Раніше ви стикалися з моделями бінарної класифікації, які могли вибирати один із двох можливих варіантів, наприклад визначати:
- є певний електронний лист спамом чи ні;
- злоякісна певна пухлина чи доброякісна.
У цьому розділі розглядаються моделі багатокласової класифікації, які можуть вибирати з багатьох варіантів. Наприклад, вони можуть дати відповіді на запитання, наведені нижче.
- Порода цього пса – бігль, басет-гаунд чи бладгаунд?
- Ця квітка – "півник сибірський", "півник голландський", "півник різнобарвний" чи "півник німецький"?
- Цей літак – Boeing 747, Airbus 320, Boeing 777 чи Embraer 190?
- Це зображення яблука, ведмедя, цукерки, собаки чи яйця?
Деякі багатокласові задачі, для яких використовують моделі на практиці, передбачають вибір із мільйонів окремих класів. Наприклад, розгляньмо модель багатокласової класифікації, яка може ідентифікувати зображення майже будь-чого.
У цьому розділі докладно описано два основних методи багатокласової класифікації:
- "один проти всіх" (one-vs.-all);
- "один проти одного" (one-vs.-one) (зазвичай називається функцією м’якого максимуму, або softmax).
"Один проти всіх"
Метод один проти всіх дає змогу використовувати бінарну класифікацію, щоб робити ряд прогнозів "так" або "ні" для кількох можливих міток.
Якщо задача класифікації має N можливих варіантів, у рішенні "один проти всіх" буде N окремих бінарних класифікаторів – по одному для кожного можливого результату. Для реалізації цього рішення тренується послідовність бінарних класифікаторів: кожен із них навчається відповідати на окреме запитання класифікації.
Наприклад, маючи зображення шматочка фрукта, можна навчити чотири різні моделі для розпізнавання, кожна з яких відповідатиме на інше запитання, що вимагає відповіді "так" чи "ні". Приклади запитань наведено нижче.
- Це зображення яблука?
- Це зображення апельсина?
- Це зображення банана?
- Це зображення винограду?
На зображенні нижче показано, як це працює на практиці.
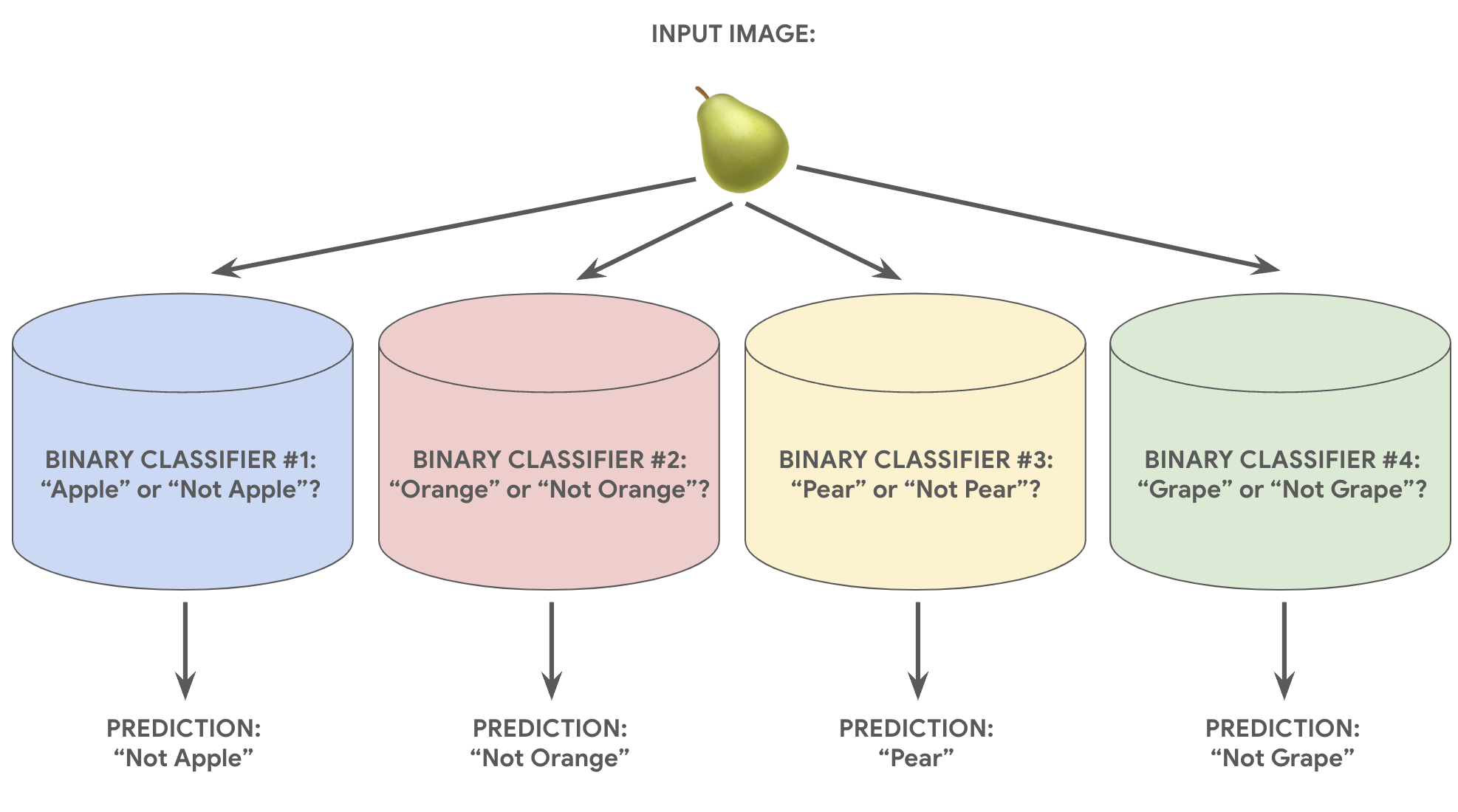
Цей підхід розумний, якщо загальна кількість класів невелика, але що більше їх стає, то менш ефективним він є.
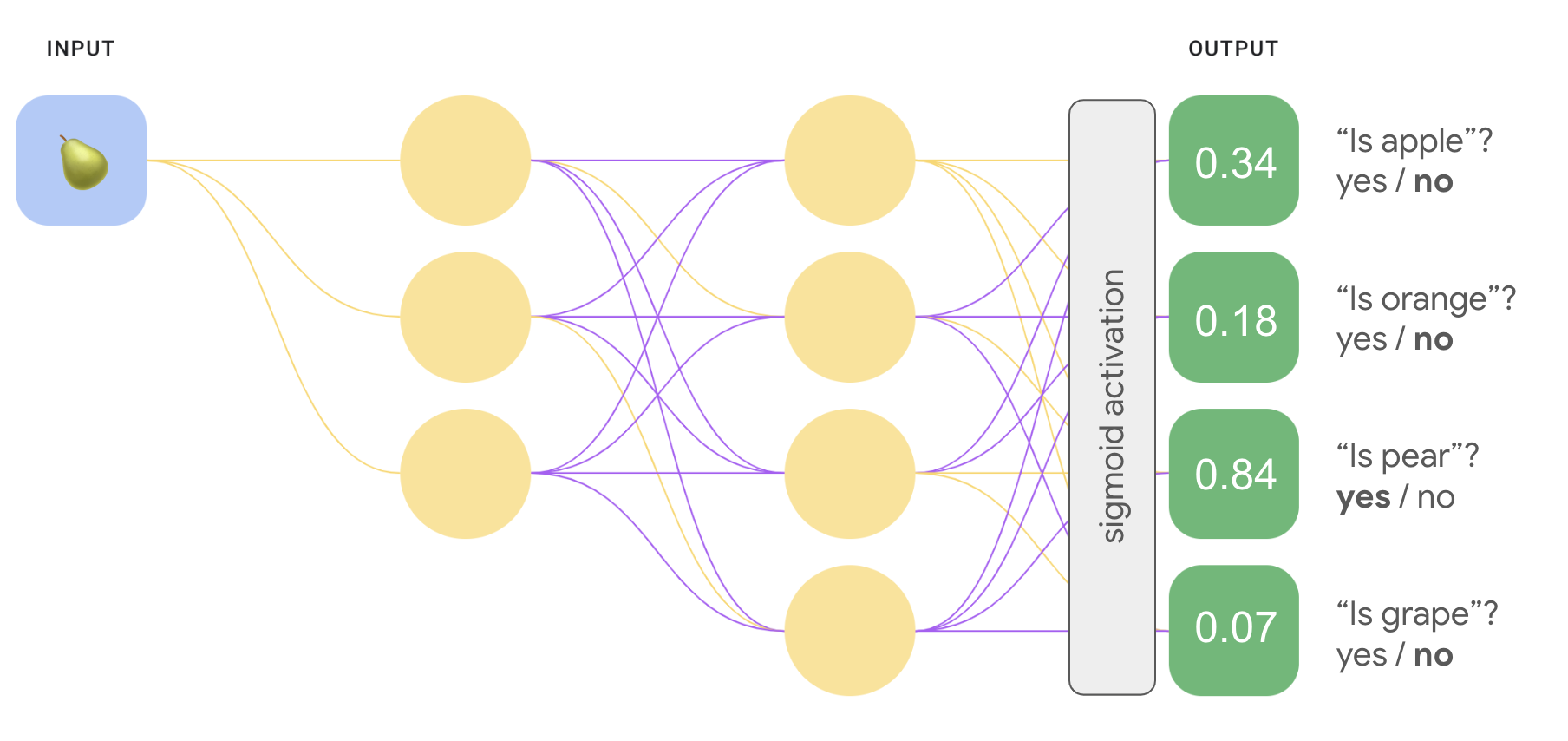
Можна створити значно ефективнішу модель "один проти всіх" із глибинною нейронною мережею, у якій кожен вихідний вузол представляє інший клас. Цей підхід показано на зображенні нижче.
"Один проти одного" (softmax)
Можливо, ви помітили, що значення ймовірності вихідного шару на рисунку 8 у сумі не дорівнюють 1,0 (або 100%). (Насправді їх сума дорівнює 1,43.) Метод "один проти всіх" визначає імовірність для кожного з двійкових наборів результатів незалежно від інших. Тобто ми визначаємо ймовірність того, що зображення є яблуком ("так" або "ні"), не враховуючи вірогідність інших варіантів фруктів, таких як апельсин, груша чи виноград.
