先ほど、 バイナリ分類 次のような 2 つの選択肢から 1 つを選択できるモデル
- 該当するメールが迷惑メールであるか、迷惑メールではない。
- 対象の腫瘍は悪性または良性である。
このセクションでは マルチクラス分類 複数の可能性から選択できるモデルです。例:
- この犬はビーグルですか、バセットハウンド、ブラッドハウンドですか?
- この花はアヤメ属のアヤメ、オランダアイリス、アタマジラミ、 Dwarf Bearded Iris でしょうか。
- その飛行機は、ボーイング 747、エアバス 320、ボーイング 777、エンブラエル 190 ですか?
- これはリンゴ、クマ、キャンディ、犬、卵の画像ですか?
実世界のマルチクラス問題の中には、数百万ものものから選択することを伴うものもある 独立したクラスです。たとえば、1 対 1 のマルチクラス分類を あらゆる画像を識別できるモデルです
このセクションでは、マルチクラス分類の 2 つの主なバリアントについて詳しく説明します。
1 対すべて
One-vs.-all: バイナリ分類を使用する方法 複数の可能なラベルにわたる一連の「はい」または「いいえ」の予測を作成します。
N 個の可能な解を持つ分類問題の場合、1 対すべては N 個の独立したバイナリ分類器(1 つのバイナリ分類器)で 分類器を作成します。トレーニング中にモデルは 一連のバイナリ分類器でトレーニングし、それぞれが別の分類器に 分類問題です
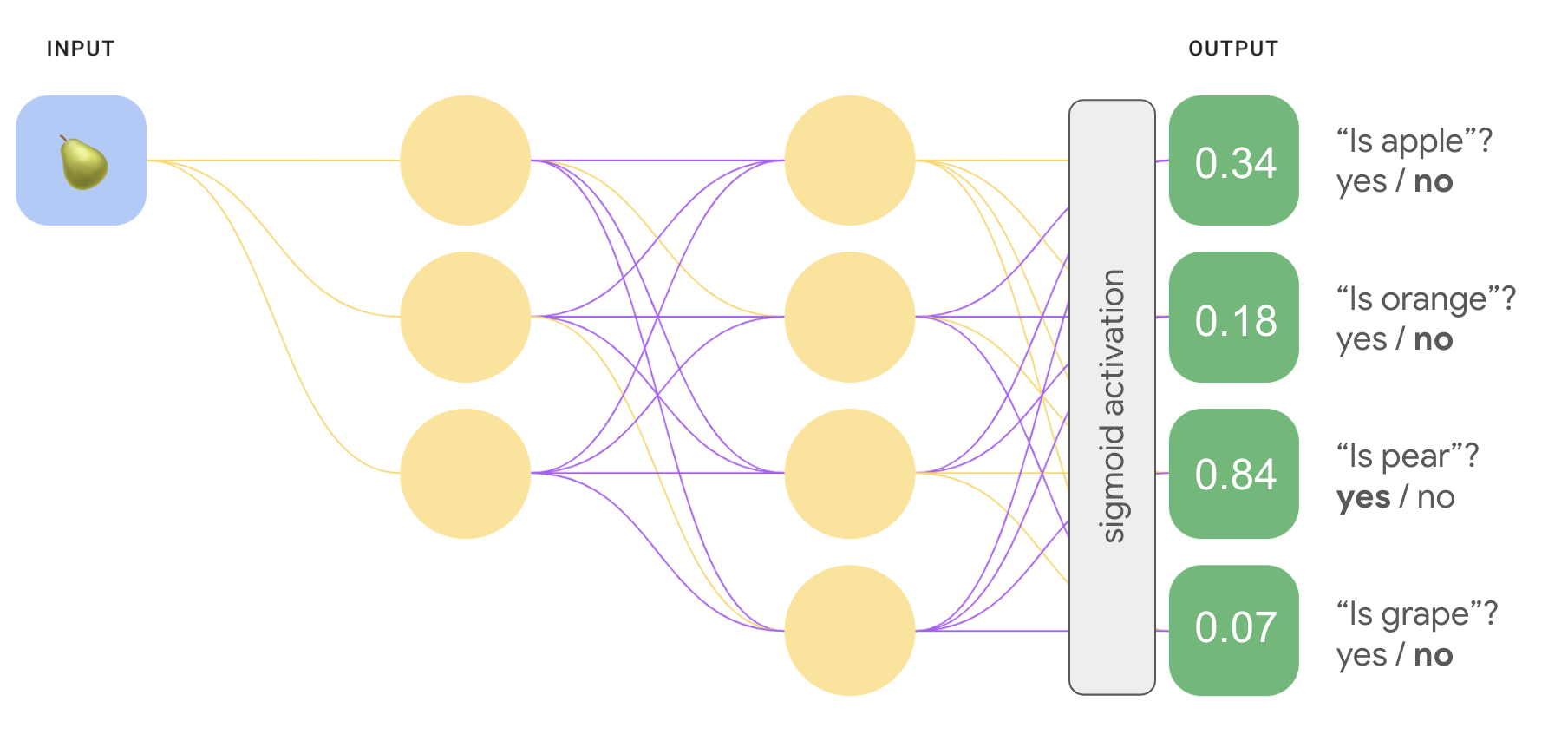
たとえば、1 切れの果物の写真の場合、 異なる認識ツールがトレーニングされる場合があり、それぞれ異なる「はい/いいえ」に応答する 質問:
- この画像はリンゴですか?
