Eine neuere Technologie, Large Language Models (LLMs), sagt ein Token oder eine Folge von Tokens voraus, manchmal viele Absätze mit vorhergesagten Tokens. Ein Token kann ein Wort, ein Teilwort (eine Teilmenge eines Worts) oder sogar ein einzelnes Zeichen sein. LLMs treffen viel bessere Vorhersagen als N-Gramm-Sprachmodelle oder rekurrenten neuronalen Netze, weil:
- LLMs enthalten viel mehr Parameter als rekursiven Modelle.
- LLMs erfassen viel mehr Kontext.
In diesem Abschnitt wird die erfolgreichste und am weitesten verbreitete Architektur zum Erstellen von LLMs vorgestellt: der Transformer.
Was ist ein Transformer?
Transformer sind die modernste Architektur für eine Vielzahl von Anwendungen für Sprachmodelle, z. B. für die Übersetzung:

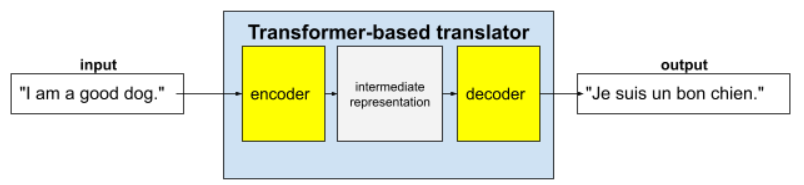
Vollständige Transformer bestehen aus einem Encoder und einem Decoder:
- Ein Encoder wandelt Eingabetext in eine Zwischenrepräsentation um. Ein Encoder ist ein riesiges neuronales Netzwerk.
- Ein Decoder wandelt diese Zwischenrepräsentation in nützlichen Text um. Ein Decoder ist auch ein riesiges neuronales Netzwerk.
Zum Beispiel in einem Übersetzer:
- Der Encoder verarbeitet den Eingabetext (z. B. einen englischen Satz) in eine Zwischenrepräsentation.
- Der Decoder wandelt diese Zwischenrepräsentation in Ausgabetext um (z. B. den entsprechenden französischen Satz).
Was ist Selbstaufmerksamkeit?
Um den Kontext zu verbessern, stützen sich Transformer stark auf das Konzept der Self-Attention. Im Grunde wird bei der Self-Attention für jedes Eingabetoken die folgende Frage gestellt:
„Wie stark beeinflusst jedes andere Eingabetoken die Interpretation dieses Tokens?“
Das „Self“ in „Self-Attention“ bezieht sich auf die Eingabesequenz. Einige Aufmerksamkeitsmechanismen gewichten Beziehungen von Eingabetokens zu Tokens in einer Ausgabesequenz, z. B. einer Übersetzung, oder zu Tokens in einer anderen Sequenz. Bei der Selbstaufmerksamkeit wird jedoch nur die Bedeutung von Beziehungen zwischen Tokens in der Eingabesequenz berücksichtigt.
Der Einfachheit halber gehen wir davon aus, dass jedes Token ein Wort ist und der gesamte Kontext nur einen einzigen Satz umfasst. Betrachten Sie den folgenden Satz:
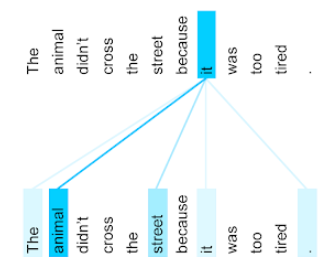
The animal didn't cross the street because it was too tired.
Der vorherige Satz enthält elf Wörter. Jedes der elf Wörter achtet auf die anderen zehn und fragt sich, wie wichtig jedes dieser zehn Wörter für sich selbst ist. Beachten Sie beispielsweise, dass der Satz das Pronomen it enthält. Pronomen sind oft mehrdeutig. Das Pronomen it bezieht sich in der Regel auf ein kürzlich genanntes Substantiv oder eine Nominalphrase. Auf welches Substantiv bezieht sich it im Beispielsatz – das Tier oder die Straße?
Der Self-Attention-Mechanismus bestimmt die Relevanz jedes nahegelegenen Wortes für das Pronomen es. Abbildung 3 zeigt die Ergebnisse. Je blauer die Linie, desto wichtiger ist das Wort für das Pronomen es. Das heißt, Tier ist für das Pronomen es wichtiger als Straße.
Angenommen, das letzte Wort im Satz ändert sich wie folgt:
The animal didn't cross the street because it was too wide.
Im überarbeiteten Satz würde die Selbstaufmerksamkeit street hoffentlich als relevanter für das Pronomen it einstufen als animal.
Einige Self-Attention-Mechanismen sind bidirektional. Das bedeutet, dass sie Relevanzwerte für Tokens berechnen, die dem Wort, auf das sich die Aufmerksamkeit richtet, vorangehen und folgen. In Abbildung 3 werden beispielsweise Wörter auf beiden Seiten von it untersucht. Ein bidirektionaler Selbstaufmerksamkeitsmechanismus kann also Kontext aus Wörtern auf beiden Seiten des Wortes erfassen, auf das sich die Aufmerksamkeit richtet. Im Gegensatz dazu kann ein unidirektionaler Selbstaufmerksamkeitsmechanismus nur Kontext aus Wörtern auf einer Seite des Wortes erfassen, auf das sich die Aufmerksamkeit richtet. Bidirektionale Self-Attention ist besonders nützlich, um Darstellungen ganzer Sequenzen zu generieren. Anwendungen, die Sequenzen Token für Token generieren, erfordern unidirektionale Self-Attention. Aus diesem Grund verwenden Encoder bidirektionale Self-Attention, während Decoder unidirektionale Self-Attention verwenden.
