Сучасна технологія під назвою велика мовна модель прогнозує токен або послідовність токенів, іноді навіть багато абзаців токенів. Пам’ятайте, що токен може бути словом, підсловом (морфемою) або навіть одним символом. Великі мовні моделі створюють набагато кращі прогнози, ніж N-грамні мовні моделі або рекурентні нейронні мережі з таких причин:
- великі мовні моделі містять набагато більше параметрів, ніж рекурентні моделі;
- великі мовні моделі збирають набагато більше контексту.
У цьому розділі розглядається найуспішніша й найпоширеніша архітектура для побудови великих мовних моделей – трансформер.
Що таке трансформер?
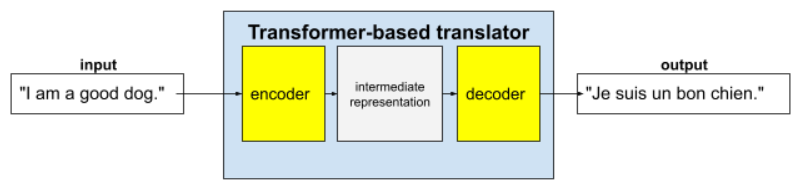
Трансформери – це найсучасніша архітектура для широкого спектра застосувань мовних моделей, наприклад для перекладу.

Повні трансформери складаються з кодера й декодера.
- Кодер перетворює вхідний текст на проміжне представлення. Кодер – це величезна нейронна мережа.
- Декодер перетворює це проміжне представлення на корисний текст. Декодер – це також величезна нейронна мережа.
Нижче описано, як вони працюють, на прикладі перекладача.
- Кодер перетворює вхідний текст (наприклад, речення англійською мовою) на певне проміжне представлення.
- Декодер перетворює це проміжне представлення на вихідний текст (наприклад, відповідне речення французькою мовою).
Що таке самоувага?
Щоб покращувати контекст, трансформери значною мірою покладаються на концепцію, яка називається самоувага. По суті, від імені кожного токена вхідних даних самоувага ставить таке запитання:
"Наскільки сильно кожен інший токен вхідних даних впливає на інтерпретацію цього токена?"
Префікс "само" в слові "самоувага" стосується вхідної послідовності. Деякі механізми уваги визначають відношення ваги токенів вхідної послідовності до токенів вихідної (наприклад, у перекладі) або якоїсь іншої послідовності. Але механізм самоуваги враховує лише важливість зв’язків між токенами у вхідній послідовності.
Щоб спростити приклад, припустімо, що кожен токен – це слово, а повний контекст – лише одне речення. Розгляньмо речення, наведене нижче.
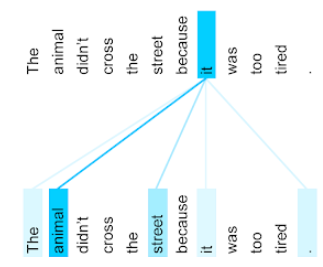
The animal didn't cross the street because it was too tired.
У цьому реченні одинадцять слів. Кожне слово звертає увагу на інші десять, замислюючись над тим, наскільки кожне з них важливе для нього. Наприклад, у реченні є займенник it. Займенники часто бувають неоднозначними. Займенник it зазвичай стосується попереднього іменника або іменникового словосполучення. Але якого попереднього іменника стосується it у цьому прикладі – animal (тварина) чи street (вулиця)?
Механізм самоуваги визначає відношення кожного сусіднього слова до займенника it. На рисунку 3 показано результати: що насиченіший синій колір лінії, то важливіше це слово для займенника it. Отже, для займенника it іменник animal важливіший, ніж street.
І навпаки, уявімо, що в реченні змінюється останнє слово:
The animal didn't cross the street because it was too wide.
Самоувага, можливо, визначить, що в зміненому реченні зв’язок слова street із займенником it доречніший, ніж слова animal.
Деякі механізми самоуваги є двосторонніми, тобто обчислюють бали доречності як для токенів, що передують слову, на якому зосереджується увага, так і токенів, що слідують за ним. Зверніть увагу, що, наприклад, на рисунку 3 досліджуються слова по обидва боки від займенника it. Отже, двосторонній механізм самоуваги може збирати контекст зі слів, розташованих по обидва боки від слова, на яке звертається увага. На противагу цьому, односторонній механізм самоуваги може збирати контекст лише зі слів, розташованих з одного боку від того, на яке звертається увага. Двостороння самоувага особливо корисна для створення представлень цілих послідовностей, тоді як для додатків, що генерують послідовності токен за токеном, потрібна одностороння самоувага. Через це кодери використовують двосторонні механізми самоуваги, а декодери – односторонні.
