Uma tecnologia mais recente, os modelos de linguagem grande (LLMs), prevê um token ou uma sequência de tokens, às vezes muitos parágrafos de tokens previstos. Um token pode ser uma palavra, uma subpalavra (um subconjunto de uma palavra) ou até mesmo um único caractere. Os LLMs fazem previsões muito melhores do que os modelos de linguagem N-gram ou as redes neurais recorrentes porque:
- Os LLMs contêm muito mais parâmetros do que os modelos recorrentes.
- Os LLMs coletam muito mais contexto.
Esta seção apresenta a arquitetura mais bem-sucedida e amplamente usada para criar LLMs: o Transformer.
O que é um transformador?
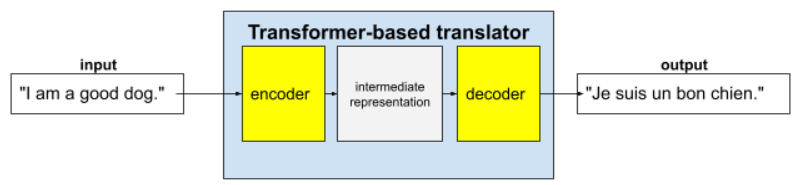
Os transformadores são a arquitetura mais moderna para uma ampla variedade de aplicativos de modelo de linguagem, como tradução:

Os transformadores completos consistem em um codificador e um decodificador:
- Um codificador converte o texto de entrada em uma representação intermediária. Um codificador é uma enorme rede neural.
- Um decodificador converte essa representação intermediária em texto útil. Um decodificador também é uma rede neural enorme.
Por exemplo, em um tradutor:
- O codificador processa o texto de entrada (por exemplo, uma frase em inglês) em alguma representação intermediária.
- O decodificador converte essa representação intermediária em texto de saída (por exemplo, a frase equivalente em francês).
O que é autoatenção?
Para melhorar o contexto, os transformadores dependem muito de um conceito chamado autoatenção. Na prática, em nome de cada token de entrada, a autoatenção faz a seguinte pergunta:
"Quanto cada outro token de entrada afeta a interpretação deste token?"
O "auto" em "autoatenção" se refere à sequência de entrada. Alguns mecanismos de atenção ponderam as relações de tokens de entrada com tokens em uma sequência de saída, como uma tradução, ou com tokens em alguma outra sequência. Mas a autoatenção só pesa a importância das relações entre tokens na sequência de entrada.
Para simplificar, suponha que cada token seja uma palavra e que o contexto completo seja apenas uma frase. Considere a seguinte frase:
The animal didn't cross the street because it was too tired.
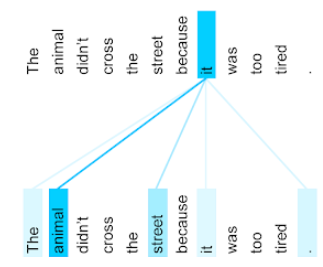
A frase anterior tem onze palavras. Cada uma das 11 palavras está prestando atenção nas outras 10, pensando em quanto cada uma delas é importante para si mesma. Por exemplo, observe que a frase contém o pronome it. Os pronomes costumam ser ambíguos. O pronome ele geralmente se refere a um substantivo ou sintagma nominal recente, mas na frase de exemplo, a qual substantivo recente ele se refere: ao animal ou à rua?
O mecanismo de autoatenção determina a relevância de cada palavra próxima para o pronome ele. A Figura 3 mostra os resultados. Quanto mais azul a linha, mais importante é essa palavra para o pronome it. Ou seja, animal é mais importante que rua para o pronome ele.
Por outro lado, suponha que a última palavra da frase mude da seguinte forma:
The animal didn't cross the street because it was too wide.
Nessa frase revisada, a autoatenção classificaria rua como mais relevante do que animal para o pronome ele.
Alguns mecanismos de autoatenção são bidirecionais, ou seja, eles calculam pontuações de relevância para tokens anteriores e posteriores à palavra que está sendo atendida. Por exemplo, na Figura 3, observe que as palavras dos dois lados de it são examinadas. Assim, um mecanismo bidirecional de autoatenção pode coletar contexto de palavras em ambos os lados da palavra que está sendo atendida. Por outro lado, um mecanismo de autoatenção unidirecional só pode coletar contexto de palavras em um lado da palavra que está sendo atendida. A atenção própria bidirecional é especialmente útil para gerar representações de sequências inteiras, enquanto aplicativos que geram sequências token por token exigem atenção própria unidirecional. Por isso, os codificadores usam a atenção própria bidirecional, enquanto os decodificadores usam a unidirecional.
