In precedenza hai riscontrato classificazione binaria modelli che possono scegliere tra una delle due possibili scelte, ad esempio se:
- Una determinata email è spam o non spam.
- Un determinato tumore è maligno o benigno.
In questa sezione analizzeremo classificazione multiclasse di grandi dimensioni, che possono scegliere tra più possibilità. Ad esempio:
- Questo cane è un beagle, un bassotto o un segugio?
- Questo fiore è un iris siberiano, un iris olandese, un iris bandiera blu? o l'iride barbata nana?
- Quell'aereo è un Boeing 747, Airbus 320, Boeing 777 o Embraer 190?
- È l'immagine di una mela, un orso, un dolce, un cane o un uovo?
Alcuni problemi reali multiclasse comportano la scelta tra milioni di classi separate. Considera ad esempio una classificazione multiclasse in grado di identificare l'immagine di qualsiasi cosa.
Questa sezione descrive le due varianti principali della classificazione multiclasse:
- uno contro tutti
- one-vs.-one, di solito noto come softmax
Uno contro tutti
One-vs.-all consente di utilizzare la classificazione binaria per una serie di previsioni sì o no su più etichette possibili.
Dato un problema di classificazione con N possibili soluzioni, una contro tutto è composta da N classificatori binari separati, uno binario classificatore per ogni possibile risultato. Durante l'addestramento, il modello viene eseguito attraverso una sequenza di classificatori binari, addestrando ognuno di loro a rispondere domanda di classificazione.