Що таке багатоголова самоувага?
Кожен шар самоуваги зазвичай складається з декількох голів самоуваги. Вихідні дані шару – це математична операція (наприклад, зважене середнє або склярний добуток) вихідних даних різних голів.
Оскільки кожен шар самоуваги ініціалізується за допомогою випадкових значень, різні голови можуть вивчати різні зв’язки між кожним словом, на яке звертається увага, і сусідніми словами. Наприклад, шар самоуваги, описаний у попередньому розділі, зосередився на визначенні того, до якого іменника відноситься займенник it. Однак інші шари самоуваги можуть вивчати, як кожне слово граматично пов’язане з будь-яким із решти слів, або досліджувати інші зв’язки.
Чому трансформери мають такий великий розмір?
У трансформерах містяться сотні мільярдів або навіть трильйони параметрів. У рамках цього курсу зазвичай рекомендується створювати моделі з меншою кількістю параметрів, а не з більшою, щоб модель використовувала менше ресурсів для прогнозування. Однак дослідження показують, що трансформери з більшою кількістю параметрів постійно показують кращі результати, ніж ті, які використовують менше параметрів.
Як велика мовна модель генерує текст?
Ви дізналися, як фахівці навчають великі мовні моделі прогнозувати пропущене слово чи два, і, можливо, це вас не вразило. Усе-таки прогнозування одного-двох слів – це, по суті, функція автозавершення, вбудована в різні текстові додатки, поштові клієнти й програмне забезпечення для авторів. Можливо, вам цікаво, як великі мовні моделі створюють речення, абзаци або хайку про арбітраж.
Фактично, великі мовні моделі – це механізми автозавершення, які можуть автоматично прогнозувати (завершувати) тисячі токенів. Розгляньмо речення, за яким іде замасковане речення:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
Велика мовна модель може генерувати ймовірні варіанти замаскованого речення, зокрема наведені нижче.
| Імовірність | Слова |
|---|---|
| 3,1% | For example, he can sit, stay, and roll over. (Наприклад, він може сидіти, стояти або перевертатися.) |
| 2,9% | For example, he knows how to sit, stay, and roll over. (Наприклад, він уміє сидіти, стояти й перевертатися.) |
Велика мовна модель достатнього розміру може генерувати ймовірні варіанти абзаців або цілих творів. Сприймайте запитання користувача до великої мовної моделі як "задане" речення, за яким іде умовна маска. Наприклад:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
Велика мовна модель генерує ймовірності для різних можливих відповідей.
Інший приклад: велика мовна модель, яка навчалася на безлічі математичних "текстових задач", може створювати видимість того, що вона займається складними математичними міркуваннями. Однак ці великі мовні моделі, по суті, просто автоматично завершують запит із текстовою задачею.
Переваги великих мовних моделей
Великі мовні моделі можуть створювати точні, легкі для сприйняття тексти для різних цільових аудиторій. Вони можуть робити прогнози в межах завдань, на яких їх спеціально навчали. Деякі дослідники стверджують, що великі мовні моделі також можуть робити прогнози на основі вхідних даних, для яких їх спеціально не навчали, але інші дослідники спростовують це твердження.
Проблеми, характерні для великих мовних моделей
Навчання великої мовної моделі пов’язане з багатьма проблемами, зокрема наведеними нижче.
- Потрібно зібрати величезну кількість даних для навчального набору.
- Необхідно працювати впродовж кількох місяців, а також забезпечити величезні обсяги обчислювальних ресурсів і електроенергії.
- Потрібно вирішувати проблеми паралелізму.
Застосування великих мовних моделей для прогнозування призводить до проблем, наведених нижче.
- Великі мовні моделі схильні до галюцинацій, а це означає, що в їх прогнозах часто трапляються помилки.
- Великі мовні моделі споживають величезну кількість обчислювальних ресурсів і електроенергії. Якщо навчати великі мовні моделі на більших наборах даних, зазвичай зменшується кількість ресурсів, необхідних для виведення. Хоча що більші навчальні набори, то більше ресурсів потрібно для тренування.
- Як і всі моделі машинного навчання, великі мовні моделі можуть виявляти упередженість різного роду.