Dans l'exercice précédent, vous avez vu que l'ajout de couches cachées à notre réseau n'était pas suffisant pour représenter les non-linéarités. Les opérations linéaires effectuées sur des opérations linéaires restent linéaires.
Comment configurer un réseau de neurones pour qu'il apprenne les relations non linéaires entre les valeurs ? Nous avons besoin d'un moyen d'insérer des opérations mathématiques non linéaires dans un modèle.
Si cela vous semble un peu familier, c'est parce que nous avons déjà appliqué des opérations mathématiques non linéaires à la sortie d'un modèle linéaire plus tôt dans le cours. Dans le module Régression logistique, nous avons adapté un modèle de régression linéaire pour générer une valeur continue comprise entre 0 et 1 (représentant une probabilité) en transmettant la sortie du modèle via une fonction sigmoïde.
Nous pouvons appliquer le même principe à notre réseau de neurones. Reprenons le modèle de l'exercice 2 précédent, mais cette fois, avant d'afficher la valeur de chaque nœud, nous allons d'abord appliquer la fonction sigmoïde:
Essayez de suivre les calculs de chaque nœud en cliquant sur le bouton >| (à droite du bouton de lecture). Examinez les opérations mathématiques effectuées pour calculer chaque valeur de nœud dans le panneau Calculations sous le graphique. Notez que la sortie de chaque nœud est désormais une transformation sigmoïde de la combinaison linéaire des nœuds de la couche précédente, et que les valeurs de sortie sont toutes compressées entre 0 et 1.
Ici, la fonction sigmoïde sert de fonction d'activation pour le réseau de neurones, une transformation non linéaire de la valeur de sortie d'un neurone avant qu'elle ne soit transmise en entrée aux calculs de la couche suivante du réseau de neurones.