Але що як потрібно передбачити ймовірність кожного варіанта фрукта в порівнянні з іншими? Тоді замість того, щоб прогнозувати, чи це яблуко ("так" чи "ні"), слід визначати вірогідність цього проти ймовірності апельсина, груші й винограду. Цей тип багатокласової класифікації називається один проти одного.
Класифікацію "один проти одного" можна реалізувати, використовуючи той самий тип архітектури нейронної мережі, як і для методу "один проти всіх", з однією ключовою зміною. Потрібно застосовувати іншу трансформацію до вихідного шару.
Для рішення "один проти всіх" ми застосували сигмоїдну функцію активації окремо до кожного вихідного вузла. Як результат, вихідні значення кожного вузла були між 0 і 1, але їх сума не завжди дорівнювала 1.
Натомість для рішення "один проти одного" можна застосувати функцію softmax, яка призначає десяткові значення ймовірності кожному класу задачі з кількома класами, щоб усі вони в сумі становили 1,0. Це додаткове обмеження допомагає швидше досягти збіжності при навчанні, ніж в інших випадках.
На зображенні нижче наша задача багатокласової класифікації "один проти всіх" реалізована повторно, але вже як задача "один проти одного". Зауважте, що для виконання функції softmax прихований шар, який безпосередньо передує вихідному шару (так званий шар softmax), повинен мати таку ж кількість вузлів, як і вихідний шар.
