Daha yeni bir teknoloji olan büyük dil modelleri (LLM'ler), bir jetonu veya jeton dizisini (bazen birçok paragraf değerinde tahmini jeton) tahmin eder. Bir jetonun kelime, alt kelime (kelimenin bir alt kümesi) veya tek bir karakter olabileceğini unutmayın. LLM'ler, N-gram dil modellerine veya tekrarlayan nöral ağlara kıyasla çok daha iyi tahminler yapar. Bunun nedeni:
- Büyük dil modelleri, yinelemeli modellerden çok daha fazla parametre içerir.
- Büyük dil modelleri çok daha fazla bağlam bilgisi toplar.
Bu bölümde, LLM'ler oluşturmak için en başarılı ve yaygın olarak kullanılan mimari olan Transformer tanıtılmaktadır.
Transformer nedir?
Dönüştürücüler, çeviri gibi çok çeşitli dil modeli uygulamaları için en gelişmiş mimaridir:

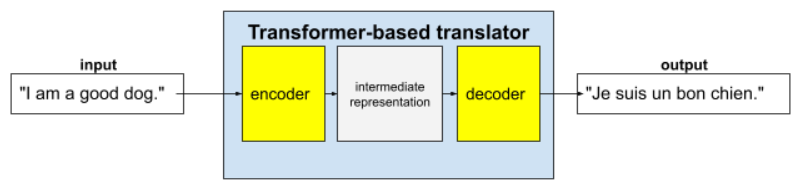
Tam dönüştürücüler, bir kodlayıcı ve bir kod çözücüden oluşur:
- Kodlayıcı, giriş metnini ara temsile dönüştürür. Kodlayıcı, çok büyük bir nöral ağdır.
- Kod çözücü, bu ara gösterimi faydalı metne dönüştürür. Kod çözücü de çok büyük bir nöral ağdır.
Örneğin, bir çeviride:
- Kodlayıcı, giriş metnini (örneğin, İngilizce bir cümle) ara temsile dönüştürür.
- Kod çözücü, bu ara gösterimi çıkış metnine (örneğin, eşdeğer Fransızca cümle) dönüştürür.
Öz dikkat nedir?
Dönüştürücüler, bağlamı geliştirmek için öz dikkat adı verilen bir kavramdan yoğun bir şekilde yararlanır. Özünde, her giriş jetonu adına self-attention aşağıdaki soruyu sorar:
"Girişin diğer her bir jetonu, bu jetonun yorumlanmasını ne kadar etkiliyor?"
"Öz dikkat"teki "öz", giriş dizisini ifade eder. Bazı dikkat mekanizmaları, giriş jetonlarının bir çıkış dizisindeki (ör. çeviri) veya başka bir dizideki jetonlarla ilişkilerini ağırlıklandırır. Ancak kendi kendine dikkat yalnızca giriş dizisindeki jetonlar arasındaki ilişkilerin önemini değerlendirir.
İşleri basitleştirmek için her jetonun bir kelime olduğunu ve bağlamın tamamının tek bir cümle olduğunu varsayın. Aşağıdaki cümleyi ele alalım:
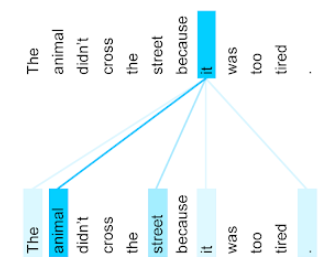
The animal didn't cross the street because it was too tired.
Önceki cümle on bir kelime içeriyor. On bir kelimenin her biri diğer on kelimeye dikkat ediyor ve bu on kelimenin her birinin kendisi için ne kadar önemli olduğunu merak ediyor. Örneğin, cümlede it zamirinin bulunduğunu fark edin. Zamirlere genellikle belirsizlik hâkimdir. It zamiri genellikle yakın zamanda kullanılan bir isim veya isim öbeğini ifade eder. Ancak örnek cümlede it hangi yakın zamanda kullanılan ismi ifade ediyor: hayvanı mı yoksa sokağı mı?
Öz dikkat mekanizması, yakındaki her kelimenin it zamiriyle alaka düzeyini belirler. Şekil 3'te sonuçlar gösterilmektedir. Çizgi ne kadar mavi olursa kelime, it zamiri için o kadar önemlidir. Yani it zamiri için animal (hayvan) kelimesi street (sokak) kelimesinden daha önemlidir.
Bunun aksine, cümledeki son kelimenin aşağıdaki gibi değiştiğini varsayalım:
The animal didn't cross the street because it was too wide.
Bu düzeltilmiş cümlede, öz dikkat mekanizmasının sokak kelimesini it zamirine göre hayvan kelimesinden daha alakalı olarak değerlendirmesi beklenir.
Bazı self-attention mekanizmaları çift yönlüdür. Bu mekanizmalar, ilgilenilen kelimeden önceki ve sonraki jetonların alaka düzeyini hesaplar. Örneğin, Şekil 3'te it kelimesinin her iki tarafındaki kelimelerin incelendiğini görebilirsiniz. Bu nedenle, çift yönlü bir self-attention mekanizması, dikkat edilen kelimenin her iki tarafındaki kelimelerden bağlam bilgisi toplayabilir. Buna karşılık, tek yönlü kendi kendine dikkat mekanizması yalnızca dikkat edilen kelimenin bir tarafındaki kelimelerden bağlam toplayabilir. Çift yönlü kendi kendine dikkat, özellikle tüm dizilerin temsillerini oluşturmak için yararlıdır. Dizileri jeton jeton oluşturan uygulamalar ise tek yönlü kendi kendine dikkat gerektirir. Bu nedenle, kodlayıcılar çift yönlü kendi kendine dikkat mekanizmasını kullanırken kod çözücüler tek yönlü olanı kullanır.
