Nowszą technologią są duże modele językowe (LLM), które przewidują token lub sekwencję tokenów, czasem nawet wiele akapitów przewidywanych tokenów. Pamiętaj, że token może być słowem, podwyrazem (podzbiorem słowa) lub nawet pojedynczym znakiem. Duże modele językowe generują znacznie lepsze prognozy niż modele językowe N-gram lub rekurencyjne sieci neuronowe, ponieważ:
- Modele LLM zawierają znacznie więcej parametrów niż modele rekurencyjne.
- Modele LLM zbierają znacznie więcej kontekstu.
W tej sekcji przedstawiamy najskuteczniejszą i najczęściej używaną architekturę do tworzenia dużych modeli językowych: transformator.
Co to jest Transformer?
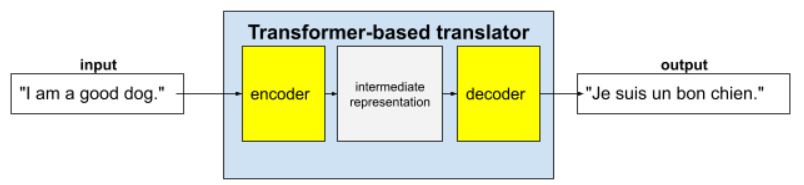
Transformery to najnowocześniejsza architektura do wielu zastosowań modeli językowych, takich jak tłumaczenie:

Pełne modele Transformer składają się z enkodera i dekodera:
- Koder przekształca tekst wejściowy w reprezentację pośrednią. Koder to ogromna sieć neuronowa.
- Dekoder przekształca tę reprezentację pośrednią w przydatny tekst. Dekoder to również ogromna sieć neuronowa.
Na przykład w tłumaczu:
- Koder przetwarza tekst wejściowy (np. zdanie w języku angielskim) na pewną reprezentację pośrednią.
- Dekoder przekształca tę reprezentację pośrednią w tekst wyjściowy (np. równoważne zdanie w języku francuskim).
Co to jest mechanizm uwagi?
Aby wzbogacić kontekst, modele transformujące w dużym stopniu opierają się na koncepcji samouwagi. W przypadku każdego tokena wejściowego mechanizm uwagi do samego siebie zadaje to pytanie:
„W jakim stopniu każdy inny token wejściowy wpływa na interpretację tego tokena?”
„Self” w „self-attention” odnosi się do sekwencji wejściowej. Niektóre mechanizmy uwagi ważą relacje tokenów wejściowych z tokenami w sekwencji wyjściowej, np. w tłumaczeniu, lub z tokenami w innej sekwencji. Mechanizm self-attention uwzględnia tylko znaczenie relacji między tokenami w sekwencji wejściowej.
Dla uproszczenia załóżmy, że każdy token to słowo, a pełny kontekst to tylko jedno zdanie. Rozważmy to zdanie:
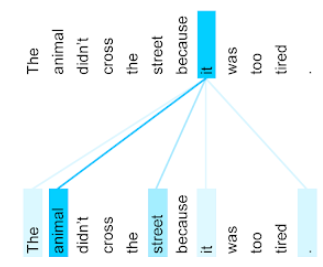
The animal didn't cross the street because it was too tired.
Poprzednie zdanie zawiera 11 słów. Każde z 11 słów zwraca uwagę na pozostałe 10, zastanawiając się, jak bardzo każde z nich jest dla niego ważne. Zwróć uwagę, że zdanie zawiera zaimek it. Zaimki są często niejednoznaczne. Zaimek it zwykle odnosi się do ostatniego rzeczownika lub wyrażenia rzeczownikowego, ale w przykładzie zdania, do którego rzeczownika odnosi się it – do zwierzęcia czy do ulicy?
Mechanizm samouwagi określa trafność każdego pobliskiego słowa względem zaimka it. Rysunek 3 przedstawia wyniki – im bardziej niebieska linia, tym większe znaczenie ma dane słowo dla zaimka it. Oznacza to, że słowo animal jest ważniejsze niż słowo street dla zaimka it.
Załóżmy, że ostatnie słowo w zdaniu zmienia się w ten sposób:
The animal didn't cross the street because it was too wide.
W tym zmienionym zdaniu mechanizm samouważności powinien ocenić słowo ulica jako bardziej istotne niż słowo zwierzę w odniesieniu do zaimka ono.
Niektóre mechanizmy uwagi do samego siebie są dwukierunkowe, co oznacza, że obliczają wyniki trafności dla tokenów poprzedzających i następujących po słowie, na którym skupia się uwaga. Na przykład na rysunku 3 widać, że analizowane są słowa po obu stronach słowa it. Dwukierunkowy mechanizm samouważności może więc zbierać kontekst ze słów po obu stronach słowa, na którym skupia się uwaga. Z kolei jednokierunkowy mechanizm uwagi może zbierać kontekst tylko ze słów znajdujących się po jednej stronie słowa, na którym skupia się uwaga. Dwukierunkowa uwaga własna jest szczególnie przydatna do generowania reprezentacji całych sekwencji, natomiast aplikacje, które generują sekwencje token po tokenie, wymagają jednokierunkowej uwagi własnej. Z tego powodu kodery używają dwukierunkowego mechanizmu self-attention, a dekodery – jednokierunkowego.
