Dopo aver esaminato i dati tramite tecniche statistiche e di visualizzazione, devi trasformarli in modo da addestrare il modello in modo più efficace. L'obiettivo della normalizzazione è trasformare le caratteristiche in modo che siano su una scala simile. Ad esempio, considera le seguenti due funzionalità:
- La funzionalità
Xcopre l'intervallo da 154 a 24.917.482. - La funzionalità
Ycopre l'intervallo da 5 a 22.
Queste due funzionalità coprono intervalli molto diversi. La normalizzazione potrebbe manipolare
X e Y in modo che coprano un intervallo simile, ad esempio da 0 a 1.
La normalizzazione offre i seguenti vantaggi:
- Aiuta i modelli a convergere più rapidamente durante l'addestramento. Quando caratteristiche diverse hanno intervalli diversi, la discesa del gradiente può "rimbalzare" e rallentare la convergenza. Detto questo, gli ottimizzatori più avanzati come Adagrad e Adam proteggono da questo problema modificando il tasso di apprendimento effettivo nel tempo.
- Aiuta i modelli a dedurre previsioni migliori. Quando diverse funzionalità hanno intervalli diversi, il modello risultante potrebbe fare previsioni un po' meno utili.
- Consente di evitare la "trappola dei valori NaN" quando i valori delle funzionalità sono molto elevati.
NaN è l'abbreviazione di
not a number. Quando un valore in un modello supera il limite di precisione in virgola mobile, il sistema imposta il valore su
NaNanziché su un numero. Quando un numero nel modello diventa NaN, anche gli altri numeri nel modello alla fine diventano NaN. - Aiuta il modello ad apprendere i pesi appropriati per ogni caratteristica. Senza il ridimensionamento delle funzionalità, il modello presta troppa attenzione alle funzionalità con intervalli ampi e non abbastanza attenzione a quelle con intervalli ristretti.
Ti consigliamo di normalizzare le funzionalità numeriche che coprono intervalli distintamente diversi (ad esempio età e reddito).
Consigliamo inoltre di normalizzare una singola funzionalità numerica che copre un'ampia gamma,
ad esempio city population.
Considera le seguenti due funzionalità:
- Il valore minimo della funzionalità
Aè -0,5 e il valore massimo è +0,5. - Il valore minimo della funzionalità
Bè -5,0 e il valore massimo è +5,0.
Le funzionalità A e B hanno intervalli relativamente ristretti. Tuttavia, l'intervallo della funzionalità B è 10 volte più ampio di quello della funzionalità A. Pertanto:
- All'inizio dell'addestramento, il modello presuppone che la caratteristica
Bsia dieci volte più "importante" della caratteristicaA. - L'addestramento richiederà più tempo del dovuto.
- Il modello risultante potrebbe non essere ottimale.
Il danno complessivo dovuto alla mancata normalizzazione sarà relativamente piccolo, tuttavia consigliamo comunque di normalizzare la funzionalità A e la funzionalità B sulla stessa scala, ad esempio da -1,0 a +1,0.
Ora considera due funzionalità con una maggiore disparità di intervalli:
- Il valore minimo della funzionalità
Cè -1 e il valore massimo è +1. - Il valore minimo della funzionalità
Dè +5000 e il valore massimo è +1.000.000.000.
Se non normalizzi la funzionalità C e la funzionalità D, è probabile che il modello
non sia ottimale. Inoltre, l'addestramento richiederà molto più tempo per
convergere o addirittura non convergerà mai.
Questa sezione tratta tre metodi di normalizzazione comuni:
- scalabilità lineare
- Scalabilità del punteggio z
- scala logaritmica
Questa sezione tratta anche il clipping. Sebbene non sia una vera e propria tecnica di normalizzazione, il troncamento riduce le caratteristiche numeriche indisciplinate in intervalli che producono modelli migliori.
Scala lineare
Scalabilità lineare (più comunemente abbreviata in scalabilità) significa convertire i valori in virgola mobile dal loro intervallo naturale in un intervallo standard, di solito da 0 a 1 o da -1 a +1.
Il ridimensionamento lineare è una buona scelta quando vengono soddisfatte tutte le seguenti condizioni:
- I limiti inferiore e superiore dei dati non cambiano molto nel tempo.
- La funzionalità contiene pochi o nessun valore anomalo e quelli presenti non sono estremi.
- La funzionalità è distribuita in modo approssimativamente uniforme nel suo intervallo. ovvero un istogramma mostrerebbe barre più o meno uniformi per la maggior parte dei valori.