Ad esempio, se vediamo l'immagine di un frutto, vengono si possono addestrati diversi riconoscimenti, ognuno dei quali risponde a una domanda diversa domanda:
- Questa immagine è una mela?
- Questa immagine è di colore arancione?
- Questa immagine è una banana?
- Questa immagine è un'uva?
L'immagine seguente mostra come funziona nella pratica.
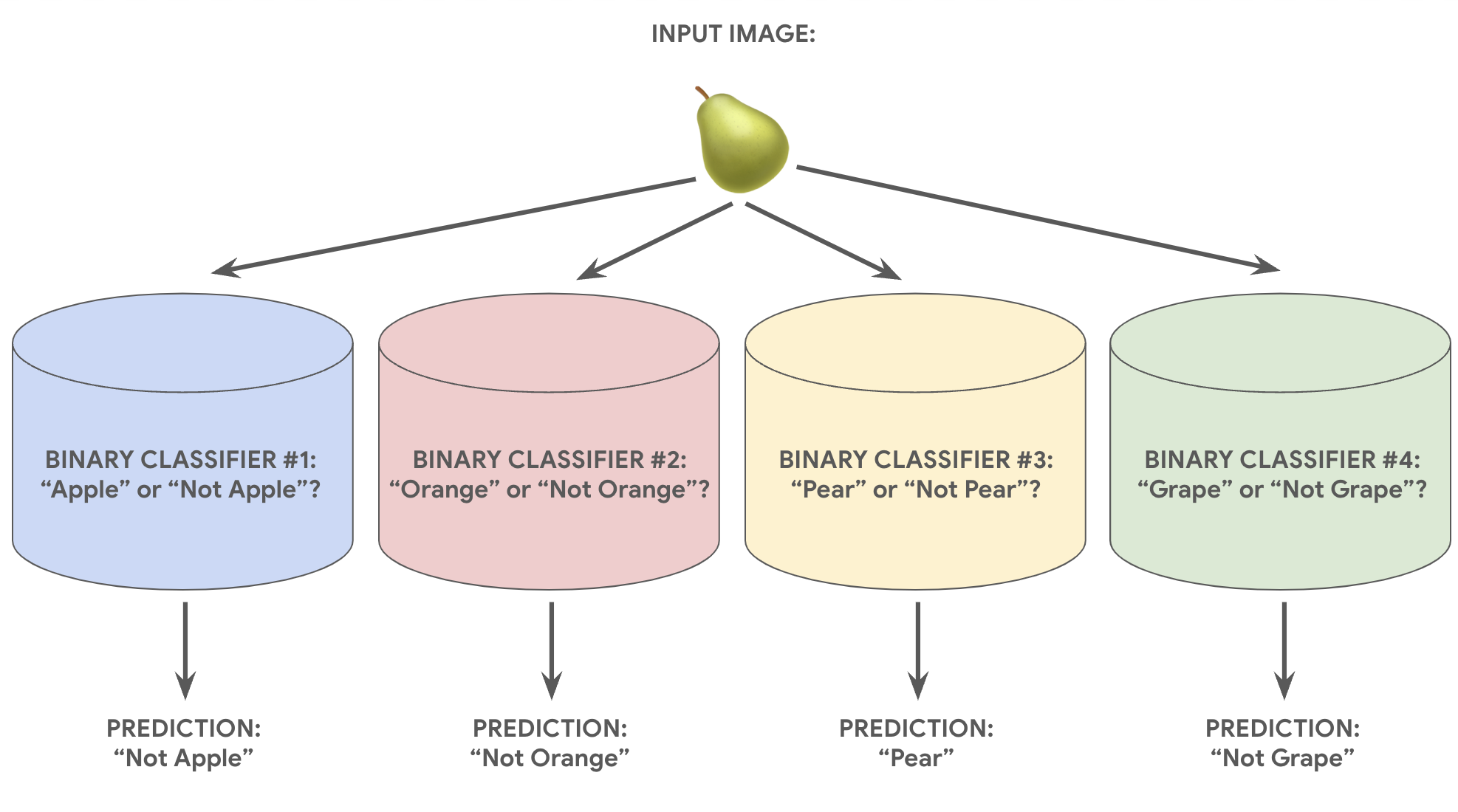
Questo approccio è abbastanza ragionevole quando il numero totale di classi è piccola, ma diventa sempre più inefficiente con il numero di classi aumenta.
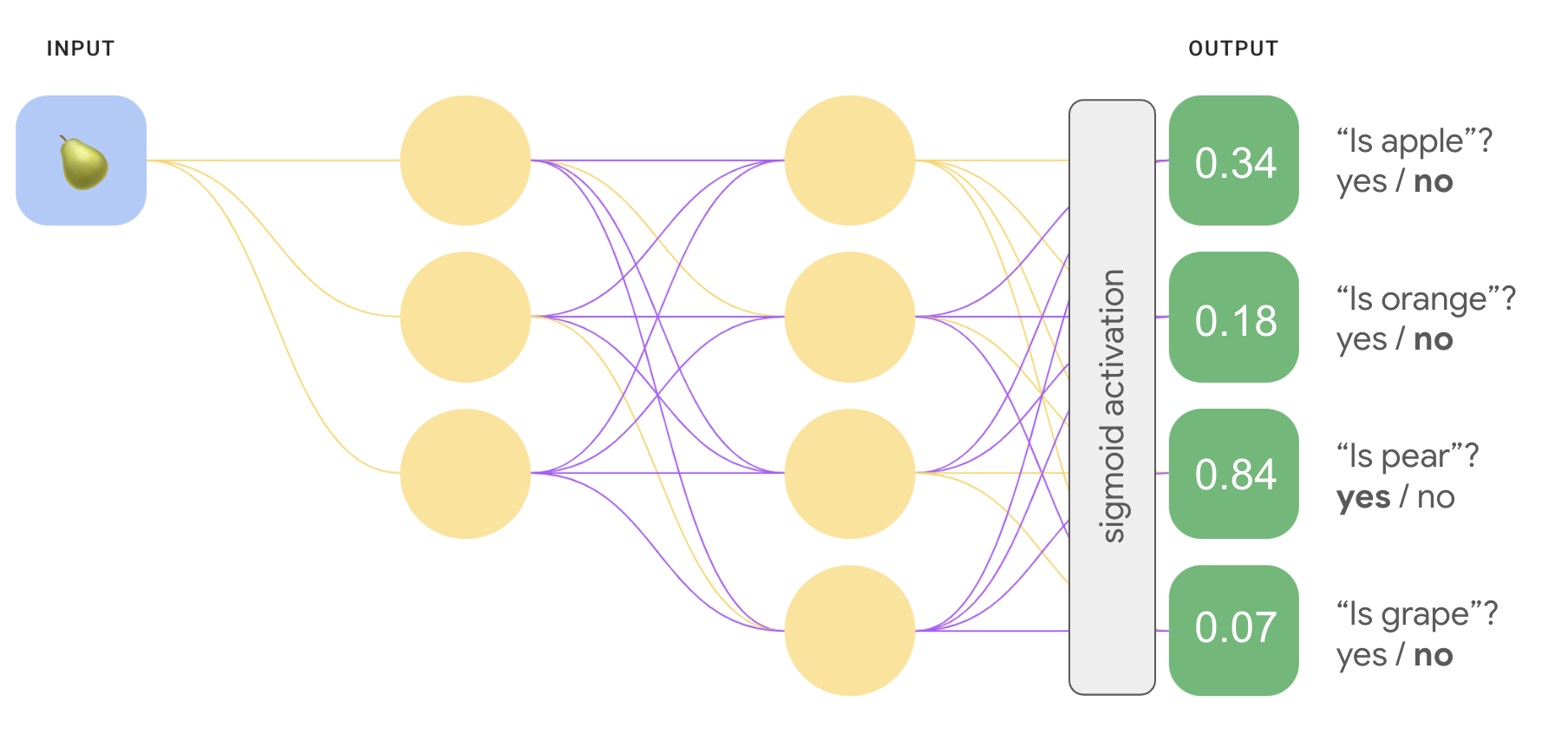
Possiamo creare un modello one-vs-all molto più efficiente con una rete neurale profonda in cui ogni nodo di output rappresenta un . L'immagine seguente illustra questo approccio.
Uno contro uno (softmax)
Avrai notato che i valori di probabilità nello strato di output della Figura 8 non è la somma di 1,0 (o 100%). (in effetti, la somma è 1,43). In un confronto uno contro tutti di previsione, la probabilità di ogni insieme binario di risultati viene indipendentemente da tutti gli altri insiemi. In altre parole, determiniamo la probabilità di "mela" rispetto a "non mela" senza considerare la probabilità che altri opzioni di frutta: "arancione", "pera" o "uva".
