পরিসংখ্যানগত এবং ভিজ্যুয়ালাইজেশন কৌশলগুলির মাধ্যমে আপনার ডেটা পরীক্ষা করার পরে, আপনার ডেটাকে এমনভাবে রূপান্তরিত করা উচিত যা আপনার মডেলকে আরও কার্যকরভাবে প্রশিক্ষণ দিতে সহায়তা করবে। স্বাভাবিককরণের লক্ষ্য হল বৈশিষ্ট্যগুলিকে একই স্কেলে রূপান্তর করা। উদাহরণস্বরূপ, নিম্নলিখিত দুটি বৈশিষ্ট্য বিবেচনা করুন:
- ফিচার
X154 থেকে 24,917,482 পর্যন্ত বিস্তৃত। - বৈশিষ্ট্য
Y5 থেকে 22 পর্যন্ত বিস্তৃত।
এই দুটি বৈশিষ্ট্য খুব ভিন্ন পরিসীমা বিস্তৃত. সাধারণীকরণ X এবং Y ম্যানিপুলেট করতে পারে যাতে তারা একটি অনুরূপ পরিসর বিস্তৃত করে, সম্ভবত 0 থেকে 1।
স্বাভাবিককরণ নিম্নলিখিত সুবিধা প্রদান করে:
- প্রশিক্ষণের সময় মডেলদের আরও দ্রুত একত্রিত হতে সাহায্য করে। যখন বিভিন্ন বৈশিষ্ট্যের বিভিন্ন রেঞ্জ থাকে, তখন গ্রেডিয়েন্ট ডিসেন্ট "বাউন্স" এবং ধীর অভিসারণ করতে পারে। এটি বলেছে, অ্যাডাগ্রাড এবং অ্যাডামের মতো আরও উন্নত অপ্টিমাইজাররা সময়ের সাথে কার্যকর শেখার হার পরিবর্তন করে এই সমস্যা থেকে রক্ষা করে।
- মডেলগুলিকে আরও ভাল ভবিষ্যদ্বাণী করতে সাহায্য করে৷ যখন বিভিন্ন বৈশিষ্ট্যের বিভিন্ন ব্যাপ্তি থাকে, তখন ফলস্বরূপ মডেলটি কিছুটা কম দরকারী ভবিষ্যদ্বাণী করতে পারে।
- বৈশিষ্ট্যের মান খুব বেশি হলে "NaN ফাঁদ" এড়াতে সাহায্য করে। NaN একটি সংখ্যার জন্য একটি সংক্ষিপ্ত রূপ। যখন একটি মডেলের একটি মান ফ্লোটিং-পয়েন্ট নির্ভুলতা সীমা অতিক্রম করে, সিস্টেমটি একটি সংখ্যার পরিবর্তে মানটিকে
NaNএ সেট করে। মডেলের একটি নম্বর যখন NaN হয়ে যায়, মডেলের অন্যান্য সংখ্যাও শেষ পর্যন্ত NaN হয়ে যায়। - মডেলটিকে প্রতিটি বৈশিষ্ট্যের জন্য উপযুক্ত ওজন শিখতে সাহায্য করে। বৈশিষ্ট্য স্কেলিং ছাড়া, মডেলটি বিস্তৃত পরিসরের বৈশিষ্ট্যগুলিতে খুব বেশি মনোযোগ দেয় এবং সংকীর্ণ পরিসরের বৈশিষ্ট্যগুলিতে যথেষ্ট মনোযোগ দেয় না।
আমরা সাংখ্যিক বৈশিষ্ট্যগুলিকে স্বাভাবিক করার পরামর্শ দিই যা স্বতন্ত্রভাবে বিভিন্ন ব্যাপ্তি (উদাহরণস্বরূপ, বয়স এবং আয়) কভার করে। আমরা city population.
