In der vorherigen Übung haben Sie gesehen, dass es nicht ausreicht, unserem Netzwerk nur versteckte Schichten hinzuzufügen, um Nichtlinearitäten darzustellen. Lineare Vorgänge, die auf lineare Vorgänge angewendet werden, sind weiterhin linear.
Wie können Sie ein neuronales Netzwerk so konfigurieren, dass es nichtlineare Beziehungen zwischen Werten lernt? Wir brauchen eine Möglichkeit, nicht lineare mathematische Operationen in ein Modell einzufügen.
Das mag Ihnen bekannt vorkommen, weil wir bereits früher im Kurs nichtlineare mathematische Operationen auf die Ausgabe eines linearen Modells angewendet haben. Im Modul Logistische Regression haben wir ein lineares Regressionsmodell so angepasst, dass ein kontinuierlicher Wert von 0 bis 1 ausgegeben wird (dies entspricht einer Wahrscheinlichkeit). Dazu haben wir die Ausgabe des Modells durch eine Sigmoidfunktion geleitet.
Wir können dasselbe Prinzip auf unser neuronales Netzwerk anwenden. Kehren wir zu unserem Modell aus Übung 2 zurück, aber diesmal wenden wir vor der Ausgabe des Werts jedes Knotens zuerst die Sigmoid-Funktion an:
Sie können die Berechnungen der einzelnen Knoten durchlaufen, indem Sie auf die Schaltfläche >| rechts neben der Wiedergabeschaltfläche klicken. Sehen Sie sich die mathematischen Operationen an, die zur Berechnung der einzelnen Knotenwerte im Bereich Berechnungen unterhalb des Diagramms ausgeführt wurden. Die Ausgabe jedes Knotens ist jetzt eine Sigmoid-Transformation der linearen Kombination der Knoten in der vorherigen Schicht. Die Ausgabewerte liegen alle zwischen 0 und 1.
