Una tecnologia più recente, i modelli linguistici di grandi dimensioni (LLM) prevedono un token o una sequenza di token, a volte molti paragrafi di token previsti. Ricorda che un token può essere una parola, una subword (un sottoinsieme di una parola) o anche un singolo carattere. Gli LLM fanno previsioni molto migliori rispetto ai modelli linguistici N-grammi o alle reti neurali ricorrenti perché:
- Gli LLM contengono molti più parametri rispetto ai modelli ricorrenti.
- Gli LLM raccolgono molti più contesti.
Questa sezione introduce l'architettura più efficace e ampiamente utilizzata per la creazione di LLM: Transformer.
Che cos'è un Transformer?
I Transformer sono l'architettura all'avanguardia per un'ampia gamma di applicazioni di modelli linguistici, come la traduzione:

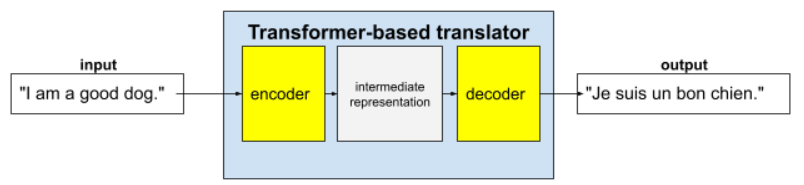
I Transformer completi sono costituiti da un encoder e un decoder:
- Un encoder converte il testo di input in una rappresentazione intermedia. Un encoder è un'enorme rete neurale.
- Un decoder converte questa rappresentazione intermedia in testo utile. Un decoder è anche un'enorme rete neurale.
Ad esempio, in un traduttore:
- Il codificatore elabora il testo di input (ad esempio, una frase in inglese) in una rappresentazione intermedia.
- Il decoder converte questa rappresentazione intermedia in testo di output (ad esempio, la frase equivalente in francese).
Che cos'è l'auto-attenzione?
Per migliorare il contesto, i Transformer si basano molto su un concetto chiamato auto-attenzione. In pratica, per conto di ogni token di input, l'auto-attenzione pone la seguente domanda:
"In che misura ogni altro token di input influisce sull'interpretazione di questo token?"
Il termine "auto" in "auto-attenzione" si riferisce alla sequenza di input. Alcuni meccanismi di attenzione ponderano le relazioni tra i token di input e i token in una sequenza di output, ad esempio una traduzione, o con i token in un'altra sequenza. Tuttavia, la self-attention valuta solo l'importanza delle relazioni tra i token nella sequenza di input.
Per semplificare le cose, supponi che ogni token sia una parola e che il contesto completo sia una sola frase. Considera la seguente frase:
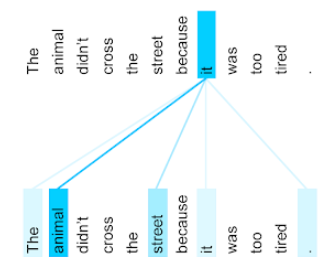
The animal didn't cross the street because it was too tired.
La frase precedente contiene undici parole. Ognuna delle undici parole presta attenzione alle altre dieci, chiedendosi quanto ciascuna di queste dieci parole sia importante per sé. Ad esempio, nota che la frase contiene il pronome it. I pronomi sono spesso ambigui. Il pronome it in genere si riferisce a un sostantivo o a una frase nominale recente, ma nella frase di esempio, a quale sostantivo recente si riferisce it: all'animale o alla strada?
Il meccanismo di auto-attenzione determina la pertinenza di ogni parola vicina rispetto al pronome it. La Figura 3 mostra i risultati: più la linea è blu, più la parola è importante per il pronome it. ovvero animal è più importante di street per il pronome it.
Supponiamo invece che l'ultima parola della frase cambi come segue:
The animal didn't cross the street because it was too wide.
In questa frase rivista, l'auto-attenzione dovrebbe valutare strada come più pertinente di animale rispetto al pronome it.
Alcuni meccanismi di auto-attenzione sono bidirezionali, il che significa che calcolano i punteggi di pertinenza per i token precedenti e successivi alla parola a cui viene prestata attenzione. Ad esempio, nella Figura 3, nota che vengono esaminate le parole su entrambi i lati di it. Pertanto, un meccanismo di self-attention bidirezionale può raccogliere il contesto dalle parole su entrambi i lati della parola a cui si presta attenzione. Al contrario, un meccanismo di self-attention unidirezionale può raccogliere il contesto solo dalle parole su un lato della parola a cui si presta attenzione. L'auto-attenzione bidirezionale è particolarmente utile per generare rappresentazioni di sequenze intere, mentre le applicazioni che generano sequenze token per token richiedono l'auto-attenzione unidirezionale. Per questo motivo, i codificatori utilizzano l'auto-attenzione bidirezionale, mentre i decodificatori utilizzano quella unidirezionale.
