Teknologi yang lebih baru, model bahasa besar (LLM) memprediksi token atau urutan token, terkadang token yang diprediksi bernilai banyak paragraf. Ingatlah bahwa token dapat berupa kata, subkata (subset dari kata), atau bahkan satu karakter. LLM membuat prediksi yang jauh lebih baik daripada model bahasa N-gram atau jaringan neural berulang karena:
- LLM berisi parameter yang jauh lebih banyak daripada model berulang.
- LLM mengumpulkan lebih banyak konteks.
Bagian ini memperkenalkan arsitektur yang paling berhasil dan banyak digunakan untuk membangun LLM: Transformer.
Apa itu Transformer?
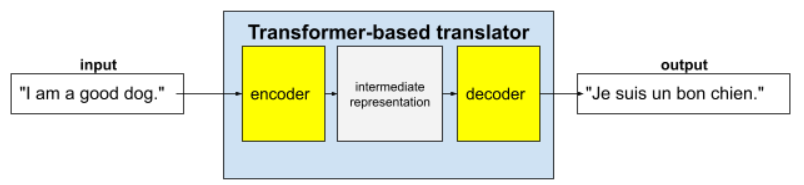
Transformer adalah arsitektur canggih untuk berbagai aplikasi model bahasa, seperti terjemahan:

Transformer lengkap terdiri dari encoder dan decoder:
- Encoder mengonversi teks input menjadi representasi perantara. Encoder adalah jaringan neural yang sangat besar.
- Dekoder mengonversi representasi perantara tersebut menjadi teks yang berguna. Decoder juga merupakan jaringan neural yang sangat besar.
Misalnya, di penerjemah:
- Encoder memproses teks input (misalnya, kalimat bahasa Inggris) menjadi beberapa representasi perantara.
- Decoder mengonversi representasi perantara tersebut menjadi teks output (misalnya, kalimat bahasa Prancis yang setara).
Apa itu self-attention?
Untuk meningkatkan konteks, Transformer sangat mengandalkan konsep yang disebut self-attention. Secara efektif, atas nama setiap token input, self-attention mengajukan pertanyaan berikut:
"Seberapa besar pengaruh setiap token input lainnya terhadap interpretasi token ini?"
"Self" dalam "self-attention" merujuk pada urutan input. Beberapa mekanisme perhatian menimbang hubungan token input dengan token dalam urutan output seperti terjemahan atau dengan token dalam urutan lain. Namun, self-attention hanya menimbang pentingnya hubungan antar-token dalam urutan input.
Untuk menyederhanakan, asumsikan bahwa setiap token adalah kata dan konteks lengkapnya hanya berupa satu kalimat. Pertimbangkan kalimat berikut:
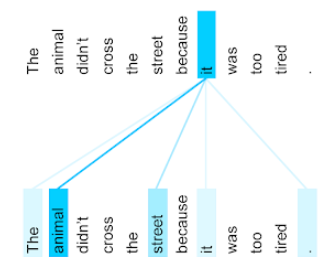
The animal didn't cross the street because it was too tired.
Kalimat sebelumnya berisi sebelas kata. Setiap dari sebelas kata tersebut memperhatikan sepuluh kata lainnya, bertanya-tanya seberapa penting setiap dari sepuluh kata tersebut bagi dirinya sendiri. Misalnya, perhatikan bahwa kalimat tersebut berisi kata ganti it. Pronomina sering kali ambigu. Kata ganti it biasanya merujuk pada kata benda atau frasa nomina baru-baru ini, tetapi dalam contoh kalimat, kata benda mana yang dirujuk oleh it—hewan atau jalan?
Mekanisme self-attention menentukan relevansi setiap kata di dekatnya dengan kata ganti it. Gambar 3 menunjukkan hasilnya—makin biru garisnya, makin penting kata tersebut bagi kata ganti it. Artinya, animal lebih penting daripada street untuk kata ganti it.
Sebaliknya, misalkan kata terakhir dalam kalimat berubah sebagai berikut:
The animal didn't cross the street because it was too wide.
Dalam kalimat yang direvisi ini, self-attention diharapkan menilai jalan sebagai lebih relevan daripada hewan dengan kata ganti itu.
Beberapa mekanisme perhatian mandiri bersifat bidireksional, yang berarti bahwa mekanisme tersebut menghitung skor relevansi untuk token sebelum dan setelah kata yang diperhatikan. Misalnya, dalam Gambar 3, perhatikan bahwa kata-kata di kedua sisi it diperiksa. Jadi, mekanisme self-attention dua arah dapat mengumpulkan konteks dari kata-kata di kedua sisi kata yang sedang diperhatikan. Sebaliknya, mekanisme self-attention satu arah hanya dapat mengumpulkan konteks dari kata-kata di satu sisi kata yang sedang diperhatikan. Self-attention dua arah sangat berguna untuk membuat representasi seluruh urutan, sementara aplikasi yang membuat urutan token demi token memerlukan self-attention satu arah. Oleh karena itu, encoder menggunakan self-attention dua arah, sedangkan decoder menggunakan satu arah.