Supponiamo che age umano sia una funzionalità. Il ridimensionamento lineare è una buona tecnica di normalizzazione
per age perché:
- I limiti inferiore e superiore approssimativi sono compresi tra 0 e 100.
agecontiene una percentuale relativamente piccola di valori anomali. Solo lo 0,3% circa della popolazione ha più di 100 anni.- Sebbene alcune età siano rappresentate meglio di altre, un set di dati di grandi dimensioni dovrebbe contenere esempi sufficienti di tutte le età.
Esercizio: verifica la tua comprensione
Supponiamo che il tuo modello abbia una funzionalità denominatanet_worth che contiene il patrimonio netto di persone diverse. La scalabilità lineare è una buona tecnica di normalizzazione
per net_worth? Qual è il motivo?
Scalabilità del punteggio z
Un punteggio Z è il numero di deviazioni standard di un valore dalla media. Ad esempio, un valore che è 2 deviazioni standard superiore alla media ha uno Z-score di +2.0. Un valore che è 1,5 deviazioni standard inferiore alla media ha uno Z-score di -1,5.
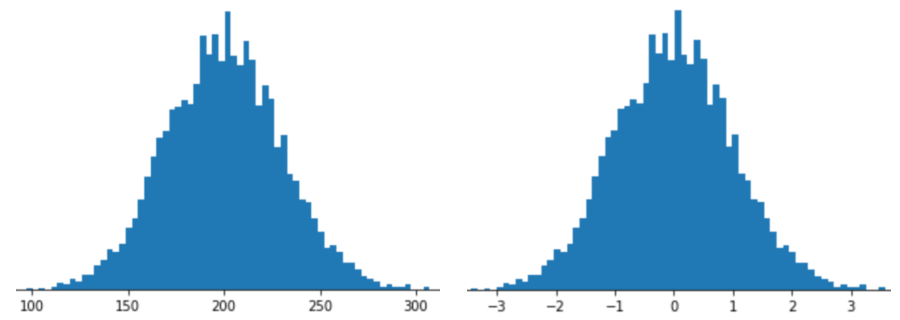
Rappresentare una caratteristica con la scalabilità Z-score significa memorizzare lo Z-score di quella caratteristica nel vettore di caratteristiche. Ad esempio, la figura seguente mostra due istogrammi:
- A sinistra, una distribuzione normale classica.
- A destra, la stessa distribuzione normalizzata mediante la scalabilità del punteggio Z.
La scalabilità Z-score è una buona scelta anche per i dati come quelli mostrati nella figura seguente, che hanno solo una distribuzione vagamente normale.
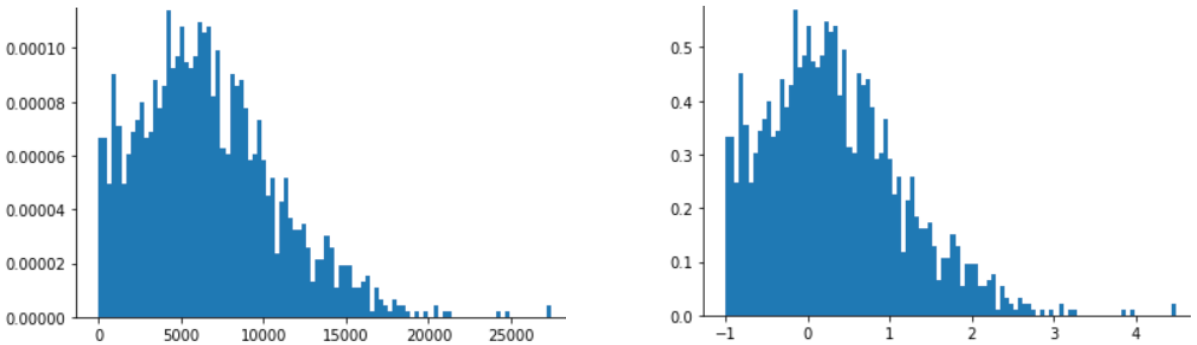
Il punteggio Z è una buona scelta quando i dati seguono una distribuzione normale o una distribuzione simile a una distribuzione normale.
Tieni presente che alcune distribuzioni potrebbero essere normali all'interno della maggior parte del loro intervallo, ma contenere comunque outlier estremi. Ad esempio, quasi tutti i punti di una caratteristica net_worth potrebbero rientrare perfettamente in 3 deviazioni standard, ma alcuni esempi di questa caratteristica potrebbero trovarsi a centinaia di deviazioni standard dalla media. In queste situazioni, puoi combinare la scalatura Z-score con
un'altra forma di normalizzazione (di solito il ritaglio) per gestire la situazione.