নিম্নলিখিত দুটি বৈশিষ্ট্য বিবেচনা করুন:
- বৈশিষ্ট্য
Aএর সর্বনিম্ন মান হল -0.5 এবং সর্বোচ্চ হল +0.5৷ - বৈশিষ্ট্য
Bএর সর্বনিম্ন মান হল -5.0 এবং সর্বোচ্চ হল +5.0৷
বৈশিষ্ট্য A এবং বৈশিষ্ট্য B তুলনামূলকভাবে সংকীর্ণ স্প্যান রয়েছে। যাইহোক, ফিচার B এর স্প্যান ফিচার A এর স্প্যানের চেয়ে 10 গুণ বেশি প্রশস্ত। অতএব:
- প্রশিক্ষণের শুরুতে, মডেলটি অনুমান করে যে বৈশিষ্ট্য
Bবৈশিষ্ট্যAএর চেয়ে দশগুণ বেশি "গুরুত্বপূর্ণ"। - ট্রেনিং এর চেয়ে বেশি সময় লাগবে।
- ফলস্বরূপ মডেল সাবঅপ্টিমাল হতে পারে।
স্বাভাবিক না করার কারণে সামগ্রিক ক্ষতি তুলনামূলকভাবে ছোট হবে; যাইহোক, আমরা এখনও ফিচার A এবং ফিচার Bকে একই স্কেলে স্বাভাবিক করার পরামর্শ দিই, সম্ভবত -1.0 থেকে +1.0৷
এখন ব্যাপ্তির বৃহত্তর বৈষম্য সহ দুটি বৈশিষ্ট্য বিবেচনা করুন:
- বৈশিষ্ট্য
Cএর সর্বনিম্ন মান হল -1 এবং সর্বোচ্চ হল +1৷ - বৈশিষ্ট্য
Dএর সর্বনিম্ন মান +5000 এবং সর্বোচ্চ +1,000,000,000।
আপনি যদি বৈশিষ্ট্য C এবং বৈশিষ্ট্য D কে স্বাভাবিক না করেন, আপনার মডেল সম্ভবত সাবঅপ্টিমাল হবে। অধিকন্তু, প্রশিক্ষণ একত্রিত হতে অনেক বেশি সময় নেবে বা এমনকি সম্পূর্ণরূপে একত্রিত হতে ব্যর্থ হবে!
এই বিভাগে তিনটি জনপ্রিয় স্বাভাবিককরণ পদ্ধতি কভার করে:
- রৈখিক স্কেলিং
- জেড-স্কোর স্কেলিং
- লগ স্কেলিং
এই বিভাগটি অতিরিক্তভাবে ক্লিপিং কভার করে। যদিও একটি সত্যিকারের স্বাভাবিকীকরণ কৌশল নয়, ক্লিপিং অবাস্তব সংখ্যাগত বৈশিষ্ট্যগুলিকে এমন রেঞ্জে পরিণত করে যা আরও ভাল মডেল তৈরি করে।
রৈখিক স্কেলিং
