Более новая технология, большие языковые модели ( БЛМ ), предсказывают токен или последовательность токенов, иногда даже целые абзацы предсказанных токенов. Следует помнить, что токен может быть словом, подсловом (подмножеством слова) или даже одним символом. БЛМ делают гораздо более точные предсказания, чем N-граммовые языковые модели или рекуррентные нейронные сети, потому что:
- Линейные модели содержат гораздо больше параметров , чем рекуррентные модели.
- Магистерские программы (LLM) позволяют получить гораздо больше контекстной информации.
В этом разделе представлена наиболее успешная и широко используемая архитектура для построения LLM-моделей: Transformer.
Что такое трансформатор?
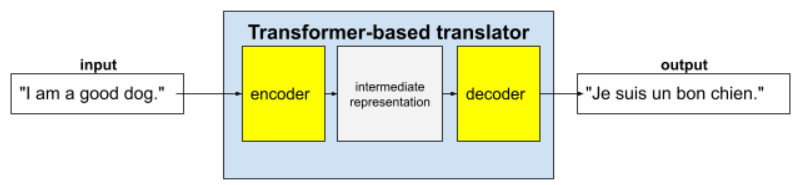
Трансформеры — это передовая архитектура для широкого спектра приложений языковых моделей, таких как перевод:

Полноценные трансформаторы состоят из кодировщика и декодера:
- Кодировщик преобразует входной текст в промежуточное представление. Кодировщик — это огромная нейронная сеть .
- Декодер преобразует это промежуточное представление в полезный текст. Декодер также представляет собой огромную нейронную сеть.
Например, в переводчике:
- Кодировщик обрабатывает входной текст (например, английское предложение) и преобразует его в промежуточное представление.
- Декодер преобразует это промежуточное представление в выходной текст (например, в эквивалентное французское предложение).
Что такое самовнимание?
Для улучшения контекста трансформеры в значительной степени полагаются на концепцию, называемую самовниманием . По сути, от имени каждого входного токена самовнимание задает следующий вопрос:
«Насколько каждый другой входной токен влияет на интерпретацию этого токена?»
В механизме «самовнимания» под «самовниманием» понимается входная последовательность. Некоторые механизмы внимания учитывают взаимосвязь входных элементов с элементами выходной последовательности, например, с переводом, или с элементами другой последовательности. Однако механизм самовнимания учитывает только важность взаимосвязей между элементами входной последовательности.
Для упрощения предположим, что каждый токен — это слово, а полный контекст представляет собой всего лишь одно предложение. Рассмотрим следующее предложение:
The animal didn't cross the street because it was too tired.
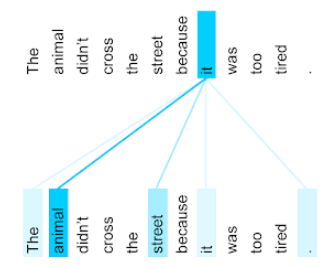
В предыдущем предложении одиннадцать слов. Каждое из этих одиннадцати слов обращает внимание на остальные десять, размышляя о том, насколько каждое из этих десяти слов важно для себя. Например, обратите внимание, что в предложении используется местоимение «it» . Местоимения часто неоднозначны. Местоимение «it» обычно относится к недавно существительному или существительному обороту, но в приведенном примере, к какому именно недавно существительному оно относится — к животному или к улице?
Механизм самовнимания определяет релевантность каждого находящегося рядом слова местоимению «оно» . На рисунке 3 показаны результаты: чем синее линия, тем важнее это слово для местоимения «оно». То есть, слово «животное» важнее для местоимения «оно» , чем «улица ».
И наоборот, предположим, что последнее слово в предложении изменяется следующим образом:
The animal didn't cross the street because it was too wide.
В этом переработанном предложении самовнимание, как предполагается, должно рассматриваться как более релевантное местоимению « это» , чем «животное ».
Некоторые механизмы самовнимания являются двунаправленными , то есть они вычисляют оценки релевантности для токенов, предшествующих и следующих за словом, на которое обращается внимание. Например, на рисунке 3 обратите внимание, что анализируются слова с обеих сторон от этого слова . Таким образом, двунаправленный механизм самовнимания может собирать контекст из слов, расположенных по обе стороны от слова, на которое обращается внимание. В отличие от него, однонаправленный механизм самовнимания может собирать контекст только из слов, расположенных с одной стороны от слова, на которое обращается внимание. Двунаправленное самовнимание особенно полезно для генерации представлений целых последовательностей, в то время как приложения, генерирующие последовательности по токенам, требуют однонаправленного самовнимания. По этой причине кодировщики используют двунаправленное самовнимание, а декодеры — однонаправленное.
