एक के ऊपर एक कई सेल्फ़-अटेंशन लेयर होती हैं. पिछली लेयर का आउटपुट, अगली लेयर के लिए इनपुट बन जाता है. इस स्टैकिंग की मदद से मॉडल, टेक्स्ट को ज़्यादा जटिल और अमूर्त तरीके से समझ पाता है. शुरुआती लेयर में, बुनियादी सिंटैक्स पर फ़ोकस किया जा सकता है. वहीं, डीपर लेयर में उस जानकारी को इंटिग्रेट किया जा सकता है, ताकि इनपुट के पूरे कॉन्टेंट में मौजूद बारीकियों को समझा जा सके. जैसे, भावना, संदर्भ, और थीम से जुड़े लिंक.
ट्रांसफ़ॉर्मर इतने बड़े क्यों होते हैं?
ट्रांसफ़ॉर्मर में, सैकड़ों अरब या खरबों पैरामीटर होते हैं. इस कोर्स में, आम तौर पर ज़्यादा पैरामीटर वाले मॉडल के बजाय कम पैरामीटर वाले मॉडल बनाने का सुझाव दिया गया है. आखिरकार, कम पैरामीटर वाले मॉडल को अनुमान लगाने के लिए, ज़्यादा पैरामीटर वाले मॉडल की तुलना में कम संसाधनों की ज़रूरत होती है. हालांकि, रिसर्च से पता चलता है कि ज़्यादा पैरामीटर वाले ट्रांसफ़ॉर्मर, कम पैरामीटर वाले ट्रांसफ़ॉर्मर से बेहतर परफ़ॉर्म करते हैं.
लेकिन, एलएलएम टेक्स्ट कैसे जनरेट करता है?
आपने देखा कि रिसर्चर, एलएलएम को किसी वाक्य में मौजूद एक या दो शब्दों का अनुमान लगाने के लिए ट्रेन करते हैं. हालांकि, आपको यह तरीका पसंद नहीं आया होगा. आखिरकार, एक या दो शब्दों का अनुमान लगाना, टेक्स्ट, ईमेल, और ऑथरिंग सॉफ़्टवेयर में पहले से मौजूद अपने-आप पूरा होने वाली सुविधा है. आपके मन में यह सवाल उठ रहा होगा कि एलएलएम, आर्बिट्राज के बारे में वाक्य, पैराग्राफ़ या हाइकु कैसे जनरेट कर सकते हैं.
दरअसल, एलएलएम, ऑटोकंप्लीट करने के ऐसे तरीके हैं जो हज़ारों टोकन का अपने-आप अनुमान लगा सकते हैं (पूरा कर सकते हैं). उदाहरण के लिए, इस वाक्य को देखें. इसके बाद, मास्क किया गया वाक्य देखें:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
एलएलएम, मास्क किए गए वाक्य के लिए ये संभावनाएं जनरेट कर सकता है:
| प्रॉबेबिलिटी | शब्द |
|---|---|
| 3.1% | उदाहरण के लिए, वह बैठ सकता है, रुक सकता है, और करवट ले सकता है. |
| 2.9% | उदाहरण के लिए, उसे बैठने, रुकने, और पलटने का तरीका पता है. |
एलएलएम काफ़ी बड़ा होने पर, पैराग्राफ़ और पूरे निबंध के लिए प्रॉबेबिलिटी जनरेट कर सकता है. किसी एलएलएम से उपयोगकर्ता के पूछे गए सवालों को "दिया गया" वाक्य माना जा सकता है. इसके बाद, एक काल्पनिक मास्क होता है. उदाहरण के लिए:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
एलएलएम, अलग-अलग जवाबों के लिए संभावनाएं जनरेट करता है.
एक अन्य उदाहरण के तौर पर, गणित की "इबारती समस्याओं" के आधार पर ट्रेन किए गए एलएलएम को, गणित के मुश्किल सवालों को हल करने में महारत हासिल हो सकती है. हालांकि, वे एलएलएम मूल रूप से, शब्द से जुड़ी समस्या के प्रॉम्प्ट को अपने-आप पूरा कर रहे हैं.
एलएलएम के फ़ायदे
एलएलएम, टारगेट ऑडियंस की अलग-अलग कैटगरी के लिए, आसानी से समझ में आने वाला टेक्स्ट जनरेट कर सकते हैं. एलएलएम, उन टास्क के बारे में अनुमान लगा सकते हैं जिनके लिए उन्हें ट्रेनिंग दी गई है. कुछ शोधकर्ताओं का दावा है कि एलएलएम, ऐसे इनपुट के लिए भी अनुमान लगा सकते हैं जिनके लिए उन्हें साफ़ तौर पर ट्रेनिंग नहीं दी गई है. हालांकि, अन्य शोधकर्ताओं ने इस दावे को खारिज कर दिया है.
एलएलएम से जुड़ी समस्याएं
एलएलएम को ट्रेन करने में कई समस्याएं आती हैं. इनमें ये समस्याएं शामिल हैं:
- ट्रेनिंग के लिए बहुत बड़ा डेटा सेट इकट्ठा करना.
- इसमें कई महीने लगते हैं. साथ ही, इसमें बहुत ज़्यादा कंप्यूटेशनल संसाधनों और बिजली की खपत होती है.
- पैरललिज़्म से जुड़ी समस्याओं को हल करना.
एलएलएम का इस्तेमाल करके, अनुमानों के बारे में अंदाज़ा लगाने से ये समस्याएं होती हैं:
- एलएलएम भ्रमित हो जाते हैं. इसका मतलब है कि उनके अनुमानों में अक्सर गलतियां होती हैं.
- एलएलएम को काम करने के लिए, बहुत ज़्यादा कंप्यूटेशनल रिसॉर्स और बिजली की ज़रूरत होती है. एलएलएम को बड़े डेटासेट पर ट्रेन करने से, अनुमान लगाने के लिए ज़रूरी संसाधनों की संख्या आम तौर पर कम हो जाती है. हालाँकि, बड़े ट्रेनिंग सेट के लिए ज़्यादा ट्रेनिंग संसाधनों की ज़रूरत होती है.
- सभी एमएल मॉडल की तरह, एलएलएम में भी हर तरह का पूर्वाग्रह दिख सकता है.