রৈখিক স্কেলিং (সাধারণত সংক্ষিপ্ত করে শুধু স্কেলিং ) মানে ফ্লোটিং-পয়েন্ট মানগুলিকে তাদের প্রাকৃতিক পরিসর থেকে একটি আদর্শ পরিসরে রূপান্তর করা—সাধারণত 0 থেকে 1 বা -1 থেকে +1।
লিনিয়ার স্কেলিং একটি ভাল পছন্দ যখন নিম্নলিখিত সমস্ত শর্ত পূরণ হয়:
- আপনার ডেটার নিম্ন এবং উপরের সীমা সময়ের সাথে খুব বেশি পরিবর্তিত হয় না।
- বৈশিষ্ট্যটিতে কয়েকটি বা কোন আউটলায়ার নেই এবং সেই বহিরাগতগুলি চরম নয়।
- বৈশিষ্ট্যটি প্রায় অভিন্নভাবে এর পরিসীমা জুড়ে বিতরণ করা হয়। অর্থাৎ, একটি হিস্টোগ্রাম বেশিরভাগ মানের জন্য মোটামুটি এমনকি বার দেখাবে।
ধরুন মানুষের age একটি বৈশিষ্ট্য। লিনিয়ার স্কেলিং age জন্য একটি ভাল স্বাভাবিককরণ কৌশল কারণ:
- আনুমানিক নিম্ন এবং উপরের সীমানা 0 থেকে 100।
-
ageঅপেক্ষাকৃত ছোট শতাংশ বহিরাগতদের ধারণ করে। জনসংখ্যার মাত্র 0.3% 100-এর বেশি। - যদিও নির্দিষ্ট বয়সগুলি অন্যদের তুলনায় কিছুটা ভালভাবে উপস্থাপন করা হয়, একটি বড় ডেটাসেটে সমস্ত বয়সের জন্য যথেষ্ট উদাহরণ থাকা উচিত।
অনুশীলন: আপনার বোঝার পরীক্ষা করুন
ধরুন আপনার মডেলেnet_worth নামে একটি বৈশিষ্ট্য রয়েছে যা বিভিন্ন ব্যক্তির নেট মূল্য ধরে রাখে। লিনিয়ার স্কেলিং কি net_worth জন্য একটি ভাল স্বাভাবিককরণ কৌশল হবে? কেনই বা হবে না? জেড-স্কোর স্কেলিং
একটি Z-স্কোর হল মান থেকে একটি মান বিচ্যুতির সংখ্যা। উদাহরণ স্বরূপ, গড় থেকে 2 মানক বিচ্যুতি বেশি হলে তার Z-স্কোর +2.0 থাকে। গড় থেকে 1.5 মান বিচ্যুতি কম একটি মান -1.5 এর Z-স্কোর আছে।
Z-স্কোর স্কেলিং সহ একটি বৈশিষ্ট্যকে উপস্থাপন করার অর্থ হল বৈশিষ্ট্য ভেক্টরে সেই বৈশিষ্ট্যটির Z-স্কোর সংরক্ষণ করা। উদাহরণস্বরূপ, নিম্নলিখিত চিত্রটি দুটি হিস্টোগ্রাম দেখায়:
- বাম দিকে, একটি ক্লাসিক স্বাভাবিক বিতরণ।
- ডানদিকে, একই বন্টন জেড-স্কোর স্কেলিং দ্বারা স্বাভাবিক করা হয়েছে।
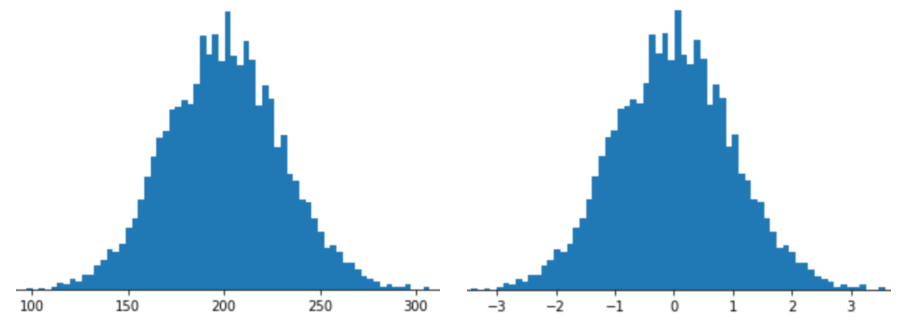
Z-স্কোর স্কেলিং নিম্নলিখিত চিত্রে দেখানো ডেটার জন্যও একটি ভাল পছন্দ, যার শুধুমাত্র একটি অস্পষ্টভাবে স্বাভাবিক বন্টন রয়েছে।
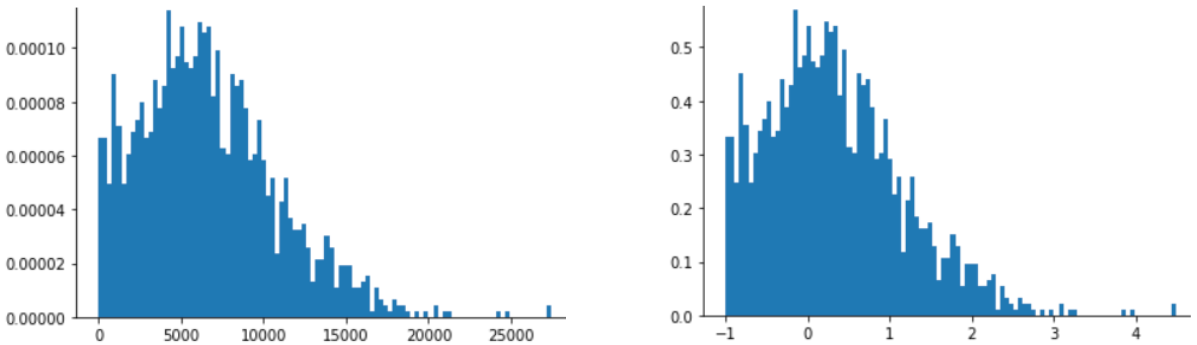
Z-স্কোর একটি ভাল পছন্দ যখন ডেটা একটি স্বাভাবিক বিতরণ বা বিতরণকে কিছুটা সাধারণ বিতরণের মতো অনুসরণ করে।
মনে রাখবেন যে কিছু বিতরণ তাদের পরিসরের বাল্কের মধ্যে স্বাভাবিক হতে পারে, কিন্তু এখনও চরম বহিরাগত ধারণ করে। উদাহরণস্বরূপ, একটি net_worth বৈশিষ্ট্যের প্রায় সমস্ত পয়েন্ট সুন্দরভাবে 3টি স্ট্যান্ডার্ড বিচ্যুতিতে ফিট হতে পারে, তবে এই বৈশিষ্ট্যের কয়েকটি উদাহরণ গড় থেকে শত শত স্ট্যান্ডার্ড বিচ্যুতি হতে পারে। এই পরিস্থিতিতে, আপনি এই পরিস্থিতি পরিচালনা করার জন্য স্বাভাবিককরণের (সাধারণত ক্লিপিং) অন্য ফর্মের সাথে জেড-স্কোর স্কেলিংকে একত্রিত করতে পারেন।
অনুশীলন: আপনার বোঝার পরীক্ষা করুন
ধরুন আপনার মডেলheight নামের একটি বৈশিষ্ট্যের উপর ট্রেনিং করে যা দশ মিলিয়ন মহিলার প্রাপ্তবয়স্ক উচ্চতাকে ধরে রাখে। জেড-স্কোর স্কেলিং height জন্য একটি ভাল স্বাভাবিককরণ কৌশল হবে? কেনই বা হবে না? লগ স্কেলিং
লগ স্কেলিং কাঁচা মানের লগারিদম গণনা করে। তাত্ত্বিকভাবে, লগারিদম যেকোনো ভিত্তি হতে পারে; অনুশীলনে, লগ স্কেলিং সাধারণত প্রাকৃতিক লগারিদম (ln) গণনা করে।
লগ স্কেলিং সহায়ক যখন ডেটা একটি পাওয়ার আইন বন্টনের সাথে সামঞ্জস্যপূর্ণ। সাধারণভাবে বলতে গেলে, একটি পাওয়ার আইন বন্টন নিম্নরূপ দেখায়:
-
