Anda telah melihat dalam latihan sebelumnya bahwa menambahkan lapisan tersembunyi ke jaringan saja tidak cukup untuk merepresentasikan non-linearitas. Operasi linear yang dilakukan pada operasi linear masih linear.
Bagaimana cara mengonfigurasi jaringan neural untuk mempelajari hubungan nonlinear antarnilai? Kita perlu cara untuk memasukkan operasi matematika nonlinear ke dalam model.
Jika ini tampak agak familier, itu karena kita sebenarnya telah menerapkan operasi matematika non-linear ke output model linear sebelumnya dalam materi. Dalam modul Logistic Regression, kita telah menyesuaikan model regresi linear untuk menghasilkan nilai berkelanjutan dari 0 hingga 1 (mewakili probabilitas) dengan meneruskan output model melalui fungsi sigmoid.
Kita dapat menerapkan prinsip yang sama ke jaringan neural. Mari kita lihat kembali model kita dari Latihan 2 sebelumnya, tetapi kali ini, sebelum menampilkan nilai setiap node, kita akan menerapkan fungsi sigmoid terlebih dahulu:
Coba ikuti penghitungan setiap node dengan mengklik tombol >| (di sebelah kanan tombol putar). Tinjau operasi matematika yang dilakukan untuk menghitung setiap nilai node di panel Penghitungan di bawah grafik. Perhatikan bahwa output setiap node kini adalah transformasi sigmoid dari kombinasi linear node di lapisan sebelumnya, dan semua nilai output dikompresi antara 0 dan 1.
Di sini, sigmoid berfungsi sebagai fungsi aktivasi untuk jaringan saraf, transformasi non-linear dari nilai output neuron sebelum nilai diteruskan sebagai input ke penghitungan lapisan neural berikutnya.
