تتوقّع التكنولوجيا الأحدث، وهي النماذج اللغوية الكبيرة (LLM)، رمزًا مميزًا أو تسلسلاً من الرموز المميزة، وأحيانًا تتوقّع رموزًا مميزة تصل إلى عدة فقرات. تذكَّر أنّ الرمز المميّز يمكن أن يكون كلمة أو كلمة فرعية (مجموعة فرعية من كلمة) أو حتى حرفًا واحدًا. تقدّم النماذج اللغوية الكبيرة توقّعات أفضل بكثير من نماذج اللغة المستندة إلى N-gram أو الشبكات العصبونية المتكرّرة للأسباب التالية:
- تحتوي النماذج اللغوية الكبيرة على مَعلمات أكثر بكثير من النماذج المتكرّرة.
- تجمع النماذج اللغوية الكبيرة سياقًا أكبر بكثير.
يعرض هذا القسم البنية الأكثر نجاحًا والأكثر استخدامًا لإنشاء نماذج لغوية كبيرة، وهي Transformer.
ما هو المحوّل؟
تُعدّ بنية Transformer من أحدث البنى المتطوّرة لمجموعة كبيرة من تطبيقات النماذج اللغوية، مثل الترجمة:

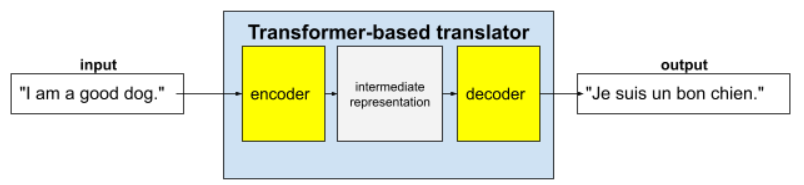
تتألف المحوّلات الكاملة من برنامج ترميز وبرنامج فك ترميز:
- يحوّل المشفِّر النص المدخل إلى تمثيل وسيط. برنامج الترميز هو شبكة عصبية ضخمة.
- يحوّل برنامج فك الترميز هذا التمثيل الوسيط إلى نص مفيد. والمفكك هو أيضًا شبكة عصبية ضخمة.
على سبيل المثال، في أداة ترجمة:
- تعالج أداة الترميز النص المدخل (على سبيل المثال، جملة باللغة الإنجليزية) وتحوّله إلى تمثيل وسيط.
- يحوّل برنامج الترميز هذا التمثيل الوسيط إلى نص ناتج (على سبيل المثال، الجملة الفرنسية المكافئة).
ما هي آلية الانتباه الذاتي؟
لتعزيز السياق، تعتمد المحوّلات بشكل كبير على مفهوم يُعرف باسم الانتباه الذاتي. في الواقع، نيابةً عن كل رمز مميز من رموز الإدخال، تطرح آلية الانتباه الذاتي السؤال التالي:
"ما مدى تأثير كل رمز مميز آخر من رموز الإدخال في تفسير هذا الرمز المميز؟"
تشير كلمة "ذاتي" في "الانتباه الذاتي" إلى تسلسل الإدخال. تُرجّح بعض آليات الانتباه أهمية العلاقات بين الرموز المميزة في الإدخال والرموز المميزة في تسلسل الإخراج، مثل الترجمة، أو الرموز المميزة في تسلسل آخر. لكنّ آلية الاهتمام الذاتي لا تأخذ في الاعتبار سوى أهمية العلاقات بين الرموز المميزة في تسلسل الإدخال.
لتبسيط الأمور، افترض أنّ كل رمز مميز هو كلمة وأنّ السياق الكامل هو جملة واحدة فقط. فكر في الجملة التالية:
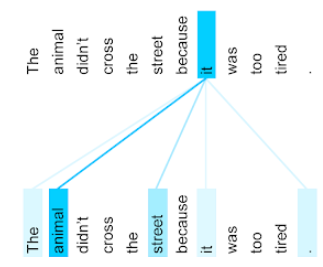
The animal didn't cross the street because it was too tired.