Что такое многоголовочная многослойная система самовнимания?
Каждый слой самовнимания обычно состоит из нескольких головок самовнимания . Выход слоя представляет собой математическую операцию (например, взвешенное среднее или скалярное произведение) выходных данных различных головок.
Поскольку параметры каждого модуля инициализируются случайными значениями, разные модули могут изучать разные взаимосвязи между каждым словом, на которое обращается внимание, и соседними словами. Например, модуль самовнимания, описанный в предыдущем разделе, сосредоточился на определении того, к какому существительному относится местоимение. Однако другие модули самовнимания в том же слое могут изучать грамматическую связь каждого слова с каждым другим словом или изучать другие взаимодействия.
Полная модель трансформера строится путем наложения нескольких слоев самовнимания друг на друга. Выходные данные предыдущего слоя становятся входными данными для следующего. Такое наложение позволяет модели постепенно формировать все более сложные и абстрактные представления о тексте. В то время как более ранние слои могут фокусироваться на базовом синтаксисе, более глубокие слои могут интегрировать эту информацию для понимания более тонких концепций, таких как настроение, контекст и тематические связи по всему входному тексту.
Почему трансформеры такие большие?
Трансформеры содержат сотни миллиардов или даже триллионы параметров . В этом курсе обычно рекомендуется строить модели с меньшим количеством параметров, а не с большим. В конце концов, модель с меньшим количеством параметров использует меньше ресурсов для прогнозирования, чем модель с большим количеством параметров. Однако исследования показывают, что трансформеры с большим количеством параметров неизменно превосходят трансформеры с меньшим количеством параметров.
Но как же магистрант генерирует текст?
Вы видели, как исследователи обучают LLM-ы предсказывать одно-два пропущенных слова, и это может вас не впечатлить. В конце концов, предсказание одного-двух слов — это, по сути, функция автозаполнения, встроенная в различные текстовые редакторы, электронные письма и программы для создания контента. Возможно, вы задаетесь вопросом, как LLM-ы могут генерировать предложения, абзацы или хайку об арбитраже.
По сути, LLM-ы — это механизмы автозаполнения, способные автоматически предсказывать (дополнять) тысячи токенов. Например, рассмотрим предложение, за которым следует замаскированное предложение:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
LLM может генерировать вероятности для замаскированного предложения, в том числе:
| Вероятность | Слово(а) |
|---|---|
| 3,1% | Например, он умеет сидеть, оставаться на месте и переворачиваться. |
| 2,9% | Например, он умеет сидеть, оставаться на месте и переворачиваться. |
Достаточно большая модель LLM может генерировать вероятности для абзацев и целых эссе. Вопросы пользователя к модели LLM можно рассматривать как «заданное» предложение, за которым следует воображаемая маска. Например:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
Метод LLM генерирует вероятности для различных возможных ответов.
В качестве другого примера, LLM, обученный на огромном количестве математических «текстовых задач», может создавать впечатление сложных математических рассуждений. Однако по сути такие LLM просто автоматически дополняют подсказку текстовой задачи.
Преимущества магистратуры в области права
LLM-ы способны генерировать понятный и легко воспринимаемый текст для широкого круга целевых аудиторий. LLM-ы могут делать прогнозы для задач, для которых они были специально обучены. Некоторые исследователи утверждают, что LLM-ы также могут делать прогнозы для входных данных, для которых они не были специально обучены, но другие исследователи опровергли это утверждение.
Проблемы с программами магистратуры в области права
Подготовка магистра права (LLM) сопряжена со многими проблемами, в том числе:
- Сбор огромного обучающего набора данных.
- Это потребует нескольких месяцев, огромных вычислительных ресурсов и электроэнергии.
- Решение задач параллельного программирования.
Использование линейных моделей для получения прогнозов приводит к следующим проблемам:
- У людей с ограниченными возможностями развития бывают галлюцинации , а это значит, что их предсказания часто содержат ошибки.
- Модели LLM потребляют огромное количество вычислительных ресурсов и электроэнергии. Обучение моделей LLM на больших наборах данных обычно уменьшает количество ресурсов, необходимых для вывода результатов, хотя большие обучающие наборы требуют больше ресурсов для обучения.
- Как и все модели машинного обучения, модели с линейным обучением могут демонстрировать всевозможные искажения.