Setelah kita menambahkan fungsi aktivasi, penambahan lapisan memberikan dampak yang lebih besar. Dengan menyusun non-linearitas di atas non-linearitas memungkinkan kita memperagakan hubungan yang sangat rumit antara masukan dan keluaran yang diprediksi. Singkatnya, setiap lapisan secara efektif mempelajari fungsi tingkat tinggi yang lebih kompleks daripada input mentah. Jika Anda ingin mengembangkan lebih banyak intuisi tentang cara kerjanya, lihat postingan blog Chris Olah yang luar biasa.
Fungsi aktivasi umum
Tiga fungsi matematika yang biasa digunakan sebagai fungsi aktivasi adalah sigmoid, tanh, dan ReLU.
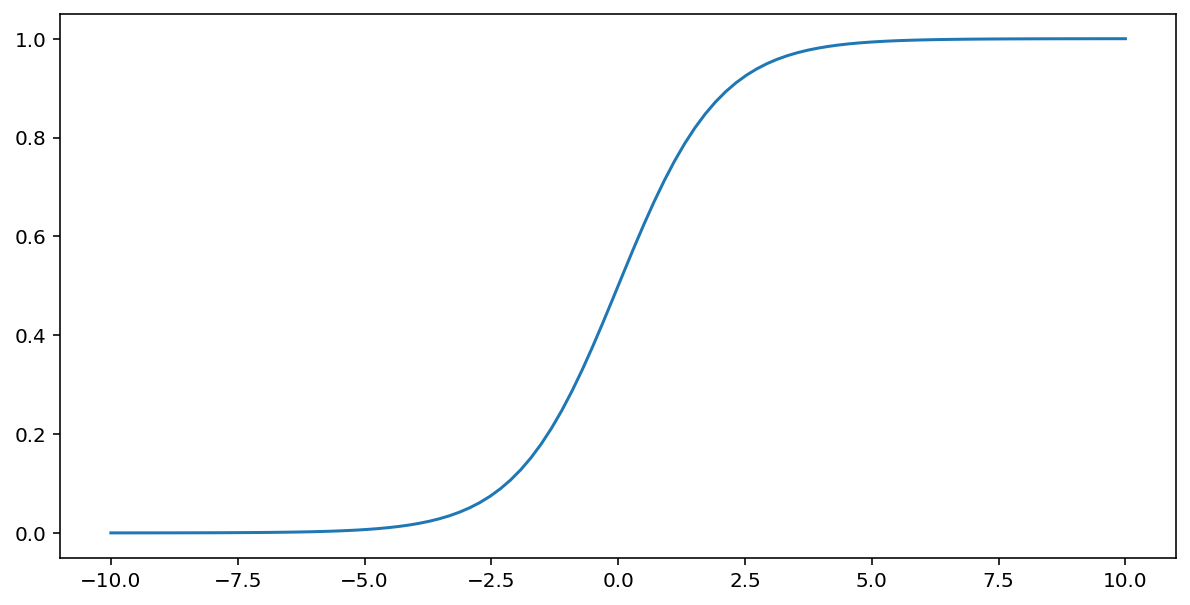
Fungsi sigmoid (dibahas di atas) melakukan transformasi berikut pada input $x$, yang menghasilkan nilai output antara 0 dan 1:
\[F(x)=\frac{1} {1+e^{-x}}\]
Berikut adalah plot fungsi ini:
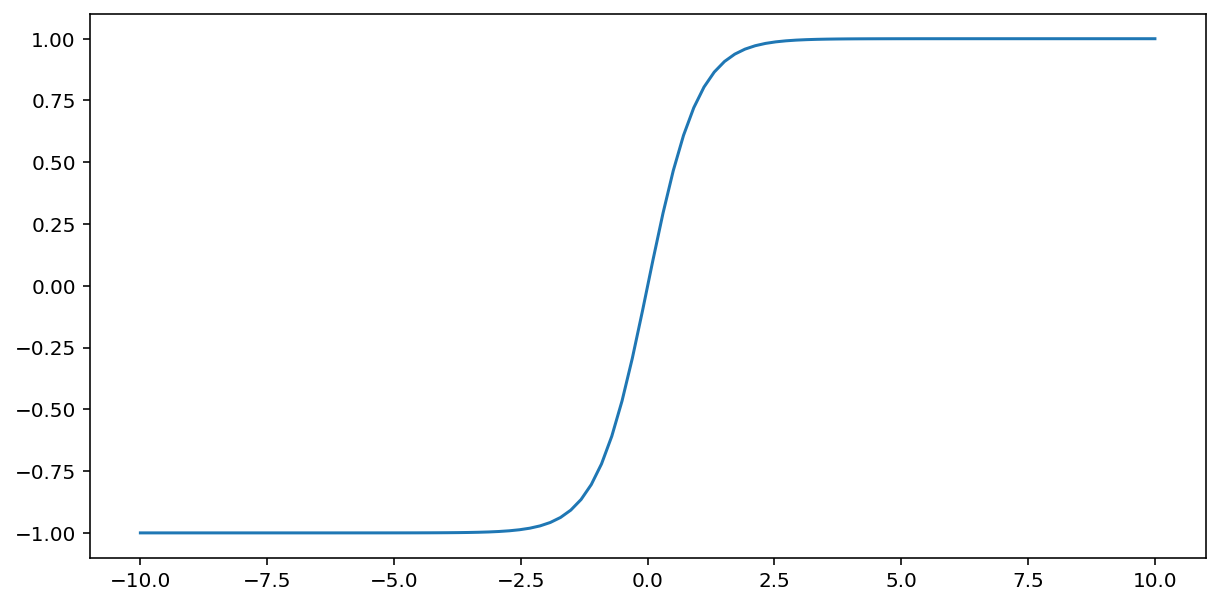
Fungsi tanh (singkatan dari "hyperbolic tangent") mengubah input $x$ untuk menghasilkan nilai output antara –1 dan 1:
\[F(x)=tanh(x)\]
Berikut adalah plot fungsi ini:
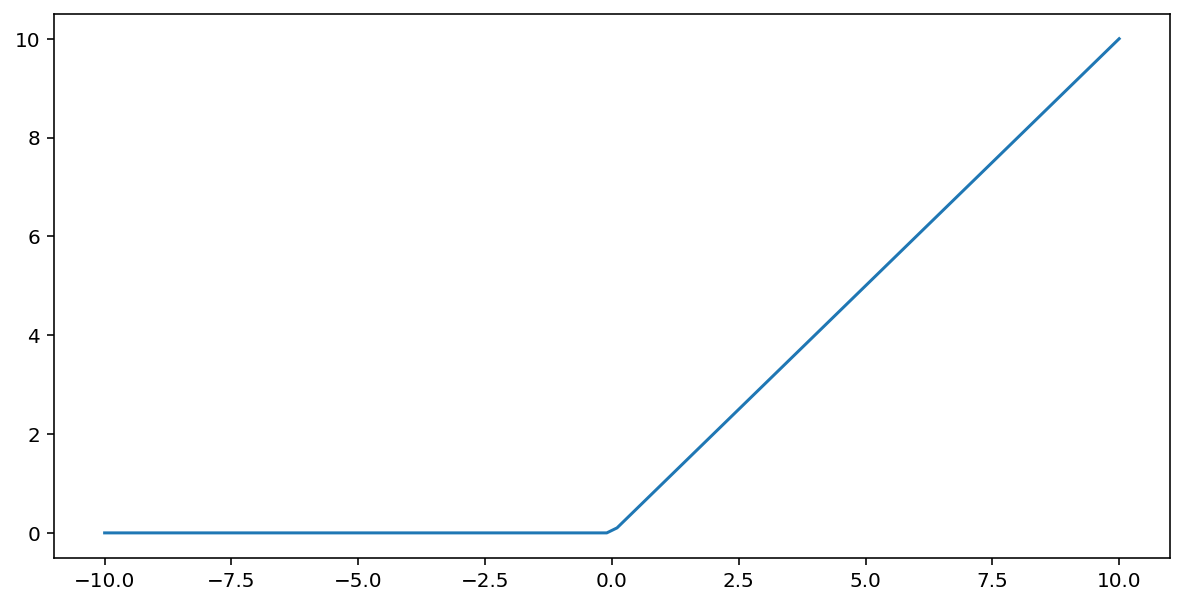
Fungsi aktivasi unit linear terarah (atau singkatnya ULT) mengubah output menggunakan algoritma berikut:
- Jika nilai input $x$ kurang dari 0, tampilkan 0.
- Jika nilai input $x$ lebih besar dari atau sama dengan 0, tampilkan nilai input.
ReLU dapat direpresentasikan secara matematis menggunakan fungsi max():
