คุณได้เห็นในแบบฝึกหัดก่อนหน้าว่าการเพิ่มเลเยอร์ที่ซ่อนอยู่ในเครือข่ายนั้นไม่เพียงพอที่จะแสดงลักษณะที่ไม่ใช่เชิงเส้น การดำเนินการเชิงเส้นที่ดำเนินการกับการดำเนินการเชิงเส้นจะยังคงเป็นเชิงเส้น
คุณกําหนดค่าเครือข่ายประสาทเพื่อเรียนรู้ความสัมพันธ์ที่ไม่ใช่เชิงเส้นระหว่างค่าต่างๆ ได้อย่างไร เราต้องการวิธีแทรกการดำเนินการทางคณิตศาสตร์แบบไม่เชิงเส้นลงในโมเดล
หากดูคุ้นเคย แสดงว่าเราได้ใช้การดำเนินการทางคณิตศาสตร์แบบไม่เชิงเส้นกับเอาต์พุตของโมเดลเชิงเส้นแล้วก่อนหน้านี้ในหลักสูตร ในข้อบังคับการถดถอยเชิงลอจิสติก เราได้ปรับโมเดลการถดถอยเชิงเส้นให้แสดงผลค่าต่อเนื่องจาก 0 ถึง 1 (แสดงถึงความน่าจะเป็น) โดยส่งเอาต์พุตของโมเดลผ่านฟังก์ชัน sigmoid
เรานําหลักการเดียวกันนี้ไปใช้กับเครือข่ายประสาทได้ มาดูโมเดลจากแบบฝึกหัดที่ 2 กันอีกครั้ง แต่ครั้งนี้ก่อนแสดงผลค่าของโหนดแต่ละโหนด เราจะใช้ฟังก์ชัน Sigmoid ก่อน
ลองทำขั้นตอนการคำนวณของแต่ละโหนดโดยคลิกปุ่ม >| (ทางด้านขวาของปุ่มเล่น) ตรวจสอบการดำเนินการทางคณิตศาสตร์ที่ดำเนินการเพื่อคํานวณค่าโหนดแต่ละค่าในแผงการคํานวณใต้กราฟ โปรดทราบว่าตอนนี้เอาต์พุตของโหนดแต่ละโหนดคือการเปลี่ยนรูปแบบ Sigmoid ของชุดค่าผสมเชิงเส้นของโหนดในเลเยอร์ก่อนหน้า และค่าเอาต์พุตทั้งหมดจะอยู่ระหว่าง 0 ถึง 1
ในที่นี้ Sigmoid ทำหน้าที่เป็นฟังก์ชันการเปิดใช้งานสําหรับเครือข่ายประสาท ซึ่งเป็นการเปลี่ยนรูปแบบแบบไม่เชิงเส้นของค่าเอาต์พุตของเซลล์ประสาทก่อนที่จะส่งค่าเป็นอินพุตไปยังการคํานวณของชั้นถัดไปของเครือข่ายประสาท
ตอนนี้เราได้เพิ่มฟังก์ชันเปิดใช้งานแล้ว การเพิ่มเลเยอร์มีผลอย่างมาก การซ้อนโมเดลที่ไม่ใช่เชิงเส้นบนโมเดลที่ไม่ใช่เชิงเส้นช่วยให้เราสร้างความสัมพันธ์ที่ซับซ้อนมากระหว่างอินพุตกับเอาต์พุตที่คาดการณ์ได้ กล่าวโดยย่อคือ แต่ละเลเยอร์จะเรียนรู้ฟังก์ชันที่ซับซ้อนมากขึ้นในระดับที่สูงขึ้นจากอินพุตดิบได้อย่างมีประสิทธิภาพ หากคุณต้องการทำความเข้าใจเพิ่มเติมเกี่ยวกับวิธีการทำงาน โปรดดูที่บล็อกโพสต์ที่ยอดเยี่ยมของ Chris Olah
ฟังก์ชันการเปิดใช้งานทั่วไป
ฟังก์ชันทางคณิตศาสตร์ 3 รายการที่ใช้เป็นฟังก์ชันการเปิดใช้งานโดยทั่วไป ได้แก่ sigmoid, tanh และ ReLU
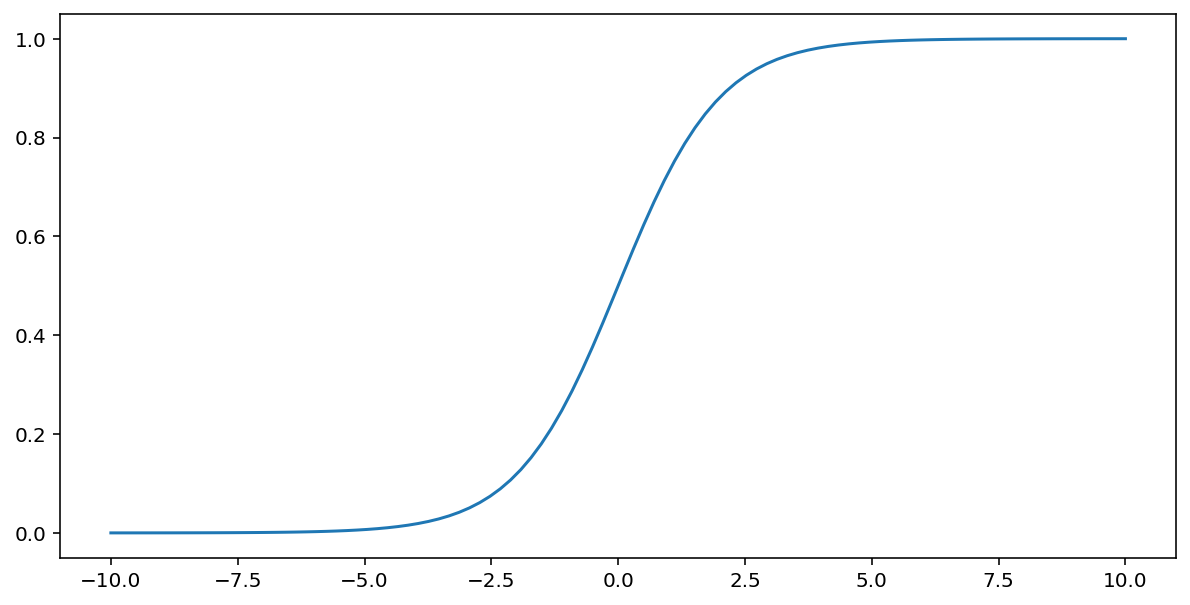