تحتوي الجملة السابقة على إحدى عشرة كلمة. تراقب كل كلمة من الكلمات الإحدى عشرة الكلمات العشر الأخرى، وتتساءل عن مدى أهمية كل كلمة من هذه الكلمات العشر بالنسبة إليها. على سبيل المثال، لاحظ أنّ الجملة تحتوي على الضمير it. غالبًا ما تكون الضمائر غامضة. يشير الضمير it عادةً إلى اسم أو عبارة اسمية حديثة، ولكن في الجملة النموذجية، إلى أي اسم حديث يشير الضمير it، إلى الحيوان أم إلى الشارع؟
تحدّد آلية الانتباه الذاتي مدى صلة كل كلمة قريبة بالضمير هو. يعرض الشكل 3 النتائج، فكلما كان الخط أزرق، زادت أهمية الكلمة بالنسبة إلى الضمير it. أي أنّ الحيوان أكثر أهمية من الشارع بالنسبة إلى الضمير هو.
في المقابل، لنفترض أنّ الكلمة الأخيرة في الجملة تتغيّر على النحو التالي:
The animal didn't cross the street because it was too wide.
في هذه الجملة المعدّلة، من المفترض أن يقيّم الانتباه الذاتي كلمة شارع على أنّها أكثر صلةً من كلمة حيوان بالضمير هو.
بعض آليات الانتباه الذاتي ثنائية الاتجاه، ما يعني أنّها تحسب درجات الملاءمة للرموز المميزة التي تسبق الكلمة التي يتم التركيز عليها والتي تليها. على سبيل المثال، في الشكل 3، لاحظ أنّه يتم فحص الكلمات على جانبي it. وبالتالي، يمكن لآلية الانتباه الذاتي الثنائية الاتجاه جمع السياق من الكلمات على أي من جانبي الكلمة التي يتم التركيز عليها. في المقابل، لا يمكن لآلية الاهتمام الذاتي أحادي الاتجاه جمع السياق إلا من الكلمات الواقعة على أحد جانبي الكلمة التي يتم التركيز عليها. تكون ميزة الانتباه الذاتي الثنائي الاتجاه مفيدة بشكل خاص لإنشاء تمثيلات للتسلسلات الكاملة، بينما تتطلّب التطبيقات التي تنشئ تسلسلات رمزًا مميزًا تلو الآخر ميزة الانتباه الذاتي الأحادي الاتجاه. لهذا السبب، تستخدم برامج الترميز الانتباه الذاتي الثنائي الاتجاه، بينما تستخدم برامج فك الترميز الانتباه الذاتي الأحادي الاتجاه.
ما هي آلية الانتباه الذاتي المتعددة الطبقات والمتعددة الرؤوس؟
تتألف كل طبقة من طبقات الانتباه الذاتي عادةً من عدة رؤوس انتباه ذاتي. ويكون الناتج من الطبقة عملية رياضية (مثل المتوسط المرجّح أو الضرب النقطي) للناتج من الرؤوس المختلفة.
بما أنّ مَعلمات كل رأس يتم ضبطها مبدئيًا على قيم عشوائية، يمكن أن تتعلّم رؤوس مختلفة علاقات مختلفة بين كل كلمة يتم التركيز عليها والكلمات المجاورة. على سبيل المثال، ركّزت آلية الانتباه الذاتي الموضّحة في القسم السابق على تحديد الاسم الذي يشير إليه الضمير هو. ومع ذلك، قد تتعلّم رؤوس الاهتمام الذاتي الأخرى ضمن الطبقة نفسها مدى أهمية كل كلمة من الناحية النحوية بالنسبة إلى كل كلمة أخرى، أو تتعلّم تفاعلات أخرى.
يجمع نموذج المحوّل الكامل بين عدة طبقات من الانتباه الذاتي مكدّسة فوق بعضها البعض. يصبح الناتج من الطبقة السابقة هو المدخل للطبقة التالية. يتيح هذا الترتيب للنموذج بناء فهم أكثر تعقيدًا وتجريدًا للنص بشكل تدريجي. في حين أنّ الطبقات السابقة قد تركّز على البنية الأساسية، يمكن للطبقات الأعمق دمج هذه المعلومات لفهم مفاهيم أكثر دقة، مثل المشاعر والسياق والروابط الموضوعية في جميع المدخلات.
لماذا تكون نماذج Transformer كبيرة جدًا؟
تحتوي المحوّلات على مئات المليارات أو حتى تريليونات من المَعلمات. وقد أوصت هذه الدورة التدريبية بشكل عام بإنشاء نماذج تتضمّن عددًا أقل من المَعلمات مقارنةً بالنماذج التي تتضمّن عددًا أكبر من المَعلمات. ففي النهاية، يستخدم النموذج الذي يتضمّن عددًا أقل من المَعلمات موارد أقل لإجراء التوقّعات مقارنةً بالنموذج الذي يتضمّن عددًا أكبر من المَعلمات. ومع ذلك، تُظهر الأبحاث أنّ نماذج Transformer التي تتضمّن المزيد من المَعلمات تتفوّق باستمرار على تلك التي تتضمّن عددًا أقل من المَعلمات.