Che cos'è l'auto-attenzione multi-testa e multi-livello?
Ogni livello di auto-attenzione è in genere composto da più testine di auto-attenzione. L'output di un livello è un'operazione matematica (ad esempio, media ponderata o prodotto scalare) dell'output delle diverse teste.
Poiché i parametri di ogni testina vengono inizializzati con valori casuali, testine diverse possono apprendere relazioni diverse tra ogni parola a cui viene prestata attenzione e le parole vicine. Ad esempio, l'intestazione di self-attention descritta nella sezione precedente si concentrava sulla determinazione del sostantivo a cui si riferiva il pronome it. Tuttavia, altre teste di auto-attenzione all'interno dello stesso livello potrebbero apprendere la pertinenza grammaticale di ogni parola rispetto a tutte le altre o apprendere altre interazioni.
Un modello transformer completo impila più livelli di auto-attenzione uno sopra l'altro. L'output del livello precedente diventa l'input per il successivo. Questo stacking consente al modello di creare comprensioni del testo progressivamente più complesse e astratte. Mentre i livelli precedenti potrebbero concentrarsi sulla sintassi di base, i livelli più profondi possono integrare queste informazioni per comprendere concetti più sfumati come sentimento, contesto e collegamenti tematici nell'intero input.
Perché i Transformer sono così grandi?
I transformer contengono centinaia di miliardi o addirittura migliaia di miliardi di parametri. Questo corso ha generalmente consigliato di creare modelli con un numero inferiore di parametri rispetto a quelli con un numero maggiore di parametri. Dopo tutto, un modello con un numero inferiore di parametri utilizza meno risorse per fare previsioni rispetto a un modello con un numero maggiore di parametri. Tuttavia, la ricerca mostra che i Transformer con più parametri superano costantemente quelli con meno parametri.
Ma come fa un LLM a generare testo?
Hai visto come i ricercatori addestrano gli LLM a prevedere una o due parole mancanti e potresti non essere rimasto impressionato. Dopotutto, prevedere una o due parole è essenzialmente la funzionalità di completamento automatico integrata in vari software di testo, email e creazione. Ti starai chiedendo come gli LLM possano generare frasi, paragrafi o haiku sull'arbitraggio.
Infatti, gli LLM sono essenzialmente meccanismi di completamento automatico che possono prevedere (completare) automaticamente migliaia di token. Ad esempio, considera una frase seguita da una frase mascherata:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
Un LLM può generare probabilità per la frase mascherata, tra cui:
| Probabilità | Parola/e |
|---|---|
| 3,1% | Ad esempio, può sedersi, rimanere fermo e rotolare. |
| 2,9% | Ad esempio, sa sedersi, rimanere fermo e rotolare. |
Un LLM sufficientemente grande può generare probabilità per paragrafi e interi saggi. Puoi pensare alle domande di un utente a un LLM come alla frase "data" seguita da una maschera immaginaria. Ad esempio:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
L'LLM genera probabilità per varie risposte possibili.
Un altro esempio è un LLM addestrato su un numero elevatissimo di "problemi con enunciato" matematici, che può dare l'impressione di eseguire ragionamenti matematici sofisticati. Tuttavia, questi LLM si limitano a completare automaticamente un prompt di un problema di parole.
Vantaggi degli LLM
Gli LLM possono generare testi chiari e facili da capire per un'ampia varietà di segmenti di pubblico di destinazione. Gli LLM possono fare previsioni sulle attività per cui sono esplicitamente addestrati. Alcuni ricercatori sostengono che gli LLM possono anche fare previsioni per input su cui non sono stati addestrati in modo esplicito, ma altri ricercatori hanno confutato questa affermazione.
Problemi con gli LLM
L'addestramento di un LLM comporta molti problemi, tra cui:
- Raccolta di un enorme set di addestramento.
- Consumando più mesi ed enormi risorse di calcolo ed elettricità.
- Risoluzione dei problemi di parallelismo.
L'utilizzo di LLM per dedurre le previsioni causa i seguenti problemi:
- Gli LLM allucinano, il che significa che le loro previsioni contengono spesso errori.
- Gli LLM consumano enormi quantità di risorse di calcolo ed elettricità. L'addestramento degli LLM su set di dati più grandi in genere riduce la quantità di risorse richieste per l'inferenza, anche se i set di addestramento più grandi richiedono più risorse di addestramento.
- Come tutti i modelli di ML, gli LLM possono mostrare tutti i tipi di bias.