เทคโนโลยีใหม่กว่าอย่าง โมเดลภาษาขนาดใหญ่ (LLM) คาดการณ์โทเค็นหรือลำดับโทเค็น ซึ่งบางครั้งอาจเป็นโทเค็นที่คาดการณ์ไว้หลายย่อหน้า โปรดทราบว่าโทเค็นอาจเป็นคำ คำย่อย (ชุดย่อยของคำ) หรือแม้แต่อักขระเดียว LLM คาดการณ์ได้ดีกว่าโมเดลภาษา N-gram หรือเครือข่ายประสาทแบบเกิดซ้ำมากเนื่องจาก
- LLM มีพารามิเตอร์มากกว่าโมเดลที่เกิดซ้ำมาก
- LLM รวบรวมบริบทได้มากกว่า
ส่วนนี้จะแนะนำสถาปัตยกรรมที่ประสบความสำเร็จและใช้กันอย่างแพร่หลายมากที่สุด ในการสร้าง LLM นั่นคือ Transformer
หม้อแปลงคืออะไร
Transformer เป็นสถาปัตยกรรมที่ล้ำสมัยสำหรับแอปพลิเคชันโมเดลภาษาที่หลากหลาย เช่น การแปล

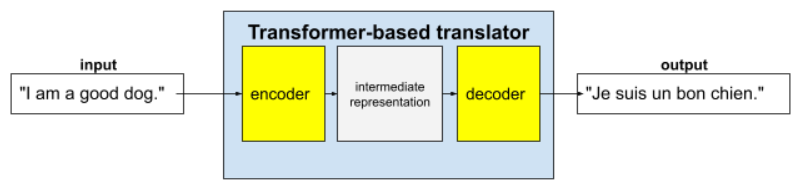
Transformer แบบเต็มประกอบด้วย Encoder และ Decoder ดังนี้
- Encoder จะแปลง ข้อความอินพุตเป็นการแสดงข้อมูลระดับกลาง Encoder คือโครงข่ายประสาทเทียมขนาดใหญ่
- ดีโคดเดอร์จะแปลง การแทนค่ากลางนั้นเป็นข้อความที่มีประโยชน์ ดีโคดเดอร์ยังเป็น โครงข่ายประสาทขนาดใหญ่ด้วย
เช่น ในโปรแกรมแปล
- ตัวเข้ารหัสจะประมวลผลข้อความอินพุต (เช่น ประโยคภาษาอังกฤษ) เป็น การแสดงข้อมูลระดับกลาง
- ตัวถอดรหัสจะแปลงการแทนค่ากลางนั้นเป็นข้อความเอาต์พุต (เช่น ประโยคภาษาฝรั่งเศสที่เทียบเท่า)
Self-Attention คืออะไร
Transformer อาศัยแนวคิดที่เรียกว่าการใส่ใจตนเองเป็นอย่างมากเพื่อเพิ่มบริบท กล่าวคือ ในนามของโทเค็นอินพุตแต่ละรายการ Self-Attention จะถามคำถามต่อไปนี้
"โทเค็นอินพุตแต่ละรายการส่งผลต่อการตีความโทเค็นนี้มากน้อยเพียงใด"
คำว่า "self" ใน "self-attention" หมายถึงลำดับอินพุต กลไกการให้ความสนใจบางอย่างจะพิจารณาความสัมพันธ์ของโทเค็นอินพุตกับโทเค็นในลำดับเอาต์พุต เช่น การแปล หรือกับโทเค็นในลำดับอื่นๆ แต่การทำSelf-Attention เพียงอย่างเดียวจะ พิจารณาความสำคัญของความสัมพันธ์ระหว่างโทเค็นในลำดับอินพุตเท่านั้น
เพื่อความสะดวก ให้ถือว่าโทเค็นแต่ละรายการเป็นคำ และบริบทที่สมบูรณ์เป็นเพียงประโยคเดียว ลองพิจารณาประโยคต่อไปนี้
The animal didn't cross the street because it was too tired.
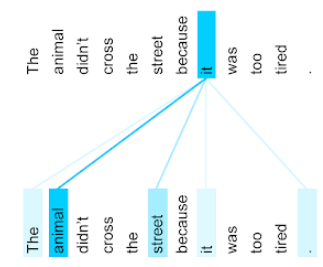
ประโยคก่อนหน้ามี 11 คำ คำทั้ง 11 คำจะ สนใจคำอื่นๆ อีก 10 คำ และสงสัยว่าคำทั้ง 10 คำนั้น มีความสำคัญต่อตัวมันเองมากน้อยเพียงใด เช่น สังเกตว่าประโยคมีคำสรรพนาม มัน คำสรรพนามมักมีความกำกวม โดยปกติแล้ว คำสรรพนาม it จะหมายถึง คำนามหรือกลุ่มคำนามที่เพิ่งกล่าวถึง แต่ในประโยคตัวอย่าง คำนามที่เพิ่งกล่าวถึงคำใดที่ it หมายถึง สัตว์หรือถนน
กลไกการใส่ใจตนเองจะกำหนดความเกี่ยวข้องของคำที่อยู่ใกล้เคียงแต่ละคำกับ คำสรรพนาม it รูปที่ 3 แสดงผลลัพธ์ ยิ่งเส้นเป็นสีน้ำเงินมากเท่าใด คำนั้นก็จะยิ่งมีความสำคัญต่อคำสรรพนาม it มากขึ้นเท่านั้น นั่นคือ animal มีความสำคัญมากกว่า street สำหรับคำสรรพนาม it
ในทางกลับกัน สมมติว่าคำสุดท้ายในประโยคมีการเปลี่ยนแปลงดังนี้
The animal didn't cross the street because it was too wide.