ฟังก์ชัน Sigmoid (ตามที่ได้อธิบายไว้ข้างต้น) จะเปลี่ยนรูปแบบข้อมูลต่อไปนี้ในอินพุต $x$ ซึ่งจะให้ค่าเอาต์พุตระหว่าง 0 ถึง 1
\[F(x)=\frac{1} {1+e^{-x}}\]
นี่คือผังฟังก์ชันนี้
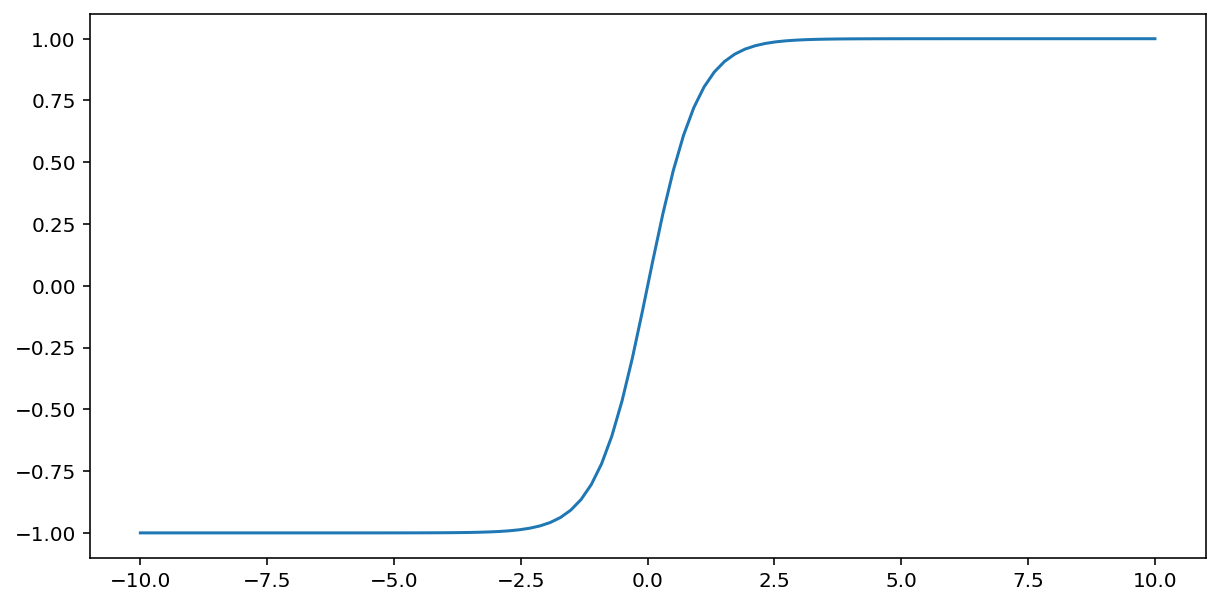
ฟังก์ชัน tanh (ย่อมาจาก "Hyperbolic Tangent") จะเปลี่ยนค่าอินพุต $x$ ให้แสดงผลค่าเอาต์พุตระหว่าง –1 ถึง 1 ดังนี้
\[F(x)=tanh(x)\]
นี่คือผังฟังก์ชันนี้
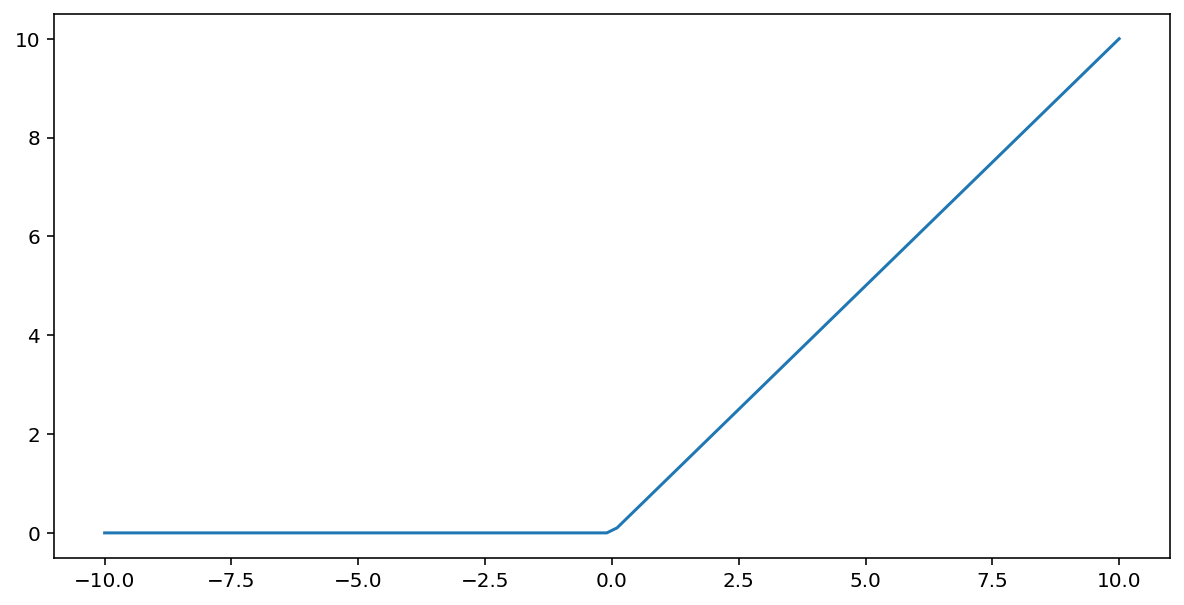
ฟังก์ชันเปิดใช้งานหน่วยเชิงเส้นที่ปรับแล้ว (หรือเรียกสั้นๆ ว่า ReLU) จะแปลงเอาต์พุตโดยใช้อัลกอริทึมต่อไปนี้
- หากค่าอินพุต $x$ น้อยกว่า 0 ให้แสดงผล 0
- หากค่าอินพุต $x$ มากกว่าหรือเท่ากับ 0 ให้แสดงผลค่าอินพุต
ReLU สามารถแสดงเป็นคณิตศาสตร์ได้โดยใช้ฟังก์ชัน max() ดังนี้
นี่คือผังฟังก์ชันนี้
ReLU มักจะทํางานได้ดีกว่าเล็กน้อยเมื่อเป็นฟังก์ชันเปิดใช้งานมากกว่าฟังก์ชันที่ลื่นไหล เช่น Sigmoid หรือ Tanh เพราะมีความเสี่ยงน้อยกว่าต่อปัญหาการไล่ระดับสีที่หายไประหว่างการฝึกโครงข่ายระบบประสาท นอกจากนี้ ReLU ยังคำนวณได้ง่ายกว่าฟังก์ชันเหล่านี้อย่างมาก
ฟังก์ชันการเปิดใช้งานอื่นๆ