Was ist mehrköpfige, mehrschichtige Selbstaufmerksamkeit?
Jeder Selbstaufmerksamkeitslayer besteht in der Regel aus mehreren Selbstaufmerksamkeitsköpfen. Die Ausgabe einer Ebene ist eine mathematische Operation (z. B. gewichteter Durchschnitt oder Skalarprodukt) der Ausgabe der verschiedenen Köpfe.
Da die Parameter der einzelnen Köpfe mit zufälligen Werten initialisiert werden, können verschiedene Köpfe unterschiedliche Beziehungen zwischen jedem Wort, auf das geachtet wird, und den benachbarten Wörtern lernen. Der im vorherigen Abschnitt beschriebene Self-Attention-Head konzentrierte sich beispielsweise darauf, welches Nomen sich auf das Pronomen es bezog. Andere Self-Attention-Heads in derselben Ebene können jedoch die grammatische Relevanz jedes Worts für jedes andere Wort oder andere Interaktionen lernen.
Ein vollständiges Transformer-Modell stapelt mehrere Self-Attention-Schichten übereinander. Die Ausgabe der vorherigen Ebene wird zur Eingabe für die nächste. Durch diese Stapelung kann das Modell nach und nach komplexere und abstraktere Interpretationen des Texts entwickeln. Während sich frühere Ebenen möglicherweise auf die grundlegende Syntax konzentrieren, können tiefere Ebenen diese Informationen integrieren, um differenziertere Konzepte wie Stimmung, Kontext und thematische Verbindungen im gesamten Input zu erfassen.
Warum sind Transformer so groß?
Transformer enthalten Hunderte von Milliarden oder sogar Billionen von Parametern. In diesem Kurs wurde generell empfohlen, Modelle mit einer geringeren Anzahl von Parametern zu erstellen. Ein Modell mit einer geringeren Anzahl von Parametern benötigt schließlich weniger Ressourcen für Vorhersagen als ein Modell mit einer größeren Anzahl von Parametern. Studien zeigen jedoch, dass Transformer mit mehr Parametern durchweg besser abschneiden als Transformer mit weniger Parametern.
Aber wie generiert ein LLM Text?
Sie haben gesehen, wie Forscher LLMs trainieren, um ein oder zwei fehlende Wörter vorherzusagen, und sind vielleicht nicht beeindruckt. Schließlich ist die Vorhersage von ein oder zwei Wörtern im Grunde die Autovervollständigungsfunktion, die in verschiedene Text-, E‑Mail- und Autorensoftware integriert ist. Sie fragen sich vielleicht, wie LLMs Sätze, Absätze oder Haikus über Arbitrage generieren können.
LLMs sind im Grunde Autovervollständigungsmechanismen, die automatisch Tausende von Tokens vorhersagen (vervollständigen) können. Betrachten Sie beispielsweise einen Satz, gefolgt von einem maskierten Satz:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
Ein LLM kann Wahrscheinlichkeiten für den maskierten Satz generieren, darunter:
| Probability | Wort(e) |
|---|---|
| 3,1 % | Er kann beispielsweise sitzen, bleiben und sich auf den Rücken legen. |
| 2,9 % | Er kann zum Beispiel sitzen, bleiben und sich auf den Rücken legen. |
Ein ausreichend großes LLM kann Wahrscheinlichkeiten für Absätze und ganze Essays generieren. Die Fragen eines Nutzers an ein LLM können als der „gegebene“ Satz gefolgt von einer imaginären Maske betrachtet werden. Beispiel:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
Das LLM generiert Wahrscheinlichkeiten für verschiedene mögliche Antworten.
Ein weiteres Beispiel: Ein LLM, das mit einer großen Anzahl mathematischer Textaufgaben trainiert wurde, kann den Anschein erwecken, dass es komplexe mathematische Schlussfolgerungen zieht. Diese LLMs vervollständigen jedoch im Grunde nur einen Prompt für eine Rechenaufgabe.
Vorteile von LLMs
LLMs können klaren, leicht verständlichen Text für eine Vielzahl von Zielgruppen generieren. LLMs können Vorhersagen für Aufgaben treffen, für die sie explizit trainiert wurden. Einige Forscher behaupten, dass LLMs auch Vorhersagen für Eingaben treffen können, mit denen sie nicht explizit trainiert wurden. Andere Forscher haben diese Behauptung jedoch widerlegt.
Probleme mit LLMs
Das Trainieren eines LLM birgt viele Probleme, darunter:
- Zusammenstellung eines riesigen Trainingssets.
- Die Entwicklung hat mehrere Monate gedauert und enorme Rechenressourcen und Strom verbraucht.
- Lösen von Parallelitätsproblemen.
Wenn LLMs verwendet werden, um Vorhersagen zu inferieren, treten die folgenden Probleme auf:
- LLMs halluzinieren, d. h., ihre Vorhersagen enthalten oft Fehler.
- LLMs verbrauchen enorme Mengen an Rechenressourcen und Strom. Wenn Sie LLMs mit größeren Datasets trainieren, sinkt in der Regel die Menge an Ressourcen, die für die Inferenz erforderlich sind. Allerdings sind für größere Trainingssets mehr Trainingsressourcen erforderlich.
- Wie alle ML-Modelle können auch LLMs alle Arten von Bias aufweisen.