Maintenant que nous avons ajouté une fonction d'activation, l'ajout de couches a plus d'impact. L'empilement de non-linéarités nous permet de modéliser des relations très complexes entre les entrées et les sorties prévues. En résumé, chaque couche apprend une fonction plus complexe et de niveau supérieur par rapport aux entrées brutes. Pour en savoir plus sur le fonctionnement de ce processus, consultez l'excellent article de blog de Chris Olah.
Fonctions d'activation courantes
Trois fonctions mathématiques couramment utilisées comme fonctions d'activation sont la fonction sigmoïde, tanh et ReLU.
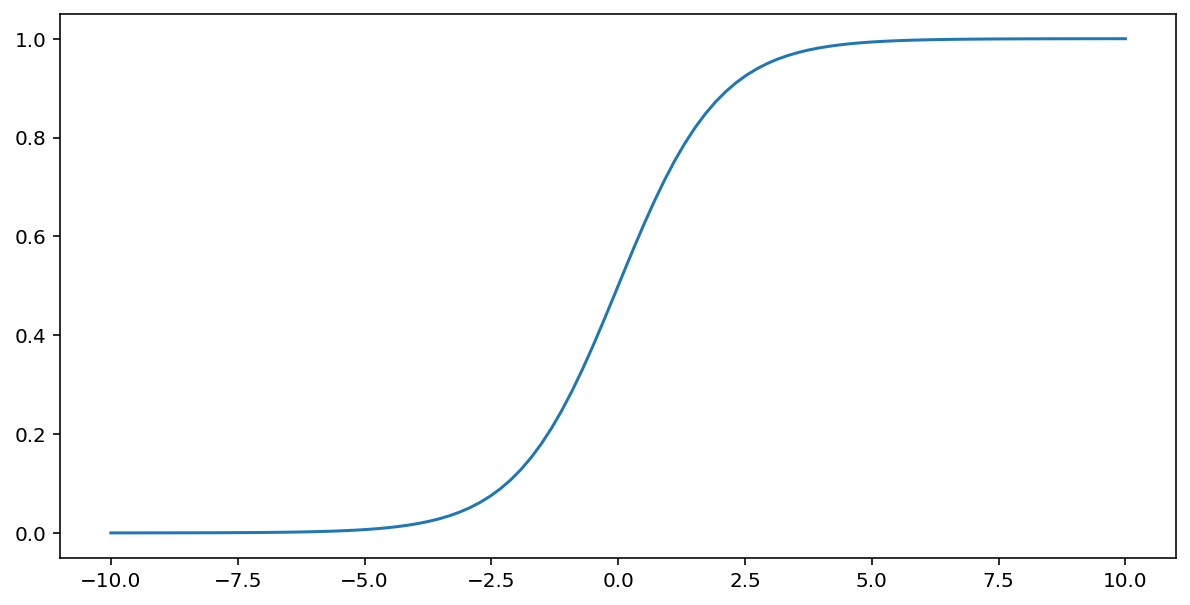
La fonction sigmoïde (décrite ci-dessus) effectue la transformation suivante sur l'entrée $x$, produisant une valeur de sortie comprise entre 0 et 1:
\[F(x)=\frac{1} {1+e^{-x}}\]
Voici un graphique de cette fonction:
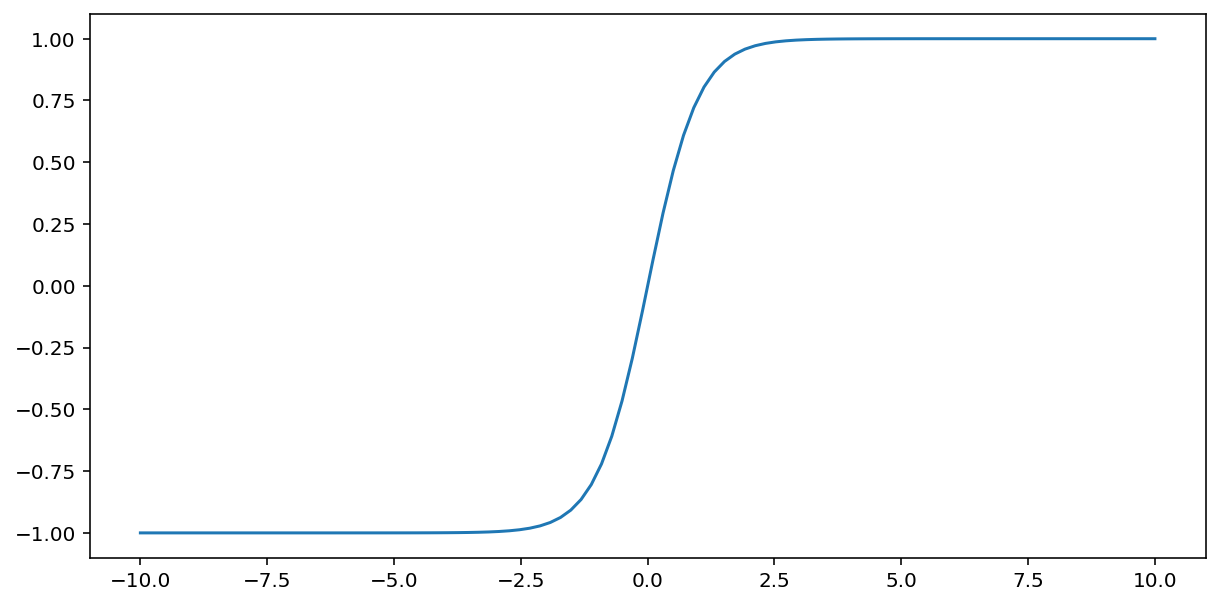
La fonction tanh (abréviation de "tangente hyperbolique") transforme l'entrée $x$ pour produire une valeur de sortie comprise entre -1 et 1:
\[F(x)=tanh(x)\]
Voici un graphique illustrant cette fonction:
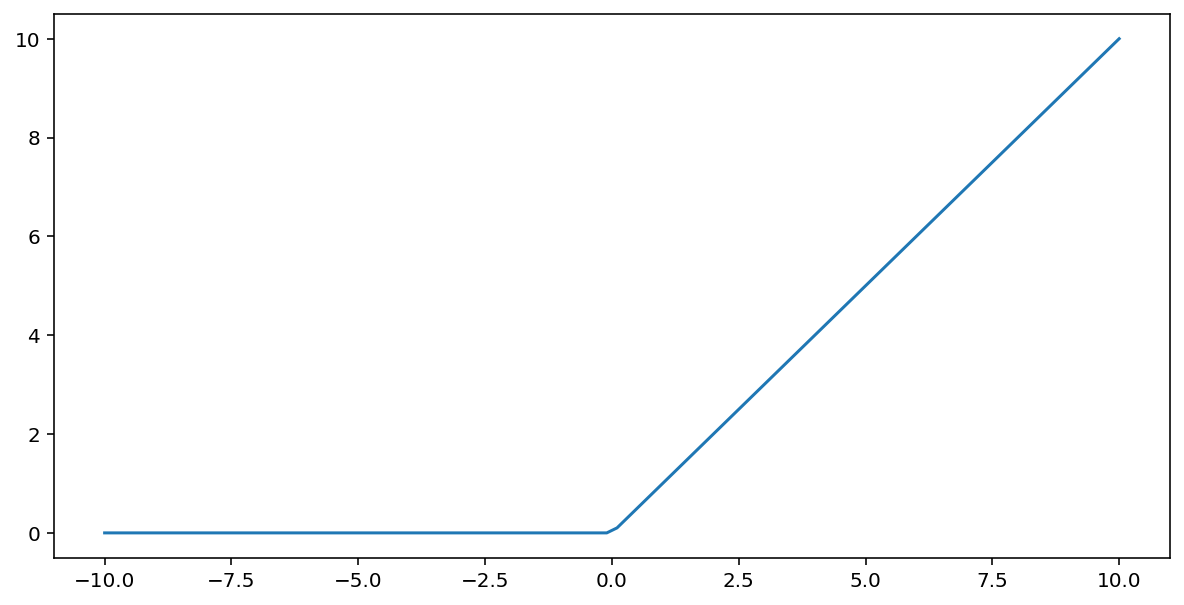
La fonction d'activation unité de rectification linéaire (ou ReLU, pour "rectified linear unit") transforme la sortie à l'aide de l'algorithme suivant:
- Si la valeur d'entrée $x$ est inférieure à 0, renvoyez 0.
- Si la valeur d'entrée $x$ est supérieure ou égale à 0, renvoie la valeur d'entrée.
La fonction ReLU peut être représentée mathématiquement à l'aide de la fonction max() :
Voici un graphique illustrant cette fonction:
La fonction ReLU fonctionne souvent un peu mieux en tant que fonction d'activation qu'une fonction lisse comme la fonction sigmoïde ou tanh, car elle est moins sujette au problème de gradient qui disparaît lors de l'entraînement de réseaux de neurones. La fonction ReLU est aussi beaucoup plus facile à calculer que ces fonctions.
Autres fonctions d'activation
En pratique, n'importe quelle fonction mathématique peut servir de fonction d'activation. Supposons que \(\sigma\) représente notre fonction d'activation. La valeur d'un nœud dans le réseau est donnée par la formule suivante:
Keras est compatible avec de nombreuses fonctions d'activation prêtes à l'emploi. Toutefois, nous vous recommandons de commencer par ReLU.
Résumé
La vidéo suivante récapitule tout ce que vous avez appris jusqu'à présent sur la construction des réseaux de neurones:
Notre modèle contient désormais tous les composants standards de ce que les gens désignent généralement par un réseau de neurones:
- Ensemble de nœuds, semblables à des neurones, organisés en couches.
- Ensemble de pondérations représentant les connexions entre chaque couche du réseau de neurones et la couche inférieure. Cette couche inférieure peut être une autre couche de réseau de neurones ou un autre type de couche.
- Un ensemble de biais, un par nœud.
- Fonction d'activation qui transforme la sortie de chaque nœud d'une couche. Les différentes couches peuvent avoir des fonctions d'activation différentes.
Attention: les réseaux de neurones ne sont pas toujours meilleurs que les croisements de caractéristiques, mais ils constituent une alternative flexible qui fonctionne bien dans de nombreux cas.