- この画像はオレンジ色ですか?
- この画像はバナナですか?
- この画像はブドウですか?
次の図は、これが実際にどのように機能するかを示しています。

このアプローチは、クラスの合計数が リソース クラスの数が増えれば増えるほど、 高くなります。
はるかに効率的な 1 対 1 のモデルを作成できる ディープ ニューラル ネットワークでは、各出力ノードはそれぞれ異なる クラスです。次の図は、この方法を示しています。
1 対 1(ソフトマックス)
お気づきかもしれませんが、図 8 の出力層にある確率値は、 合計が 1.0(100%)にならないようにしてください。(合計で 1.43 になります)。1 対オールで 各バイナリセットの結果の確率が 他のセットとは無関係に生成しますつまり、単語群の中から 1 つを 「リンゴ」「Apple 以外」との比較他の予測モデルの可能性を考慮せずに 果物のオプション: 「オレンジ」、「ナシ」、「ブドウ」
しかし、各果物の確率を予測するには どうなるでしょうかこの例では「apple」と予測するのではなく「not 「apple」と予測し、「apple」と「orange」との比較「pear」との比較検索します このタイプのマルチクラス分類は、1 対 1 の分類と呼ばれます。
同じタイプのニューラル ネットワークを使用して、1 対 1 の分類を実装できます。 ネットワーク アーキテクチャを使用しますが、重要な変更が 1 つあります。 出力レイヤに別の変換を適用する必要があります。
1 対すべてでは、シグモイド活性化関数を各出力に適用しました。 各ノードに 0 ~ 1 の範囲の出力値があり、 合計が 1 になるという保証はありませんでした。
1 対 1 の場合は、代わりに softmax という関数を適用して、 マルチクラス問題の各クラスに小数点の確率を割り当て、 すべての確率の合計が 1.0 になる。この追加の制約により、 トレーニングの収束が速くなります。
次の図は、1 対オールのマルチクラス分類を再実装しています。 1 対 1 のタスクとして扱うことができます。なお、ソフトマックスを実行するために、 出力層(ソフトマックス レイヤ)の直前のレイヤに、 出力レイヤと同じ数のノードを使用します。
<ph type="x-smartling-placeholder"> <ph type="x-smartling-placeholder">
<ph type="x-smartling-placeholder">ソフトマックス オプション
ソフトマックスの次のバリアントについて考えてみましょう。
完全なソフトマックスは、前述のソフトマックスです。つまり ソフトマックスは、可能性のあるすべてのクラスの確率を計算します。
候補サンプリング: ソフトマックスで確率を計算する すべての陽性ラベルに対して 検出します。たとえば 入力画像がビーグルでもブラッドハウンドでも、 犬以外のすべてのサンプルの確率を提供します。
クラス数が少ない場合、完全なソフトマックスは低コストで実施できる クラスの数が増えると法外な費用がかかります。 候補のサンプリングは、大規模な クラスの数によって決まります。
1 つのラベルと多数のラベル
Softmax では、各例が 1 つのクラスのみのメンバーであることを前提としています。 ただし、一部の例は同時に複数のクラスのメンバーになることができます。 そのような場合の例:
- ソフトマックスは使用できません。
- 複数のロジスティック回帰に依存する必要がある。
たとえば、上の図 9 の 1 対 1 のモデルでは、 この画像は、リンゴ、オレンジ、ナシ、または ブドウです。ただし、入力画像に複数の種類の果物が含まれている場合がある。 (リンゴとオレンジが入ったボウルに)複数のロジスティックを 回帰を使用します。