Berikut adalah plot fungsi ini:
ReLU sering berfungsi sedikit lebih baik sebagai fungsi aktivasi daripada fungsi mulus seperti sigmoid atau tanh, karena kurang rentan terhadap masalah gradien yang menghilang selama pelatihan jaringan saraf. ULT juga jauh lebih mudah dihitung daripada fungsi ini.
Fungsi aktivasi lainnya
Dalam praktiknya, fungsi matematika apa pun dapat berfungsi sebagai fungsi aktivasi. Anggap \(\sigma\) mewakili fungsi aktivasi kita. Nilai node dalam jaringan diberikan oleh formula berikut:
Keras memberikan dukungan siap pakai untuk banyak fungsi aktivasi. Meskipun demikian, sebaiknya mulailah dengan ReLU.
Ringkasan
Video berikut memberikan ringkasan tentang semua yang telah Anda pelajari sejauh ini tentang cara pembuatan jaringan saraf:
Sekarang model kita memiliki semua komponen standar dari apa yang biasanya dimaksud orang saat merujuk ke jaringan neural:
- Kumpulan node, yang analog dengan neuron, diatur dalam lapisan.
- Sekumpulan bobot yang mewakili koneksi antara setiap lapisan jaringan neural dan lapisan di bawahnya. Lapisan di bawahnya mungkin lapisan jaringan saraf lain, atau jenis lapisan lainnya.
- Serangkaian bias, satu untuk setiap node.
- Fungsi aktivasi yang mengubah output setiap node dalam lapisan. Lapisan yang berbeda mungkin memiliki fungsi aktivasi yang berbeda.
Peringatan: jaringan neural tidak selalu lebih baik daripada persilangan fitur, tetapi jaringan neural menawarkan alternatif fleksibel yang berfungsi dengan baik dalam banyak kasus.