Una tecnología más reciente, los modelos de lenguaje grandes (LLM), predice un token o una secuencia de tokens, a veces muchos párrafos de tokens predichos. Recuerda que un token puede ser una palabra, una subpalabra (un subconjunto de una palabra) o incluso un solo carácter. Los LLM realizan predicciones mucho mejores que los modelos de lenguaje de N-gramas o las redes neuronales recurrentes por los siguientes motivos:
- Los LLM contienen muchos más parámetros que los modelos recurrentes.
- Los LLM recopilan mucho más contexto.
En esta sección, se presenta la arquitectura más exitosa y utilizada para compilar LLMs: el Transformer.
¿Qué es un Transformer?
Los Transformers son la arquitectura más avanzada para una amplia variedad de aplicaciones de modelos de lenguaje, como la traducción:

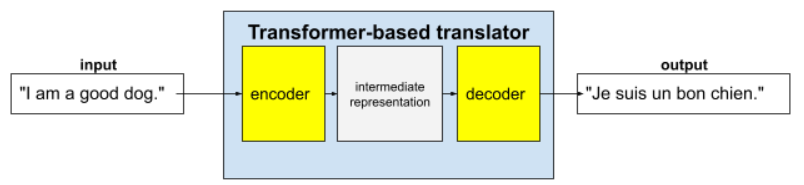
Los Transformers completos constan de un codificador y un decodificador:
- Un codificador convierte el texto de entrada en una representación intermedia. Un codificador es una enorme red neuronal.
- Un decodificador convierte esa representación intermedia en texto útil. Un decodificador también es una red neuronal enorme.
Por ejemplo, en un traductor:
- El codificador procesa el texto de entrada (por ejemplo, una oración en inglés) en alguna representación intermedia.
- El decodificador convierte esa representación intermedia en texto de salida (por ejemplo, la oración equivalente en francés).
¿Qué es la autoatención?
Para mejorar el contexto, los modelos Transformer se basan en gran medida en un concepto llamado autoatención. De manera efectiva, en nombre de cada token de entrada, la autoatención hace la siguiente pregunta:
"¿Cuánto afecta cada otro token de entrada a la interpretación de este token?"
El término "auto" en "autoatención" hace referencia a la secuencia de entrada. Algunos mecanismos de atención ponderan las relaciones de los tokens de entrada con los tokens de una secuencia de salida, como una traducción, o con los tokens de alguna otra secuencia. Sin embargo, la autoatención solo pondera la importancia de las relaciones entre los tokens de la secuencia de entrada.
Para simplificar las cosas, supón que cada token es una palabra y que el contexto completo es solo una oración. Considera la siguiente oración:
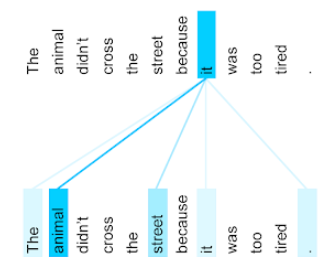
The animal didn't cross the street because it was too tired.
La oración anterior contiene once palabras. Cada una de las once palabras presta atención a las otras diez y se pregunta qué importancia tiene cada una de ellas para sí misma. Por ejemplo, observa que la oración contiene el pronombre it. Los pronombres suelen ser ambiguos. Por lo general, el pronombre it hace referencia a un sustantivo o una frase nominal recientes, pero, en la oración de ejemplo, ¿a qué sustantivo reciente hace referencia it: al animal o a la calle?
El mecanismo de autoatención determina la relevancia de cada palabra cercana para el pronombre it. En la figura 3, se muestran los resultados: cuanto más azul es la línea, más importante es esa palabra para el pronombre it. Es decir, animal es más importante que calle para el pronombre it.
Por el contrario, supongamos que la última palabra de la oración cambia de la siguiente manera:
The animal didn't cross the street because it was too wide.
En esta oración revisada, la autoatención debería calificar calle como más relevante que animal para el pronombre lo.
Algunos mecanismos de autoatención son bidireccionales, lo que significa que calculan las puntuaciones de relevancia para los tokens que preceden y siguen a la palabra a la que se presta atención. Por ejemplo, en la figura 3, observa que se examinan las palabras a ambos lados de it. Por lo tanto, un mecanismo de autoatención bidireccional puede recopilar contexto de las palabras a ambos lados de la palabra a la que se presta atención. Por el contrario, un mecanismo de autoatención unidireccional solo puede recopilar contexto de las palabras que se encuentran a un lado de la palabra a la que se presta atención. La autoatención bidireccional es especialmente útil para generar representaciones de secuencias completas, mientras que las aplicaciones que generan secuencias token por token requieren autoatención unidireccional. Por este motivo, los codificadores usan la autoatención bidireccional, mientras que los decodificadores usan la unidireccional.