Xএর কম মানগুলিরYএর খুব বেশি মান রয়েছে। -
Xএর মান বাড়ার সাথে সাথেYএর মান দ্রুত হ্রাস পায়। ফলস্বরূপ,Xএর উচ্চ মানেরYএর মান খুবই কম।
মুভি রেটিং একটি ক্ষমতা আইন বন্টন একটি ভাল উদাহরণ. নিম্নলিখিত চিত্রে, লক্ষ্য করুন:
- কয়েকটি সিনেমার প্রচুর ব্যবহারকারীর রেটিং রয়েছে। (
Xএর নিম্ন মানYএর উচ্চ মান রয়েছে।) - বেশিরভাগ সিনেমার ব্যবহারকারীর রেটিং খুবই কম। (
Xএর উচ্চ মানেরYএর মান কম।)
লগ স্কেলিং বন্টন পরিবর্তন করে, যা একটি মডেলকে প্রশিক্ষণ দিতে সাহায্য করে যা আরও ভাল ভবিষ্যদ্বাণী করবে।

দ্বিতীয় উদাহরণ হিসাবে, বই বিক্রয় একটি পাওয়ার আইন বন্টনের সাথে সামঞ্জস্যপূর্ণ কারণ:
- বেশিরভাগ প্রকাশিত বই অল্প সংখ্যক কপি বিক্রি করে, হয়তো এক বা দুইশত।
- কিছু বই মাঝারি সংখ্যক কপি বিক্রি করে, হাজারে।
- মাত্র কয়েকটি বেস্টসেলারই এক মিলিয়নের বেশি কপি বিক্রি করবে।
ধরুন আপনি বই বিক্রির সাথে বইয়ের কভারের সম্পর্ক খুঁজে পেতে একটি লিনিয়ার মডেলকে প্রশিক্ষণ দিচ্ছেন। কাঁচা মানগুলির উপর একটি রৈখিক মডেল প্রশিক্ষণ এমন বইগুলির বইয়ের কভার সম্পর্কে কিছু খুঁজে বের করতে হবে যা এক মিলিয়ন কপি বিক্রি করে যা শুধুমাত্র 100টি কপি বিক্রি করা বইয়ের কভারের চেয়ে 10,000 বেশি শক্তিশালী৷ যাইহোক, সমস্ত বিক্রয় পরিসংখ্যান লগ স্কেলিং কাজটিকে অনেক বেশি সম্ভাব্য করে তোলে। উদাহরণস্বরূপ, 100 এর লগ হল:
~4.6 = ln(100)
যখন 1,000,000 এর লগ হল:
~13.8 = ln(1,000,000)
সুতরাং, 1,000,000-এর লগটি 100-এর লগের চেয়ে প্রায় তিনগুণ বড়। আপনি সম্ভবত একটি বেস্টসেলার বইয়ের কভার একটি ছোট-বিক্রীত বইয়ের কভারের চেয়ে প্রায় তিনগুণ বেশি শক্তিশালী (কোনও উপায়ে) কল্পনা করতে পারেন ।