ในทางปฏิบัติ ฟังก์ชันคณิตศาสตร์ใดก็ได้ที่ทำหน้าที่เป็นฟังก์ชันการเปิดใช้งาน สมมติว่า \(\sigma\) แสดงถึงฟังก์ชันการเปิดใช้งาน ค่าของโหนดในเครือข่ายจะแสดงตามสูตรต่อไปนี้
Keras รองรับฟังก์ชันการเปิดใช้งานหลายรายการโดยทันที อย่างไรก็ตาม เรายังคงแนะนำให้เริ่มต้นด้วย ReLU
สรุป
วิดีโอต่อไปนี้สรุปทุกสิ่งที่คุณได้เรียนรู้เกี่ยวกับการสร้างโครงข่ายประสาทจนถึงตอนนี้
ตอนนี้โมเดลของเรามีองค์ประกอบมาตรฐานทั้งหมดที่ผู้คนมักจะหมายถึงเมื่อพูดถึงเครือข่ายประสาท ดังนี้
- ชุดของโหนดคล้ายกับเซลล์ประสาทที่จัดเรียงเป็นเลเยอร์
- ชุดน้ำหนักที่แสดงการเชื่อมต่อระหว่างแต่ละชั้นของเครือข่ายประสาทกับชั้นที่อยู่ด้านล่าง เลเยอร์ที่อยู่ด้านล่างอาจเป็นเลเยอร์เครือข่ายประสาทอีกเลเยอร์หนึ่งหรือเลเยอร์ประเภทอื่น
- ชุดของค่ากําหนด 1 ค่าสําหรับแต่ละโหนด
- ฟังก์ชันการเปิดใช้งานที่เปลี่ยนรูปแบบเอาต์พุตของโหนดแต่ละโหนดในเลเยอร์ เลเยอร์ต่างๆ อาจมีฟังก์ชันการเปิดใช้งานที่แตกต่างกัน
ข้อควรระวัง: โครงข่ายประสาทไม่ได้ดีกว่าการครอสฟีเจอร์เสมอไป แต่โครงข่ายประสาทเป็นทางเลือกที่ยืดหยุ่นและทํางานได้ดีในหลายกรณี