ในประโยคที่แก้ไขนี้ หวังว่าการทำความเข้าใจตนเองจะให้คะแนนถนนว่ามีความเกี่ยวข้องกับคำสรรพนาม it มากกว่าสัตว์
กลไกการทำงานแบบ Self-Attention บางอย่างเป็นแบบสองทิศทาง ซึ่งหมายความว่ากลไกดังกล่าวจะ คำนวณคะแนนความเกี่ยวข้องสำหรับโทเค็นที่อยู่ก่อนหน้าและอยู่หลังคำที่ กำลังพิจารณา ตัวอย่างเช่น ในรูปที่ 3 คุณจะเห็นว่าระบบจะตรวจสอบคำทั้ง 2 ด้านของ คำนั้น ดังนั้น กลไกการทำงานแบบ Self-Attention แบบ 2 ทิศทางจึงรวบรวมบริบทจากคำที่อยู่ทั้ง 2 ด้านของคำที่กำลังพิจารณาได้ ในทางตรงกันข้าม กลไกการทำงานแบบ Self-Attention ทางเดียวจะรวบรวมบริบทจากคำที่อยู่ ด้านใดด้านหนึ่งของคำที่กำลังพิจารณาเท่านั้น Self-Attention แบบสองทิศทางมีประโยชน์อย่างยิ่งในการสร้างการแสดงลำดับทั้งหมด ขณะที่แอปพลิเคชันที่สร้างลำดับทีละโทเค็นต้องใช้ Self-Attention แบบทิศทางเดียว ด้วยเหตุนี้ ตัวเข้ารหัสจึงใช้การทำ Self-Attention แบบสองทิศทาง ขณะที่ตัวถอดรหัสใช้แบบทิศทางเดียว
Multi-Head Multi-Layer Self-Attention คืออะไร
โดยปกติแล้วเลเยอร์ Self-Attention แต่ละเลเยอร์จะประกอบด้วยหัว Self-Attention หลายหัว เอาต์พุตของเลเยอร์คือการดำเนินการทางคณิตศาสตร์ (เช่น ค่าเฉลี่ยถ่วงน้ำหนักหรือผลคูณจุด) ของเอาต์พุตของหัวต่างๆ
เนื่องจากพารามิเตอร์ของแต่ละหัวได้รับการเริ่มต้นเป็นค่าแบบสุ่ม หัวที่แตกต่างกันจึงสามารถเรียนรู้ความสัมพันธ์ที่แตกต่างกันระหว่างแต่ละคำที่สนใจกับคำที่อยู่ใกล้เคียง ตัวอย่างเช่น หัวแบบ Self-Attention ที่อธิบายไว้ในส่วนก่อนหน้า มุ่งเน้นที่การพิจารณาว่าคำสรรพนาม it อ้างถึงคำนามใด อย่างไรก็ตาม หัวการใส่ใจตนเองอื่นๆ ภายในเลเยอร์เดียวกันอาจเรียนรู้ความเกี่ยวข้องทางไวยากรณ์ของแต่ละคำกับคำอื่นๆ หรือเรียนรู้การโต้ตอบอื่นๆ
โมเดล Transformer ที่สมบูรณ์จะซ้อนเลเยอร์การใส่ใจตนเองหลายเลเยอร์ไว้ด้านบนของกันและกัน เอาต์พุตจากเลเยอร์ก่อนหน้าจะกลายเป็นอินพุตสำหรับเลเยอร์ถัดไป การซ้อนกันนี้ช่วยให้โมเดลสร้างความเข้าใจข้อความที่ซับซ้อนและเป็นนามธรรมมากขึ้นเรื่อยๆ ในขณะที่เลเยอร์ก่อนหน้าอาจมุ่งเน้นไปที่ไวยากรณ์พื้นฐาน เลเยอร์ที่ลึกลงไปจะผสานรวมข้อมูลดังกล่าวเพื่อทำความเข้าใจแนวคิดที่ซับซ้อนยิ่งขึ้น เช่น ความรู้สึก บริบท และลิงก์ตามธีมในอินพุตทั้งหมด
ทำไมโมเดล Transformer ถึงมีขนาดใหญ่มาก
Transformer มีพารามิเตอร์หลายแสนล้านหรือหลายล้านล้าน โดยทั่วไปหลักสูตรนี้แนะนำให้สร้างโมเดลที่มีพารามิเตอร์จำนวนน้อยกว่าโมเดลที่มีพารามิเตอร์จำนวนมาก เนื่องจากโมเดลที่มีพารามิเตอร์จำนวนน้อยกว่าจะใช้ทรัพยากรน้อยกว่า ในการคาดการณ์เมื่อเทียบกับโมเดลที่มีพารามิเตอร์จำนวนมากกว่า อย่างไรก็ตาม งานวิจัยแสดงให้เห็นว่า Transformer ที่มีพารามิเตอร์มากกว่า มีประสิทธิภาพเหนือกว่า Transformer ที่มีพารามิเตอร์น้อยกว่าอย่างสม่ำเสมอ
