Il binning (chiamato anche bucketing) è un
feature engineering
tecnica che raggruppa diversi sottointervalli numerici in bin o
bucket.
In molti casi, il binning trasforma i dati numerici in dati categorici.
Ad esempio, considera una caratteristica
denominato X, il cui valore più basso è 15
il valore più alto è 425. Utilizzando il binning, potresti rappresentare X con il
dopo cinque bin:
- Fascia 1: da 15 a 34
- Fascia 2: da 35 a 117
- Fascia 3: da 118 a 279
- Fascia 4: da 280 a 392
- Fascia 5: da 393 a 425
Il bin 1 comprende l'intervallo da 15 a 34, quindi ogni valore di X compreso tra 15 e 34
finisce nello spazio 1. Un modello addestrato su questi bin non reagirà in modo diverso
a X valori di 17 e 29 poiché entrambi i valori si trovano nella fascia 1.
Il vettore di caratteristiche rappresenta i cinque bin come segue:
| Numero bin | Intervallo | Vettore di caratteristiche |
|---|---|---|
| 1 | 15-34 | [1,0; 0,0; 0,0; 0,0; 0,0] |
| 2 | 35-117 | [0,0; 1,0; 0,0; 0,0; 0,0] |
| 3 | 118-279 | [0,0; 0,0; 1,0; 0,0; 0,0] |
| 4 | 280-392 | [0,0; 0,0; 0,0; 1,0; 0,0] |
| 5 | 393-425 | [0,0; 0,0; 0,0; 0,0; 1,0] |
Anche se X è una singola colonna nel set di dati, il binning fa sì che il modello
per trattare X come cinque caratteristiche separate. Di conseguenza, il modello apprende
pesi separati per ogni fascia.
Il binning è una buona alternativa alla scalabilità. o clip quando uno dei due le seguenti condizioni sono soddisfatte:
- La relazione lineare complessiva tra la caratteristica e label: è debole o inesistente.
- Quando i valori delle caratteristiche sono in cluster.
Il binning può sembrare controintuitivo, dato che il modello nell'esempio precedente i valori 37 e 115 sono identici. Ma quando una caratteristica appare più compresa rispetto alla linea, il binning è un modo molto migliore per rappresentano i dati.
Esempio di binning: numero di acquirenti rispetto alla temperatura
Supponi di dover creare un modello che prevede il numero gli acquirenti in base alla temperatura esterna per quel giorno. Ecco un grafico della temperatura rispetto al numero di acquirenti:
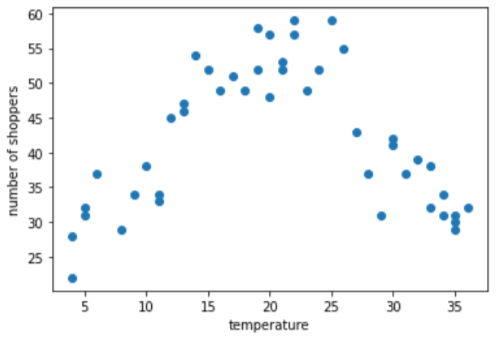
La trama mostra, non sorprende, che il numero di acquirenti sia stato più alto quando la temperatura era più confortevole.
È possibile rappresentare la caratteristica come valori non elaborati: una temperatura di 35,0 nel sarebbe 35,0 nel vettore di caratteristiche. È l'idea migliore?
Durante l'addestramento, un modello di regressione lineare apprende un singolo peso per ogni funzionalità. Pertanto, se la temperatura è rappresentata come una singola caratteristica, allora una temperatura di 35,0 avrebbe cinque volte l'influenza (o un quinto del influenzale) in una previsione come una temperatura di 7,0. Tuttavia, la trama non mostrare qualsiasi tipo di relazione lineare tra l'etichetta e valore della caratteristica.
Il grafico suggerisce tre cluster nei seguenti sottointervalli:
- Lo scomparto 1 è l'intervallo di temperatura da 4 a 11.
- Lo scomparto 2 è l'intervallo di temperatura 12-26.
- Lo scomparto 3 è l'intervallo di temperatura 27-36.
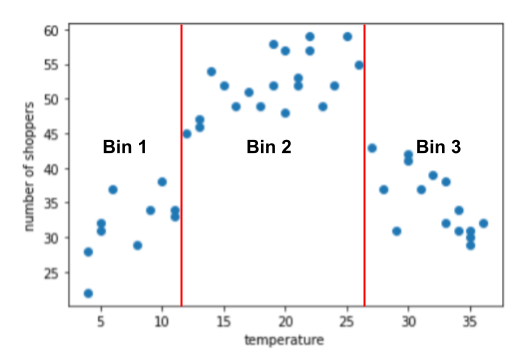
Il modello apprende pesi separati per ogni fascia.
Sebbene sia possibile creare più di tre bin, anche uno separato per lettura di ogni temperatura, spesso questa è una cattiva idea per i seguenti motivi:
- Un modello può apprendere l'associazione tra un contenitore e un'etichetta solo se sono presenti ci sono abbastanza esempi in quella barra. Nell'esempio, ognuno dei 3 bin contiene almeno 10 esempi, che potrebbero essere sufficienti per l'addestramento. Con 33 bin separati, nessuno dei bin conterrà abbastanza esempi per l'addestramento del modello.
- Una convezione separata per ogni temperatura genera 33 funzionalità separate per la temperatura. Tuttavia, in genere dovresti ridurre al minimo il numero di caratteristiche in un modello.