¿Qué es la autoatención multicabezal y multicapa?
Por lo general, cada capa de autoatención se compone de varios cabezales de autoatención. El resultado de una capa es una operación matemática (por ejemplo, promedio ponderado o producto escalar) del resultado de los diferentes encabezados.
Dado que los parámetros de cada encabezado se inicializan con valores aleatorios, los diferentes encabezados pueden aprender diferentes relaciones entre cada palabra a la que se presta atención y las palabras cercanas. Por ejemplo, el encabezado de autoatención descrito en la sección anterior se centró en determinar a qué sustantivo se refería el pronombre it. Sin embargo, otros encabezados de autoatención dentro de la misma capa pueden aprender la relevancia gramatical de cada palabra para todas las demás, o bien aprender otras interacciones.
Un modelo Transformer completo apila varias capas de autoatención una sobre otra. La salida de la capa anterior se convierte en la entrada de la siguiente. Este apilamiento permite que el modelo cree comprensiones del texto progresivamente más complejas y abstractas. Si bien las capas anteriores pueden enfocarse en la sintaxis básica, las capas más profundas pueden integrar esa información para comprender conceptos más matizados, como el sentimiento, el contexto y los vínculos temáticos en toda la entrada.
¿Por qué los Transformers son tan grandes?
Los Transformers contienen cientos de miles de millones o incluso billones de parámetros. En general, en este curso se recomienda crear modelos con una menor cantidad de parámetros en lugar de aquellos con una mayor cantidad. Después de todo, un modelo con una menor cantidad de parámetros usa menos recursos para generar predicciones que un modelo con una mayor cantidad de parámetros. Sin embargo, las investigaciones demuestran que los transformadores con más parámetros superan de forma constante a los que tienen menos parámetros.
Pero ¿cómo genera texto un LLM?
Viste cómo los investigadores entrenan a los LLM para predecir una o dos palabras faltantes, y es posible que no te haya impresionado. Después de todo, predecir una o dos palabras es esencialmente la función de autocompletar integrada en varios softwares de texto, correo electrónico y creación. Es posible que te preguntes cómo los LLM pueden generar oraciones, párrafos o haikus sobre el arbitraje.
De hecho, los LLM son, en esencia, mecanismos de autocompletar que pueden predecir (completar) automáticamente miles de tokens. Por ejemplo, considera una oración seguida de una oración enmascarada:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
Un LLM puede generar probabilidades para la oración enmascarada, incluidas las siguientes:
| Probabilidad | Palabra(s) |
|---|---|
| 3.1% | Por ejemplo, puede sentarse, quedarse y darse la vuelta. |
| 2.9% | Por ejemplo, sabe cómo sentarse, quedarse quieto y darse la vuelta. |
Un LLM lo suficientemente grande puede generar probabilidades para párrafos y ensayos completos. Puedes considerar las preguntas de un usuario a un LLM como la oración "dada" seguida de una máscara imaginaria. Por ejemplo:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
El LLM genera probabilidades para varias respuestas posibles.
Como otro ejemplo, un LLM entrenado con una gran cantidad de "problemas verbales" matemáticos puede dar la apariencia de realizar un razonamiento matemático sofisticado. Sin embargo, esos LLM básicamente solo completan automáticamente una instrucción de problema de palabras.
Beneficios de los LLMs
Los LLM pueden generar texto claro y fácil de entender para una amplia variedad de públicos objetivo. Los LLMs pueden hacer predicciones sobre las tareas para las que se entrenaron de forma explícita. Algunos investigadores afirman que los LLM también pueden hacer predicciones para las entradas con las que no se entrenaron de forma explícita, pero otros investigadores refutaron esta afirmación.
Problemas con los LLMs
Entrenar un LLM implica muchos problemas, incluidos los siguientes:
- Recopilación de un enorme conjunto de entrenamiento
- Consumen varios meses y enormes recursos de procesamiento y electricidad.
- Resolver desafíos de paralelismo.
Usar LLMs para inferir predicciones causa los siguientes problemas:
- Los LLMs alucinan, lo que significa que sus predicciones suelen contener errores.
- Los LLM consumen enormes cantidades de recursos de procesamiento y electricidad. Por lo general, entrenar LLMs con conjuntos de datos más grandes reduce la cantidad de recursos necesarios para la inferencia, aunque los conjuntos de entrenamiento más grandes requieren más recursos de entrenamiento.
- Al igual que todos los modelos de AA, los LLM pueden mostrar todo tipo de sesgos.