ক্লিপিং
ক্লিপিং চরম বহিরাগতদের প্রভাব কমানোর একটি কৌশল। সংক্ষেপে, ক্লিপিং সাধারণত আউটলারের মানকে একটি নির্দিষ্ট সর্বোচ্চ মান পর্যন্ত ক্যাপ করে (কমায়)। ক্লিপিং একটি অদ্ভুত ধারণা, এবং এখনও, এটি খুব কার্যকর হতে পারে।
উদাহরণস্বরূপ, একটি ডেটাসেট কল্পনা করুন যেখানে roomsPerPerson নামক একটি বৈশিষ্ট্য রয়েছে, যা বিভিন্ন বাড়ির জন্য কক্ষের সংখ্যা (অধিবাসীর সংখ্যা দ্বারা বিভক্ত মোট কক্ষ) প্রতিনিধিত্ব করে। নিম্নলিখিত প্লটটি দেখায় যে বৈশিষ্ট্যের মানগুলির 99% এরও বেশি একটি সাধারণ বিতরণের সাথে সামঞ্জস্যপূর্ণ (মোটামুটি, গড় 1.8 এবং 0.7 এর একটি আদর্শ বিচ্যুতি)। যাইহোক, বৈশিষ্ট্যটিতে কয়েকটি বহিরাগত রয়েছে, যার মধ্যে কিছু চরম:
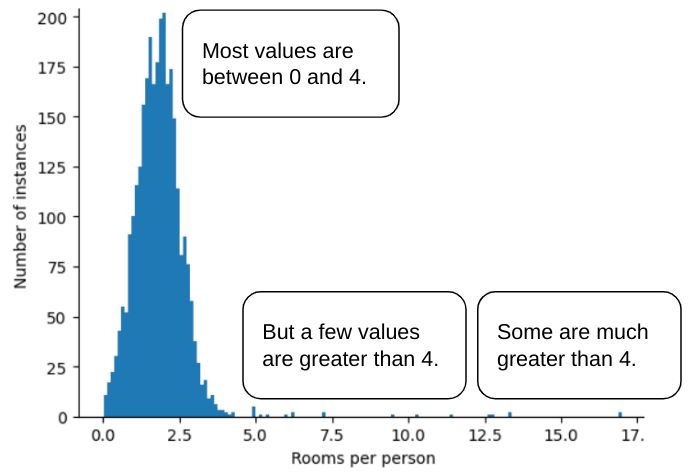
আপনি কিভাবে এই চরম বহিরাগতদের প্রভাব কমাতে পারেন? ঠিক আছে, হিস্টোগ্রাম একটি সমান বিতরণ, একটি সাধারণ বিতরণ, বা একটি শক্তি আইন বিতরণ নয়। আপনি যদি roomsPerPerson এর সর্বোচ্চ মান নির্বিচারে ক্যাপ বা ক্লিপ করেন , তাহলে 4.0 বলুন?
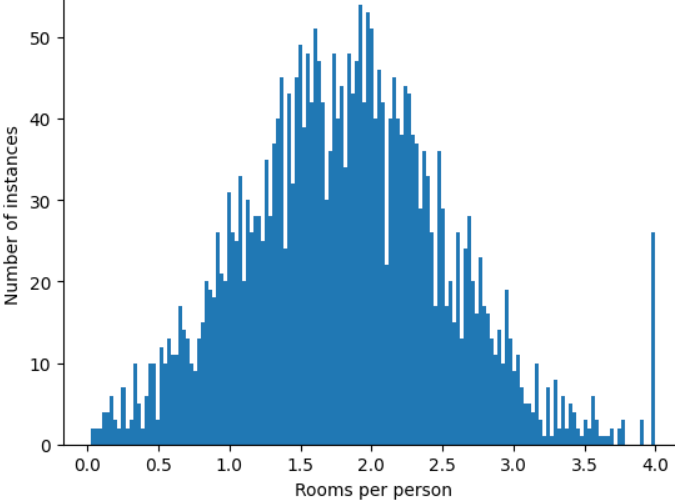
বৈশিষ্ট্য মান 4.0 এ ক্লিপ করার অর্থ এই নয় যে আপনার মডেল 4.0-এর চেয়ে বড় সমস্ত মানকে উপেক্ষা করে৷ বরং, এর মানে হল যে সমস্ত মান 4.0-এর থেকে বড় ছিল এখন 4.0 হয়ে গেছে। এটি 4.0 এ অদ্ভুত পাহাড়কে ব্যাখ্যা করে। সেই পাহাড় সত্ত্বেও, স্কেল করা বৈশিষ্ট্য সেটটি এখন মূল ডেটার চেয়ে বেশি কার্যকর।
এক সেকেন্ড অপেক্ষা করুন! আপনি কি সত্যিই কিছু নির্বিচারে উপরের থ্রেশহোল্ডে প্রতিটি আউটলিয়ার মান কমাতে পারেন? একটি মডেল প্রশিক্ষণ যখন, হ্যাঁ.