Apa yang dimaksud dengan self-attention multi-layer multi-head?
Setiap lapisan self-attention biasanya terdiri dari beberapa kepala self-attention. Output lapisan adalah operasi matematika (misalnya, rata-rata berbobot atau produk titik) dari output head yang berbeda.
Karena parameter setiap head diinisialisasi ke nilai acak, head yang berbeda dapat mempelajari hubungan yang berbeda antara setiap kata yang diperhatikan dan kata-kata di sekitarnya. Misalnya, head self-attention yang dijelaskan di bagian sebelumnya berfokus pada penentuan kata benda mana yang dirujuk oleh kata ganti it. Namun, head self-attention lain dalam lapisan yang sama dapat mempelajari relevansi tata bahasa setiap kata dengan setiap kata lainnya, atau mempelajari interaksi lainnya.
Model transformer lengkap menumpuk beberapa lapisan self-attention di atas satu sama lain. Output dari lapisan sebelumnya menjadi input untuk lapisan berikutnya. Penumpukan ini memungkinkan model membangun pemahaman teks yang semakin kompleks dan abstrak secara progresif. Meskipun lapisan sebelumnya mungkin berfokus pada sintaksis dasar, lapisan yang lebih dalam dapat mengintegrasikan informasi tersebut untuk memahami konsep yang lebih bernuansa seperti sentimen, konteks, dan hubungan tematik di seluruh input.
Mengapa Transformer begitu besar?
Transformer berisi ratusan miliar atau bahkan triliunan parameter. Kursus ini umumnya merekomendasikan pembuatan model dengan jumlah parameter yang lebih kecil daripada model dengan jumlah parameter yang lebih besar. Bagaimanapun juga, model dengan jumlah parameter yang lebih kecil menggunakan lebih sedikit resource untuk membuat prediksi daripada model dengan jumlah parameter yang lebih besar. Namun, riset menunjukkan bahwa Transformer dengan lebih banyak parameter secara konsisten mengungguli Transformer dengan lebih sedikit parameter.
Namun, bagaimana cara LLM membuat teks?
Anda telah melihat cara peneliti melatih LLM untuk memprediksi satu atau dua kata yang hilang, dan Anda mungkin tidak terkesan. Bagaimanapun, memprediksi satu atau dua kata pada dasarnya adalah fitur pelengkapan otomatis yang ada di berbagai software teks, email, dan penulisan. Anda mungkin bertanya-tanya bagaimana LLM dapat membuat kalimat atau paragraf atau haiku tentang arbitrase.
Faktanya, LLM pada dasarnya adalah mekanisme pelengkapan otomatis yang dapat secara otomatis memprediksi (melengkapi) ribuan token. Misalnya, pertimbangkan kalimat yang diikuti dengan kalimat yang disamarkan:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
LLM dapat menghasilkan probabilitas untuk kalimat yang di-masking, termasuk:
| Probability | Kata |
|---|---|
| 3,1% | Misalnya, dia bisa duduk, diam, dan berguling. |
| 2,9% | Misalnya, dia tahu cara duduk, diam, dan berguling. |
LLM yang cukup besar dapat menghasilkan probabilitas untuk paragraf dan seluruh esai. Anda dapat menganggap pertanyaan pengguna kepada LLM sebagai kalimat "yang diberikan" yang diikuti dengan mask imajiner. Contoh:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM menghasilkan probabilitas untuk berbagai kemungkinan respons.
Sebagai contoh lain, LLM yang dilatih dengan sejumlah besar "soal cerita" matematika dapat memberikan kesan melakukan penalaran matematika yang canggih. Namun, LLM tersebut pada dasarnya hanya melengkapi otomatis perintah soal kata.
Manfaat LLM
LLM dapat menghasilkan teks yang jelas dan mudah dipahami untuk berbagai target audiens. LLM dapat membuat prediksi pada tugas yang secara eksplisit dilatih untuk tugas tersebut. Beberapa peneliti mengklaim bahwa LLM juga dapat membuat prediksi untuk input yang tidak dilatih secara eksplisit, tetapi peneliti lain telah membantah klaim ini.
Masalah terkait LLM
Melatih LLM menimbulkan banyak masalah, termasuk:
- Mengumpulkan set pelatihan yang sangat besar.
- Membutuhkan waktu beberapa bulan dan resource komputasi serta listrik yang sangat besar.
- Menyelesaikan tantangan paralelisme.
Menggunakan LLM untuk menyimpulkan prediksi menyebabkan masalah berikut:
- LLM berhalusinasi, artinya prediksinya sering kali mengandung kesalahan.
- LLM menggunakan resource komputasi dan listrik dalam jumlah yang sangat besar. Melatih LLM pada set data yang lebih besar biasanya mengurangi jumlah resource yang diperlukan untuk inferensi, meskipun set pelatihan yang lebih besar memerlukan lebih banyak resource pelatihan.
- Seperti semua model ML, LLM dapat menunjukkan berbagai jenis bias.