Co to jest wielogłowicowa wielowarstwowa uwaga własna?
Każda warstwa uwagi do samej siebie składa się zwykle z kilku głowic uwagi do samej siebie. Dane wyjściowe warstwy to operacja matematyczna (np. średnia ważona lub iloczyn skalarny) danych wyjściowych różnych głów.
Ponieważ parametry każdej głowicy są inicjowane losowymi wartościami, różne głowice mogą się uczyć różnych relacji między każdym słowem, na którym skupia się uwaga, a słowami znajdującymi się w pobliżu. Na przykład głowica mechanizmu samouważania opisana w poprzedniej sekcji koncentrowała się na ustaleniu, do którego rzeczownika odnosi się zaimek it. Jednak inne głowice samouwagi w tej samej warstwie mogą się nauczyć gramatycznego znaczenia każdego słowa względem każdego innego słowa lub innych interakcji.
Kompletny model transformujący składa się z wielu warstw samouwagi ułożonych jedna na drugiej. Dane wyjściowe z poprzedniej warstwy stają się danymi wejściowymi dla następnej. Dzięki temu model może stopniowo budować coraz bardziej złożone i abstrakcyjne rozumienie tekstu. Podczas gdy wcześniejsze warstwy mogą koncentrować się na podstawowej składni, głębsze warstwy mogą integrować te informacje, aby zrozumieć bardziej zniuansowane koncepcje, takie jak nastrój, kontekst i powiązania tematyczne w całym tekście wejściowym.
Dlaczego modele Transformer są tak duże?
Modele Transformer zawierają setki miliardów, a nawet biliony parametrów. W tym kursie zalecamy tworzenie modeli z mniejszą liczbą parametrów zamiast tych z większą liczbą parametrów. Model z mniejszą liczbą parametrów zużywa mniej zasobów na potrzeby prognozowania niż model z większą liczbą parametrów. Badania pokazują jednak, że modele Transformer z większą liczbą parametrów konsekwentnie osiągają lepsze wyniki niż modele z mniejszą liczbą parametrów.
Ale jak LLM generuje tekst?
Wiesz już, jak badacze trenują duże modele językowe, aby przewidywały brakujące słowo lub dwa, i może nie robi to na Tobie wrażenia. W końcu przewidywanie jednego lub dwóch słów to w zasadzie funkcja autouzupełniania wbudowana w różne programy do pisania tekstów, poczty e-mail i tworzenia treści. Być może zastanawiasz się, jak LLM-y mogą generować zdania, akapity lub haiku na temat arbitrażu.
Modele LLM to w zasadzie mechanizmy autouzupełniania, które mogą automatycznie przewidywać (uzupełniać) tysiące tokenów. Weźmy na przykład zdanie, po którym następuje zdanie z zamaskowanymi słowami:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
LLM może generować prawdopodobieństwa dla zamaskowanego zdania, w tym:
| Prawdopodobieństwo | Słowo |
|---|---|
| 3,1% | Na przykład może siadać, zostawać i przewracać się na bok. |
| 2,9% | Na przykład potrafi siadać, zostawać i przewracać się na bok. |
Odpowiednio duży LLM może generować prawdopodobieństwa dla akapitów i całych esejów. Pytania użytkownika do LLM można traktować jako „podane” zdanie, po którym następuje wyimaginowana maska. Na przykład:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM generuje prawdopodobieństwa dla różnych możliwych odpowiedzi.
Inny przykład: duży model językowy wytrenowany na ogromnej liczbie matematycznych „zadań tekstowych” może sprawiać wrażenie, że przeprowadza zaawansowane rozumowanie matematyczne. Te duże modele językowe w zasadzie tylko automatycznie uzupełniają prompta z zadaniem słownym.
Zalety dużych modeli językowych
Modele LLM mogą generować jasne i zrozumiałe teksty dla różnych grup odbiorców. Modele LLM mogą generować prognozy dotyczące zadań, do których zostały specjalnie wytrenowane. Niektórzy badacze twierdzą, że duże modele językowe mogą też dokonywać prognoz na podstawie danych wejściowych, na których nie były bezpośrednio trenowane, ale inni badacze obalili to twierdzenie.
Problemy z dużymi modelami językowymi
Trenowanie LLM wiąże się z wieloma problemami, w tym:
- zbieranie ogromnego zbioru treningowego,
- Wymaga to wielu miesięcy i ogromnych zasobów obliczeniowych oraz energii elektrycznej.
- Rozwiązywanie problemów z równoległością.
Używanie dużych modeli językowych do wyciągania wniosków na podstawie prognoz powoduje te problemy:
- LLM halucynują, co oznacza, że ich prognozy często zawierają błędy.
- Modele LLM zużywają ogromne ilości zasobów obliczeniowych i energii elektrycznej. Trenowanie LLM na większych zbiorach danych zwykle zmniejsza ilość zasobów wymaganych do wnioskowania, chociaż większe zbiory treningowe wymagają więcej zasobów.
- Podobnie jak wszystkie modele ML, LLM mogą wykazywać różnego rodzaju uprzedzenia.