E se volessimo prevedere le probabilità di ogni frutto l'una rispetto all'altra? In questo caso, invece di prevedere "mela" rispetto a "non apple", vogliamo prevedere "mela" rispetto a "arancione" rispetto a "pera" rispetto all'"uva". Questo tipo di classificazione multiclasse è chiamata classificazione uno contro uno.
Possiamo implementare una classificazione one-vs.-one utilizzando lo stesso tipo di architettura di rete utilizzata per la classificazione one-vs.-all, con una modifica chiave. Dobbiamo applicare una trasformazione diversa al livello di output.
Per uno contro tutti, abbiamo applicato la funzione di attivazione sigmoidea a ciascun output nodo in modo indipendente, ottenendo un valore di output compreso tra 0 e 1 per ogni nodo, ma non garantisce che questi valori sommassero esattamente 1.
Per uno o più, possiamo invece applicare una funzione chiamata softmax, che assegna probabilità decimali a ciascuna classe in un problema multiclasse in modo che la somma delle probabilità è 1,0. Questo vincolo aggiuntivo aiuta l'addestramento a convergere più rapidamente.
L'immagine seguente reimplementa la nostra classificazione multiclasse uno o tutti come un'attività di tipo one-vs. Tieni presente che per eseguire la funzione softmax, che precede quello di output, detto strato softmax, deve avere lo stesso numero di nodi del livello di output.