Allenamento: verifica le tue conoscenze
Il seguente grafico mostra il prezzo medio di una casa per ogni 0,2 gradi di latitudine del mitico paese della Freedonia:
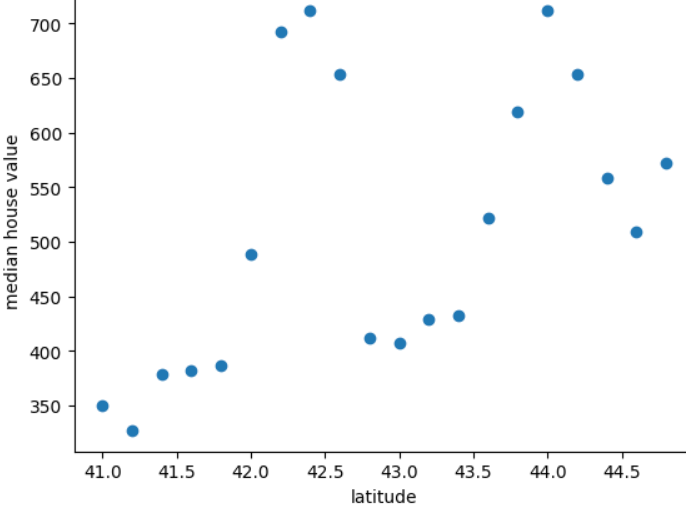
L'immagine mostra uno schema non lineare tra il valore della casa e la latitudine, pertanto è improbabile che rappresentare la latitudine come valore in virgola mobile un modello può fare buone previsioni. Forse raggruppare le latitudini sarebbe meglio idea?
- Da 41,0 a 41,8
- Da 42,0 a 42,6
- Da 42,8 a 43,4
- Da 43,6 a 44,8
Bucketing dei quantili
Il bucketing dei quantili crea limiti di bucketing in modo che il numero di esempi in ciascun bucket è esattamente o quasi uguale. Bucketing dei quantili nasconde perlopiù i valori anomali.
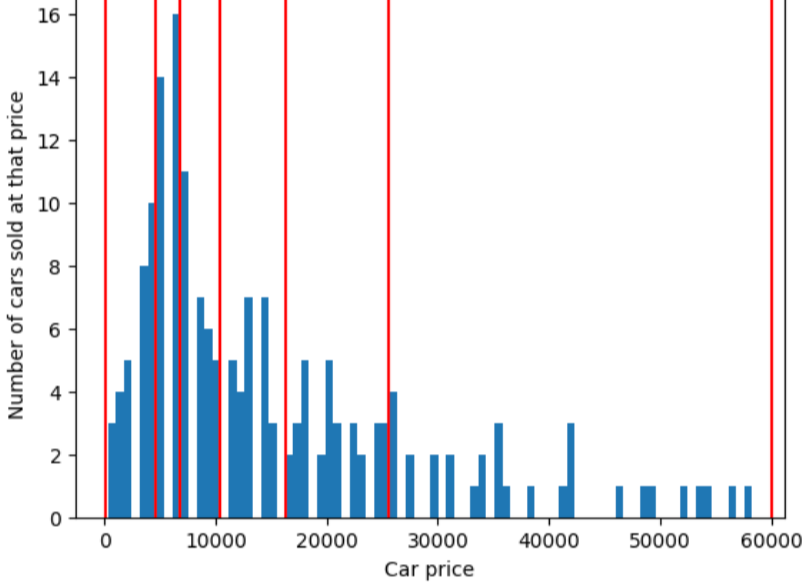
Per illustrare il problema che viene risolto dal bucketing dei quantili, considera la con la stessa spaziatura mostrata nella figura seguente, in cui dei dieci bucket rappresenta un intervallo di esattamente 10.000 dollari. Nota che il bucket da 0 a 10.000 contiene decine di esempi ma il bucket da 50.000 a 60.000 contiene solo 5 esempi. Di conseguenza, il modello ha un numero sufficiente di esempi per l’addestramento da 0 a 10.000 ma non ci sono abbastanza esempi su cui eseguire l'addestramento per il bucket da 50.000 a 60.000.
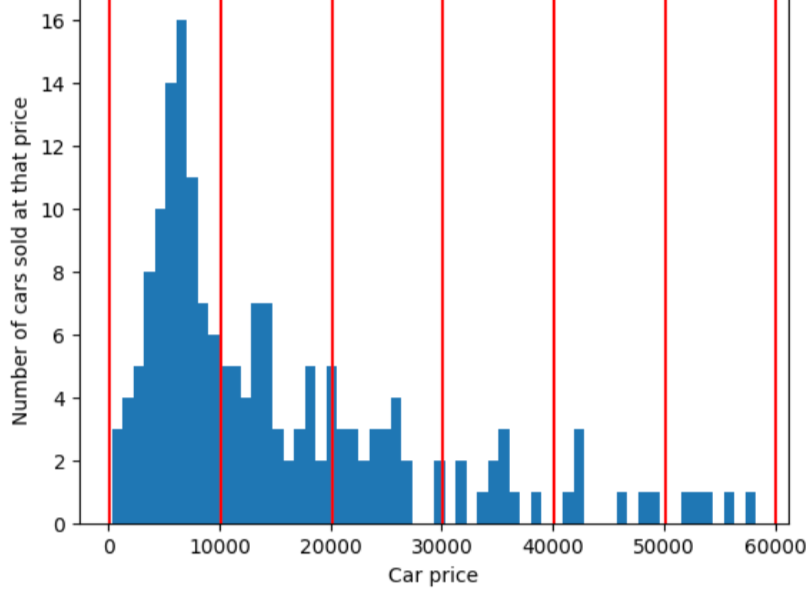
Al contrario, la figura seguente utilizza il bucketing dei quantili per dividere i prezzi delle auto in bin con circa lo stesso numero di esempi in ciascun bucket. Nota che alcune fasce di prezzo prevedono un intervallo di prezzo ristretto, mentre altre prevedono una fascia di prezzo molto ampia.