แต่ LLM สร้างข้อความได้อย่างไร
คุณได้เห็นแล้วว่านักวิจัยฝึก LLM ให้คาดเดาคำที่ขาดหายไป 1-2 คำอย่างไร และคุณอาจไม่ประทับใจ เพราะการคาดคะเนคำ 1-2 คำก็คือฟีเจอร์ การเติมข้อความอัตโนมัติที่ฝังอยู่ในซอฟต์แวร์ต่างๆ สำหรับข้อความ อีเมล และการเขียน คุณอาจสงสัยว่า LLM สร้างประโยค ย่อหน้า หรือ ไฮกุเกี่ยวกับการเก็งกำไรได้อย่างไร
ในความเป็นจริงแล้ว LLM เป็นกลไกการเติมข้อความอัตโนมัติที่สามารถคาดการณ์ (เติม) โทเค็นหลายพันรายการได้โดยอัตโนมัติ เช่น ลองพิจารณาประโยค ตามด้วยประโยคที่มาสก์
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
LLM สามารถสร้างความน่าจะเป็นสำหรับประโยคที่มาสก์ได้ ซึ่งรวมถึง
| Probability | คำ |
|---|---|
| 3.1% | เช่น นั่ง หมอบ และ กลิ้ง |
| 2.9% | เช่น เขารู้วิธีนั่ง อยู่ และ กลิ้ง |
LLM ที่มีขนาดใหญ่เพียงพอจะสร้างความน่าจะเป็นสำหรับย่อหน้าและเรียงความทั้ง หมดได้ คุณอาจมองว่าคำถามของผู้ใช้ที่ส่งไปยัง LLM เป็นประโยค "ที่กำหนด" ตามด้วยมาสก์สมมติ เช่น
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM จะสร้างความน่าจะเป็นสำหรับคำตอบที่เป็นไปได้ต่างๆ
อีกตัวอย่างหนึ่งคือ LLM ที่ได้รับการฝึกฝนจาก "โจทย์" คณิตศาสตร์จำนวนมหาศาลอาจดูเหมือนว่าใช้การให้เหตุผลทางคณิตศาสตร์ที่ซับซ้อน แต่ LLM เหล่านั้นก็แค่เติมข้อความพรอมต์โจทย์ปัญหาให้สมบูรณ์โดยอัตโนมัติ
ประโยชน์ของ LLM
LLM สามารถสร้างข้อความที่ชัดเจนและเข้าใจง่ายสำหรับกลุ่มเป้าหมายที่หลากหลาย LLM สามารถคาดการณ์งานที่ได้รับการฝึกมาโดยเฉพาะได้ นักวิจัยบางคนอ้างว่า LLM ยังสามารถคาดการณ์อินพุตที่ไม่ได้รับการฝึกอย่างชัดแจ้งได้ด้วย แต่นักวิจัยคนอื่นๆ ได้โต้แย้งคำกล่าวอ้างนี้
ปัญหาเกี่ยวกับ LLM
การฝึก LLM มีปัญหาหลายอย่าง เช่น
- รวบรวมชุดฝึกขนาดใหญ่
- การใช้ทรัพยากรในการประมวลผลและไฟฟ้าจำนวนมากเป็นเวลาหลายเดือน
- การแก้ปัญหาความท้าทายด้านการประมวลผลแบบคู่ขนาน
การใช้ LLM เพื่ออนุมานการคาดการณ์ทำให้เกิดปัญหาต่อไปนี้
- LLM หลอน ซึ่งหมายความว่าการคาดการณ์มักมีข้อผิดพลาด
- LLM ใช้ทรัพยากรการประมวลผลและไฟฟ้าเป็นจำนวนมหาศาล โดยปกติแล้วการฝึก LLM ในชุดข้อมูลขนาดใหญ่จะช่วยลด ปริมาณทรัพยากรที่จำเป็นสำหรับการอนุมาน แม้ว่าชุดการฝึกที่ใหญ่ขึ้น จะทำให้ต้องใช้ทรัพยากรในการฝึกมากขึ้นก็ตาม
- LLM มีอคติได้ทุกรูปแบบเช่นเดียวกับโมเดล ML ทั้งหมด