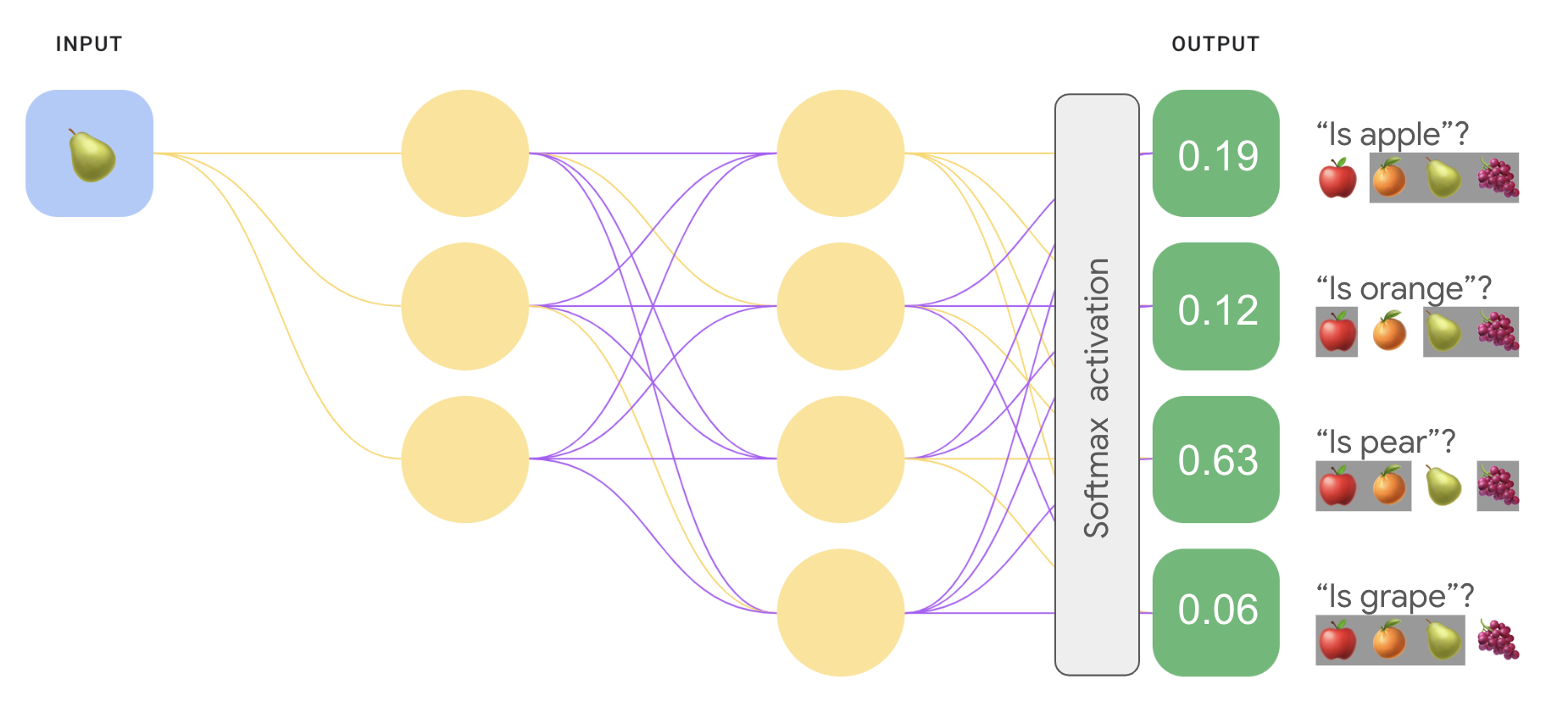
Opzioni softmax
Considera le seguenti varianti di softmax:
Full softmax è la versione softmax di cui abbiamo parlato. cioè la funzione softmax calcola una probabilità per ogni possibile classe.
Il campionamento candidato indica che la funzione softmax calcola una probabilità per tutte le etichette positive, ma solo per un campione casuale di etichette negative. Ad esempio, se vogliamo determinare che l'immagine di input sia un beagle o un segugio, fornire probabilità per ogni esempio non doggy.
Il softmax completo è abbastanza economico quando il numero di classi è ridotto ma diventa proibitivo se il numero di classi aumenta. Il campionamento dei candidati può migliorare l'efficienza in caso di problemi il numero di classi.
Una etichetta rispetto a più etichette
Softmax presuppone che ogni esempio appartenga esattamente a una classe. Alcuni esempi, tuttavia, possono essere membri contemporaneamente di più classi. Per questi esempi:
- Non puoi utilizzare la funzione softmax.
- Devi fare affidamento su più regressioni logistica.
Ad esempio, il modello one-vs.-one nella Figura 9 precedente presuppone che ogni input immagine raffigura un solo tipo di frutta: una mela, un'arancia, una pera un'uva. Tuttavia, se un'immagine di input può contenere più tipi di frutta: mele e arance, dovrete usare vari sistemi logistici regressioni e test di regressione.