Hier dient die Sigmoide als Aktivierungsfunktion für das neuronale Netzwerk, eine nicht lineare Transformation des Ausgabewerts eines Neurons, bevor der Wert als Eingabe an die Berechnungen der nächsten Schicht des neuronalen Netzwerks übergeben wird.
Da wir jetzt eine Aktivierungsfunktion hinzugefügt haben, hat das Hinzufügen von Ebenen mehr Auswirkungen. Durch das Stapeln von Nichtlinearitäten können wir sehr komplizierte Beziehungen zwischen den Eingaben und den vorhergesagten Ergebnissen modellieren. Kurz gesagt lernt jede Schicht eine komplexere Funktion auf höherer Ebene anhand der Roheingaben. Wenn Sie mehr über die Funktionsweise erfahren möchten, lesen Sie den ausgezeichneten Blogpost von Chris Olah.
Gängige Aktivierungsfunktionen
Die drei mathematischen Funktionen, die häufig als Aktivierungsfunktionen verwendet werden, sind Sigmoid, tanh und ReLU.
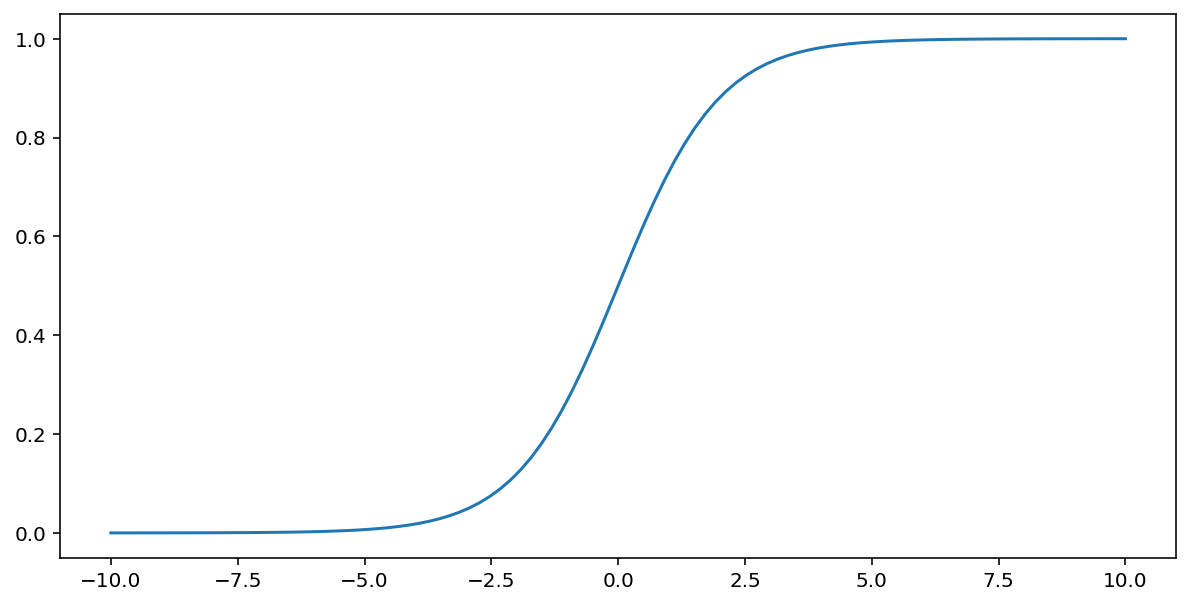
Die Sigmoidfunktion (siehe oben) führt die folgende Transformation auf den Eingabewert x aus und liefert einen Ausgabewert zwischen 0 und 1:
\[F(x)=\frac{1} {1+e^{-x}}\]
Hier ist ein Plot dieser Funktion:
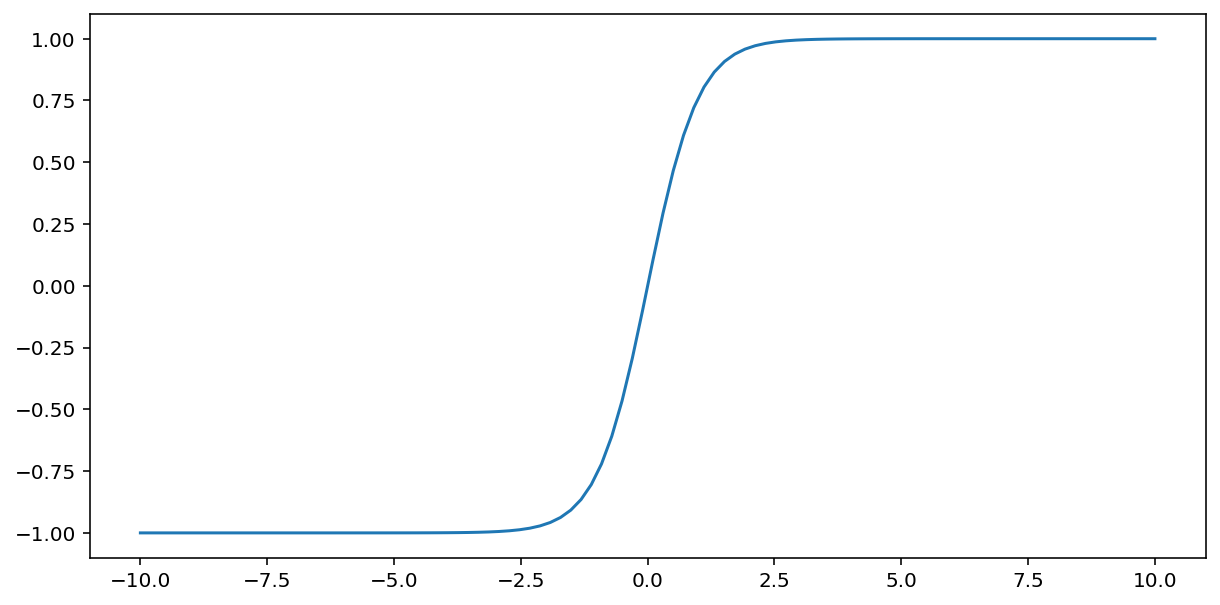
Die tanh-Funktion (kurz für „hyperbolische Tangente“) transformiert den Eingabewert x in einen Ausgabewert zwischen −1 und 1:
\[F(x)=tanh(x)\]
Hier ist ein Plot dieser Funktion:
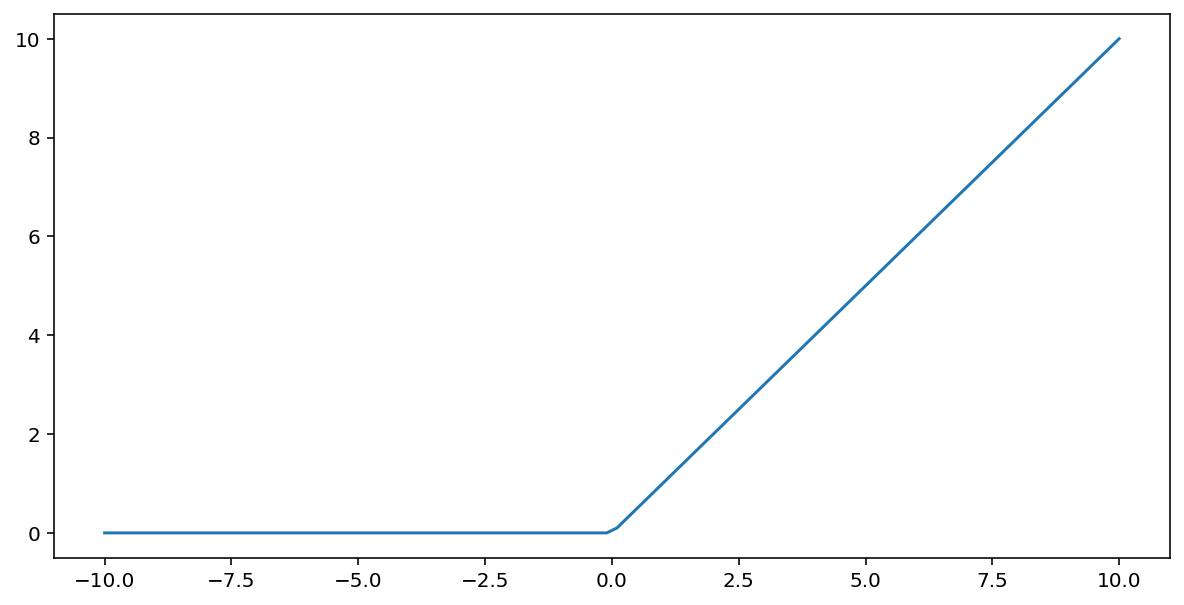
Die Aktivierungsfunktion der rektifizierten linearen Einheit (kurz ReLU) transformiert die Ausgabe mit dem folgenden Algorithmus:
- Wenn der Eingabewert x kleiner als 0 ist, geben Sie 0 zurück.
- Wenn der Eingabewert x größer oder gleich 0 ist, wird der Eingabewert zurückgegeben.
ReLU kann mit der Funktion max() mathematisch dargestellt werden:
Hier ist ein Diagramm dieser Funktion:
ReLU funktioniert als Aktivierungsfunktion oft etwas besser als eine glatte Funktion wie Sigmoid oder Tanh, da sie beim Training von neuronalen Netzwerken weniger anfällig für das Problem des verschwindenden Gradienten ist. Außerdem ist ReLU wesentlich einfacher zu berechnen als diese Funktionen.
Weitere Aktivierungsfunktionen
In der Praxis kann jede mathematische Funktion als Aktivierungsfunktion dienen. Angenommen, \(\sigma\) repräsentiert unsere Aktivierungsfunktion. Der Wert eines Knotens im Netzwerk wird durch die folgende Formel angegeben:
Keras bietet standardmäßig Unterstützung für viele Aktivierungsfunktionen. Wir empfehlen jedoch, mit ReLU zu beginnen.
Zusammenfassung
Das folgende Video fasst alles zusammen, was Sie bisher über den Aufbau neuronaler Netzwerke gelernt haben:
Unser Modell enthält jetzt alle Standardkomponenten, die normalerweise mit einem neuronalen Netzwerk assoziiert werden:
- Eine Reihe von Knoten, die analog zu Neuronen in Schichten organisiert sind.
- Eine Reihe von Gewichten, die die Verbindungen zwischen den einzelnen Schichten des neuronalen Netzes und der darunter liegenden Schicht darstellen. Die darunterliegende Schicht kann eine andere neuronale Netzwerkschicht oder eine andere Art von Schicht sein.
- Eine Reihe von Voreingenommenheiten, eine für jeden Knoten.
- Eine Aktivierungsfunktion, die die Ausgabe jedes Knotens in einer Schicht umwandelt. Unterschiedliche Schichten können unterschiedliche Aktivierungsfunktionen haben.
Einschränkend: Neuronale Netze sind nicht unbedingt immer besser als Feature-Kreuzungen, bieten aber eine flexible Alternative, die in vielen Fällen gut funktioniert.