ولكن كيف ينشئ نموذج لغوي كبير نصًا؟
لقد رأيت كيف يدرّب الباحثون النماذج اللغوية الكبيرة على توقّع كلمة أو كلمتَين ناقصتَين، وقد لا تكون منبهرًا بذلك. ففي النهاية، إنّ توقّع كلمة أو كلمتين هو في الأساس ميزة الإكمال التلقائي المضمّنة في برامج مختلفة للنصوص والبريد الإلكتروني والتأليف. قد تتساءل كيف يمكن للنماذج اللغوية الكبيرة إنشاء جمل أو فقرات أو قصائد هايكو حول المراجحة.
في الواقع، النماذج اللغوية الكبيرة هي في الأساس آليات إكمال تلقائي يمكنها تلقائيًا توقّع (إكمال) آلاف الرموز المميزة. على سبيل المثال، ضع في اعتبارك جملة تليها جملة مخفية:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
يمكن للنموذج اللغوي الكبير إنشاء احتمالات للجملة المخفية، بما في ذلك:
| الاحتمالية | الكلمات |
|---|---|
| 3.1% | على سبيل المثال، يمكنه الجلوس والثبات والاستلقاء على ظهره. |
| 2.9% | على سبيل المثال، يعرف كيف يجلس ويبقى في مكانه ويتقلّب. |
يمكن لنموذج لغوي كبير بما يكفي إنشاء احتمالات للفقرات والمقالات بأكملها. يمكن اعتبار أسئلة المستخدمين الموجّهة إلى نموذج لغوي كبير بمثابة الجملة "المعطاة" متبوعة بقناع تخيّلي. على سبيل المثال:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
يُنشئ النموذج اللغوي الكبير احتمالات لردود مختلفة محتملة.
كمثال آخر، يمكن أن يظهر نموذج لغوي كبير تم تدريبه على عدد كبير من "المسائل الكلامية" الرياضية وكأنّه يجري عمليات استدلال رياضية معقّدة. ومع ذلك، فإنّ هذه النماذج اللغوية الكبيرة تقتصر على إكمال طلبات المسائل الكلامية تلقائيًا.
مزايا النماذج اللغوية الكبيرة
يمكن للنماذج اللغوية الكبيرة إنشاء نصوص واضحة وسهلة الفهم لمجموعة كبيرة من شرائح الجمهور المستهدَفة. يمكن للنماذج اللغوية الكبيرة تقديم توقّعات بشأن المهام التي تم تدريبها عليها بشكل صريح. يزعم بعض الباحثين أنّ النماذج اللغوية الكبيرة يمكنها أيضًا تقديم توقّعات بشأن البيانات التي لم يتم تدريبها عليها بشكل صريح، لكنّ باحثين آخرين دحضوا هذا الادعاء.
مشاكل متعلقة بالنماذج اللغوية الكبيرة
يتضمّن تدريب نموذج لغوي كبير العديد من المشاكل، بما في ذلك:
- جمع مجموعة تدريب ضخمة
- تستهلك هذه النماذج عدة أشهر وموارد حسابية هائلة وكهرباء.
- حلّ تحديات التوازي
يؤدي استخدام النماذج اللغوية الكبيرة للاستدلال على التوقعات إلى حدوث المشاكل التالية:
- تتسبب الهلوسة في نماذج اللغات الكبيرة، أي أنّ توقعاتها غالبًا ما تتضمّن أخطاء.
- تستهلك النماذج اللغوية الكبيرة كميات هائلة من موارد الحوسبة والكهرباء. يؤدي تدريب النماذج اللغوية الكبيرة على مجموعات بيانات أكبر عادةً إلى تقليل مقدار الموارد المطلوبة للاستدلال، على الرغم من أنّ مجموعات التدريب الأكبر تتطلّب المزيد من موارد التدريب.
- وكما هو الحال مع جميع نماذج تعلُّم الآلة، يمكن أن تتضمّن النماذج اللغوية الكبيرة جميع أنواع التحيزات.