Çok başlı çok katmanlı öz dikkat nedir?
Her öz dikkat katmanı genellikle birden fazla öz dikkat başlığından oluşur. Bir katmanın çıkışı, farklı başlıkların çıkışının matematiksel bir işlemidir (ör. ağırlıklı ortalama veya nokta çarpımı).
Her bir başlığın parametreleri rastgele değerlerle başlatıldığından, farklı başlıklar, dikkat edilen her kelime ile yakındaki kelimeler arasında farklı ilişkiler öğrenebilir. Örneğin, önceki bölümde açıklanan öz dikkat başlığı, it zamirinin hangi isme atıfta bulunduğunu belirlemeye odaklanmıştır. Ancak aynı katmandaki diğer öz dikkat başlıkları, her kelimenin diğer kelimelerle dilbilgisi açısından alaka düzeyini veya başka etkileşimleri öğrenebilir.
Tam bir dönüştürücü model, birden fazla öz dikkat katmanını üst üste yerleştirir. Önceki katmanın çıkışı, sonraki katmanın girişi olur. Bu katmanlama sayesinde model, metinle ilgili giderek daha karmaşık ve soyut bir anlayış geliştirebilir. Önceki katmanlar temel söz dizimine odaklanırken daha derin katmanlar, bu bilgileri tüm girişteki duygu, bağlam ve tematik bağlantılar gibi daha ayrıntılı kavramları anlamak için entegre edebilir.
Dönüştürücüler neden bu kadar büyük?
Dönüştürücüler yüz milyarlarca, hatta trilyonlarca parametre içerir. Bu kursta, genellikle daha az sayıda parametreye sahip modellerin daha fazla sayıda parametreye sahip modellere göre oluşturulması önerilir. Sonuçta, daha az parametreye sahip bir model, tahmin yapmak için daha fazla parametreye sahip bir modele kıyasla daha az kaynak kullanır. Ancak araştırmalar, daha fazla parametreye sahip dönüştürücülerin, daha az parametreye sahip dönüştürücülerden sürekli olarak daha iyi performans gösterdiğini ortaya koymaktadır.
Peki LLM'ler nasıl metin üretir?
Araştırmacıların, eksik bir veya iki kelimeyi tahmin etmek için LLM'leri nasıl eğittiğini görmüş olabilirsiniz ve bu durum sizi etkilememiş olabilir. Sonuçta, bir veya iki kelimeyi tahmin etmek, çeşitli metin, e-posta ve yazma yazılımlarına yerleştirilmiş otomatik tamamlama özelliğinden başka bir şey değildir. LLM'lerin nasıl cümleler, paragraflar veya haikular oluşturduğunu merak ediyor olabilirsiniz.
Aslında LLM'ler, binlerce jetonu otomatik olarak tahmin edebilen (tamamlayabilen) otomatik tamamlama mekanizmalarıdır. Örneğin, maskelenmiş bir cümleyle devam eden bir cümleyi düşünün:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
Bir LLM, maskelenmiş cümle için aşağıdakiler de dahil olmak üzere olasılıklar oluşturabilir:
| Probability | Kelimeler |
|---|---|
| %3,1 | Örneğin, oturabilir, bekleyebilir ve yuvarlanabilir. |
| %2,9 | Örneğin, oturmayı, beklemeyi ve yuvarlanmayı biliyor. |
Yeterince büyük bir LLM, paragraflar ve tüm denemeler için olasılıklar üretebilir. Kullanıcının bir LLM'ye sorduğu soruları, "verilen" cümleden sonra hayali bir maske geliyormuş gibi düşünebilirsiniz. Örneğin:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM, çeşitli olası yanıtlar için olasılıklar oluşturur.
Başka bir örnek olarak, çok sayıda matematiksel "sözel problem" üzerinde eğitilmiş bir LLM, karmaşık matematiksel akıl yürütme yapıyormuş gibi görünebilir. Ancak bu LLM'ler temelde yalnızca bir kelime problemi istemini otomatik olarak tamamlıyor.
LLM'lerin avantajları
LLM'ler, çok çeşitli hedef kitleler için net ve anlaşılması kolay metinler oluşturabilir. LLM'ler, açıkça eğitildikleri görevlerle ilgili tahminlerde bulunabilir. Bazı araştırmacılar, LLM'lerin açıkça eğitilmediği girişler için de tahminlerde bulunabileceğini iddia ederken diğer araştırmacılar bu iddiayı çürütmüştür.
LLM'lerle ilgili sorunlar
Bir LLM'nin eğitimi, aşağıdakiler de dahil olmak üzere birçok sorunu beraberinde getirir:
- Büyük bir eğitim kümesi toplama
- Birkaç ay süren ve muazzam işlem kaynakları ile elektrik tüketen bir süreçtir.
- Paralellik sorunlarını çözme.
Tahminleri çıkarım yapmak için LLM'leri kullanmak aşağıdaki sorunlara neden olur:
- LLM'ler halüsinasyon görür. Bu nedenle, tahminlerinde genellikle hatalar bulunur.
- Büyük dil modelleri, muazzam miktarda bilgi işlem kaynağı ve elektrik tüketir. LLM'leri daha büyük veri kümeleri üzerinde eğitmek genellikle çıkarım için gereken kaynak miktarını azaltır. Ancak daha büyük eğitim kümeleri daha fazla eğitim kaynağı gerektirir.
- Tüm makine öğrenimi modelleri gibi, LLM'ler de her türlü önyargıyı gösterebilir.