一种较新的技术,即大语言模型 (LLM),可预测一个 token 或一系列 token,有时甚至可以预测相当于多个段落的 token。请注意,词元可以是字词、子字词(字词的子集),甚至是单个字符。LLM 的预测效果比 N-gram 语言模型或循环神经网络好得多,原因如下:
- LLM 包含的参数远多于循环模型。
- LLM 会收集更多上下文。
本部分将介绍用于构建 LLM 的最成功且应用最广泛的架构:Transformer。
什么是 Transformer?
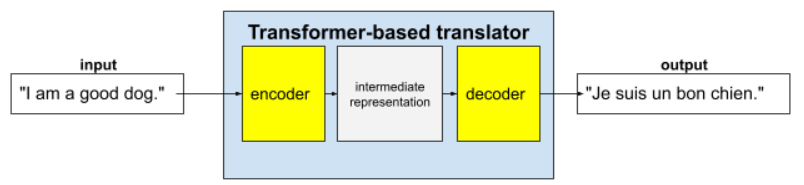
Transformer 是一种先进的架构,适用于各种语言模型应用,例如翻译:

完整的 Transformer 由编码器和解码器组成:
例如,在翻译器中:
- 编码器将输入文本(例如英语句子)处理为某种中间表示形式。
- 解码器会将该中间表示形式转换为输出文本(例如,等效的法语句子)。
什么是自注意力?
为了增强上下文理解能力,Transformer 很大程度上依赖于一种称为自注意力的概念。实际上,自注意力机制会针对输入的每个令牌提出以下问题:
“每个其他输入 token 对此 token 的解读有何影响?”
“自注意力”中的“自”是指输入序列。某些注意力机制会衡量输入词法单元与输出序列(例如翻译)中的词法单元或某些其他序列中的词法单元之间的关系。但自注意力机制仅衡量输入序列中词法单元之间关系的重要性。
为简单起见,假设每个词元都是一个字词,而完整上下文只是一句话。请看以下句子:
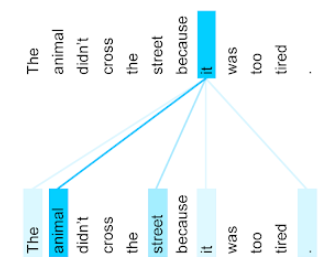
The animal didn't cross the street because it was too tired.
上句话包含 11 个字词。这 11 个字词中的每一个都在关注其他 10 个字词,想知道这 10 个字词对自己的重要程度。例如,请注意,该句子包含代词 it。代词通常比较含糊。代词 it 通常指代最近的名词或名词短语,但在示例句子中,it 指代的是哪个最近的名词,是动物还是街道?
自注意力机制可确定每个附近字词与代词 it 的相关性。图 3 显示了结果,线条越蓝,表示相应字词对代词“it”越重要。也就是说,对于代词 it,动物比街道更重要。
反之,假设句子中的最后一个字发生如下变化:
The animal didn't cross the street because it was too wide.
在这个修订后的句子中,自注意力机制有望将 street 评为比 animal 更贴近代词 it。
有些自注意力机制是双向的,这意味着它们会计算被关注字词之前和之后的令牌的相关性得分。例如,在图 3 中,请注意系统会检查 it 两侧的字词。因此,双向自注意力机制可以从被关注字词两侧的字词中收集上下文。相比之下,单向自注意力机制只能从被关注字词一侧的字词中收集上下文。双向自注意力机制对于生成整个序列的表示形式特别有用,而逐个生成序列令牌的应用则需要单向自注意力机制。因此,编码器使用双向自注意力,而解码器使用单向自注意力。
什么是多头多层自注意力机制?
每个自注意力层通常由多个自注意力头组成。层的输出是不同头的输出的数学运算(例如,加权平均值或点积)。
由于每个头的参数都初始化为随机值,因此不同的头可以学习被关注的每个字词与附近字词之间的不同关系。例如,上一部分中介绍的自注意力头侧重于确定代词“it”指的是哪个名词。不过,同一层中的其他自注意力头可能会学习每个字词与其他所有字词的语法相关性,或者学习其他互动。
完整的 Transformer 模型会将多个自注意力层堆叠在一起。前一层的输出会成为下一层的输入。 这种堆叠方式可让模型逐步构建对文本的更复杂、更抽象的理解。虽然较浅的层可能侧重于基本语法,但较深的层可以整合这些信息,以掌握更细致的概念,例如整个输入中的情感、上下文和主题链接。
为什么 Transformer 模型这么大?
Transformer 包含数千亿甚至数万亿个参数。本课程通常建议构建参数数量较少的模型,而不是参数数量较多的模型。毕竟,与参数较多的模型相比,参数较少的模型在进行预测时使用的资源更少。不过,研究表明,参数较多的 Transformer 始终优于参数较少的 Transformer。
但 LLM 如何生成文本?
您可能已经了解研究人员如何训练 LLM 来预测一两个缺失的字词,但可能对此并不感到惊讶。毕竟,预测一两个字基本上就是各种文本、电子邮件和创作软件中内置的自动补全功能。 您可能想知道 LLM 如何生成有关套利的句子、段落或俳句。
事实上,LLM 本质上是一种自动补全机制,可以自动预测(补全)数千个 token。例如,假设有一句句子,后面跟着一句被遮盖的句子:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
LLM 可以生成被遮盖句子的概率,包括:
| Probability | 字词 |
|---|---|
| 3.1% | 例如,他可以坐下、待在原地和翻滚。 |
| 2.9% | 例如,他知道如何坐下、待在原地和翻滚。 |
足够大的 LLM 可以生成段落和整篇文章的概率。您可以将用户向 LLM 提出的问题视为“给定”句子,后面跟随着一个假想的遮罩。例如:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM 会针对各种可能的回答生成概率。
再举一个例子,如果 LLM 接受过大量数学“文字题”的训练,那么它看起来就能进行复杂的数学推理。不过,这些 LLM 基本上只是自动补全文字题提示。
LLM 的优势
LLM 可以为各种目标受众群体生成清晰易懂的文本。LLM 可以针对明确训练过的任务做出预测。一些研究人员声称,LLM 还可以针对未明确训练过的输入做出预测,但其他研究人员驳斥了这一说法。
LLM 的问题
训练 LLM 会遇到许多问题,包括:
- 收集庞大的训练集。
- 耗费了数月时间和大量计算资源和电力。
- 解决并行处理难题。
使用 LLM 进行推理预测会导致以下问题:
- LLM 会产生幻觉,这意味着它们的预测通常包含错误。
- LLM 会消耗大量的计算资源和电力。 使用更大的数据集训练 LLM 通常会减少推理所需的资源量,不过更大的训练集会消耗更多训练资源。
- 与所有机器学习模型一样,LLM 可能会表现出各种各样的偏差。