আপনি স্বাভাবিককরণের অন্যান্য ফর্ম প্রয়োগ করার পরে মানগুলিও ক্লিপ করতে পারেন। উদাহরণস্বরূপ, ধরুন আপনি জেড-স্কোর স্কেলিং ব্যবহার করেন, কিন্তু কিছু আউটলারের পরম মান 3-এর থেকে অনেক বেশি। এই ক্ষেত্রে, আপনি করতে পারেন:
- ঠিক 3 হতে 3-এর বেশি Z-স্কোর ক্লিপ করুন।
- ক্লিপ Z-স্কোর -3 এর চেয়ে কম ঠিক -3 হতে.
ক্লিপিং আপনার মডেলকে গুরুত্বহীন ডেটাতে ওভারইনডেক্সিং থেকে বাধা দেয়। যাইহোক, কিছু outliers আসলে গুরুত্বপূর্ণ, তাই সাবধানে ক্লিপ মান.
স্বাভাবিকীকরণ কৌশলগুলির সংক্ষিপ্তসার
| স্বাভাবিকীকরণ কৌশল | সূত্র | কখন ব্যবহার করতে হবে |
|---|---|---|
| রৈখিক স্কেলিং | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | যখন বৈশিষ্ট্যটি বেশিরভাগ পরিসর জুড়ে অভিন্নভাবে বিতরণ করা হয়। সমতল আকৃতির |
| জেড-স্কোর স্কেলিং | $$ x' = \frac{x - μ}{σ}$$ | যখন বৈশিষ্ট্যটি সাধারণত বিতরণ করা হয় (মানে শীর্ষের কাছাকাছি)। ঘণ্টা আকৃতির |
| লগ স্কেলিং | $$ x' = log(x)$$ | ফিচার ডিস্ট্রিবিউশন যখন লেজের অন্তত দুই পাশে ভারী হয়। ভারী লেজ আকৃতির |
| ক্লিপিং | $x > max$ হলে, $x' = max$ সেট করুন যদি $x < min$ হয়, $x' = min$ সেট করুন | যখন বৈশিষ্ট্যে চরম আউটলায়ার থাকে। |
ব্যায়াম: আপনার জ্ঞান পরীক্ষা

ধরুন আপনি একটি মডেল তৈরি করছেন যা ডেটা সেন্টারের ভিতরে পরিমাপ করা তাপমাত্রার উপর ভিত্তি করে ডেটা সেন্টারের উত্পাদনশীলতার পূর্বাভাস দেয়। নিম্নলিখিত ব্যতিক্রমগুলি সহ আপনার ডেটাসেটের প্রায় সমস্ত temperature মান 15 এবং 30 (সেলসিয়াস) এর মধ্যে পড়ে:
- বছরে একবার বা দুবার, অত্যন্ত গরম দিনে,
temperature31 থেকে 45 এর মধ্যে কয়েকটি মান রেকর্ড করা হয়। -
temperatureপ্রতি 1,000 তম বিন্দু প্রকৃত তাপমাত্রার পরিবর্তে 1,000 এ সেট করা হয়।
কোনটি temperature জন্য একটি যুক্তিসঙ্গত স্বাভাবিকীকরণ কৌশল হবে?
1,000 এর মানগুলি ভুল, এবং ক্লিপ করার পরিবর্তে মুছে ফেলা উচিত৷
31 এবং 45 এর মধ্যে মানগুলি বৈধ ডেটা পয়েন্ট। ক্লিপিং সম্ভবত এই মানগুলির জন্য একটি ভাল ধারণা হতে পারে, ধরে নিচ্ছি যে ভাল ভবিষ্যদ্বাণী করতে মডেলটিকে প্রশিক্ষণ দেওয়ার জন্য ডেটাসেটে এই তাপমাত্রা পরিসরে যথেষ্ট উদাহরণ নেই৷ যাইহোক, অনুমানের সময়, মনে রাখবেন যে ক্লিপ করা মডেলটি 45 তাপমাত্রার জন্য 35 তাপমাত্রার জন্য একই ভবিষ্যদ্বাণী করবে।