O que é autoatenção multihead e multicamada?
Cada camada de autoatenção normalmente é composta por várias cabeças de autoatenção. A saída de uma camada é uma operação matemática (por exemplo, média ponderada ou produto escalar) da saída dos diferentes cabeçotes.
Como os parâmetros de cada cabeçalho são inicializados com valores aleatórios, cabeçalhos diferentes podem aprender relações diferentes entre cada palavra atendida e as palavras próximas. Por exemplo, o cabeçalho de autoatenção descrito na seção anterior se concentrou em determinar a qual substantivo o pronome it se referia. No entanto, outras cabeças de autoatenção na mesma camada podem aprender a relevância gramatical de cada palavra para todas as outras ou aprender outras interações.
Um modelo de transformador completo empilha várias camadas de autoatenção umas sobre as outras. A saída da camada anterior se torna a entrada da próxima. Esse empilhamento permite que o modelo crie entendimentos progressivamente mais complexos e abstratos do texto. Enquanto as camadas anteriores podem se concentrar na sintaxe básica, as mais profundas podem integrar essas informações para entender conceitos mais sutis, como sentimento, contexto e links temáticos em toda a entrada.
Por que os Transformers são tão grandes?
Os Transformers contêm centenas de bilhões ou até trilhões de parâmetros. Em geral, este curso recomendou criar modelos com um número menor de parâmetros em vez de um número maior. Afinal, um modelo com um número menor de parâmetros usa menos recursos para fazer previsões do que um modelo com um número maior de parâmetros. No entanto, pesquisas mostram que os Transformers com mais parâmetros têm um desempenho consistentemente melhor do que aqueles com menos parâmetros.
Mas como um LLM gera texto?
Você já viu como os pesquisadores treinam LLMs para prever uma ou duas palavras que faltam, e talvez não tenha ficado impressionado. Afinal, prever uma ou duas palavras é essencialmente o recurso de preenchimento automático integrado a vários softwares de texto, e-mail e criação. Talvez você esteja se perguntando como os LLMs podem gerar frases, parágrafos ou haicais sobre arbitragem.
Na verdade, os LLMs são essencialmente mecanismos de preenchimento automático que podem prever (completar) milhares de tokens automaticamente. Por exemplo, considere uma frase seguida por uma frase mascarada:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
Um LLM pode gerar probabilidades para a frase mascarada, incluindo:
| Probabilidade | Palavra(s) |
|---|---|
| 3,1% | Por exemplo, ele pode sentar, ficar e rolar. |
| 2,9% | Por exemplo, ele sabe sentar, ficar e rolar. |
Um LLM grande o suficiente pode gerar probabilidades para parágrafos e ensaios inteiros. Pense nas perguntas de um usuário para um LLM como a frase "dada" seguida por uma máscara imaginária. Exemplo:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
O LLM gera probabilidades para várias respostas possíveis.
Como outro exemplo, um LLM treinado com um grande número de "problemas de palavras" matemáticos pode parecer estar fazendo um raciocínio matemático sofisticado. No entanto, esses LLMs basicamente apenas preenchem automaticamente um comando de problema de palavras.
Benefícios dos LLMs
Os LLMs podem gerar textos claros e fáceis de entender para uma ampla variedade de públicos-alvo. Os LLMs podem fazer previsões sobre tarefas para as quais foram treinados explicitamente. Alguns pesquisadores afirmam que os LLMs também podem fazer previsões para entradas em que não foram treinados explicitamente, mas outros pesquisadores refutaram essa afirmação.
Problemas com LLMs
Treinar um LLM envolve muitos problemas, incluindo:
- Reunir um conjunto de treinamento enorme.
- Consumindo vários meses e enormes recursos computacionais e eletricidade.
- Como resolver desafios de paralelismo.
Usar LLMs para inferir previsões causa os seguintes problemas:
- Os LLMs alucinam, ou seja, as previsões deles costumam ter erros.
- Os LLMs consomem quantidades enormes de recursos computacionais e eletricidade. Treinar LLMs em conjuntos de dados maiores geralmente reduz a quantidade de recursos necessários para a inferência, embora os conjuntos de treinamento maiores exijam mais recursos de treinamento.
- Como todos os modelos de ML, os LLMs podem apresentar todos os tipos de viés.