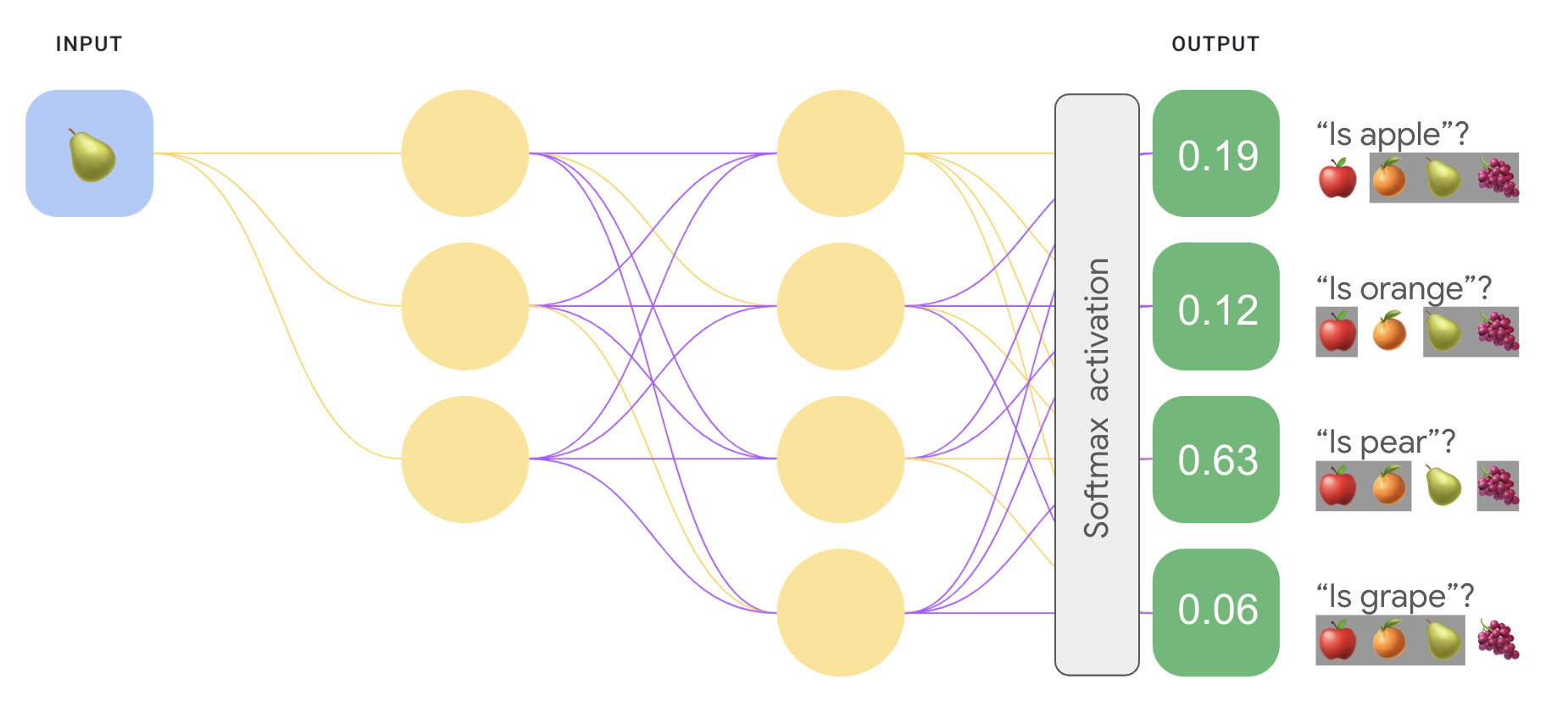
Варіанти функції softmax
Розгляньмо варіанти функції softmax, наведені нижче.
Повна функція softmax – це та функція softmax, яку ми обговорювали, тобто яка обчислює імовірність для кожного можливого класу.
Вибірка кандидатів означає, що функція softmax обчислює імовірність для всіх позитивних міток і лише для випадкової вибірки негативних міток. Наприклад, якщо потрібно визначити, це бігль на вхідному зображенні чи бладгаунд, значення ймовірності для кожного прикладу, який не є собакою, не знадобляться.
Повна функція softmax є досить дешевим варіантом, якщо класів небагато, але стає непомірно дорогою, коли кількість класів зростає. Вибірка кандидатів може підвищити ефективність для задач із великою кількістю класів.
Одна мітка проти багатьох міток
Функція softmax передбачає, що кожен приклад належить точно до одного класу. Однак деякі приклади можуть належати одночасно до кількох класів. У такому разі:
- не можна використовувати функцію softmax;
- потрібно використовувати декілька логістичних регресій.
Наприклад, модель "один проти одного" з рисунка 9, наведеного вище, передбачає, що кожне вхідне зображення міститиме рівно один тип фруктів: яблуко, апельсин, грушу або виноград. Однак якщо на вхідному зображенні не один тип фруктів (наприклад, миска яблук і апельсинів), доведеться використовувати кілька логістичних регресій.