Esercizio: verifica la tua comprensione
Supponiamo che il modello venga addestrato su una funzionalità denominataheight che contiene le altezze di dieci milioni di donne adulte. La scalabilità del punteggio Z sarebbe una buona tecnica di normalizzazione per height? Qual è il motivo?
Scala logaritmica
La scalabilità logaritmica calcola il logaritmo del valore non elaborato. In teoria, il logaritmo potrebbe avere qualsiasi base; in pratica, la scalabilità logaritmica di solito calcola il logaritmo naturale (ln).
La scalatura logaritmica è utile quando i dati seguono una distribuzione della legge di potenza. In termini semplici, una distribuzione a legge di potenza ha il seguente aspetto:
- I valori bassi di
Xhanno valori molto alti diY. - All'aumentare dei valori di
X, i valori diYdiminuiscono rapidamente. Di conseguenza, i valori elevati diXhanno valori molto bassi diY.
Le valutazioni dei film sono un buon esempio di distribuzione a legge di potenza. Nella figura seguente, nota:
- Alcuni film hanno molte valutazioni degli utenti. (I valori bassi di
Xhanno valori elevati diY.) - La maggior parte dei film ha pochissime valutazioni degli utenti. (I valori elevati di
Xhanno valori bassi diY.)
La scalabilità logaritmica modifica la distribuzione, il che aiuta ad addestrare un modello che farà previsioni migliori.

Come secondo esempio, le vendite di libri seguono una distribuzione a legge di potenza perché:
- La maggior parte dei libri pubblicati vende un numero esiguo di copie, forse un centinaio o due.
- Alcuni libri vendono un numero moderato di copie, nell'ordine delle migliaia.
- Solo alcuni bestseller venderanno più di un milione di copie.
Supponiamo di addestrare un modello lineare per trovare la relazione tra, ad esempio, le copertine dei libri e le vendite di libri. L'addestramento di un modello lineare sui valori grezzi dovrebbe trovare qualcosa sulle copertine dei libri che vendono un milione di copie che sia 10.000 volte più potente delle copertine dei libri che vendono solo 100 copie. Tuttavia, la scalabilità logaritmica di tutte le cifre di vendita rende l'attività molto più fattibile. Ad esempio, il logaritmo di 100 è:
~4.6 = ln(100)
mentre il log di 1.000.000 è:
~13.8 = ln(1,000,000)
Pertanto, il log di 1.000.000 è solo circa tre volte più grande del log di 100. Probabilmente potresti immaginare che la copertina di un libro best seller sia circa tre volte più potente (in qualche modo) di quella di un libro che vende pochissimo.
Ritaglio
Il clipping è una tecnica per ridurre al minimo l'influenza degli outlier estremi. In breve, il taglio in genere limita (riduce) il valore dei valori anomali a un valore massimo specifico. Il ritaglio è un'idea strana, eppure può essere molto efficace.
Ad esempio, immagina un set di dati contenente una funzionalità denominata roomsPerPerson,
che rappresenta il numero di stanze (stanze totali divise
per numero di occupanti) per varie case. Il seguente grafico mostra che oltre il 99% dei valori delle funzionalità è conforme a una distribuzione normale (approssimativamente, una media di 1,8 e una deviazione standard di 0,7). Tuttavia, la funzionalità contiene
alcuni valori anomali, alcuni dei quali estremi:
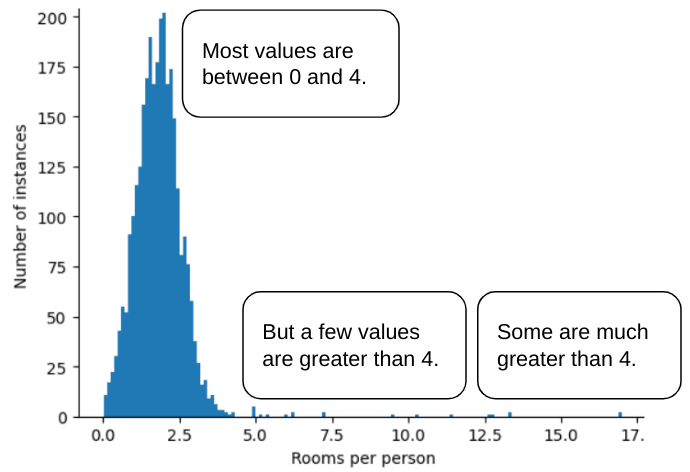
Come puoi ridurre al minimo l'influenza di questi valori anomali estremi? Beh, l'istogramma non è una distribuzione uniforme, una distribuzione normale o una distribuzione a legge di potenza. Cosa succede se limiti o tagli semplicemente il valore massimo di
roomsPerPerson a un valore arbitrario, ad esempio 4,0?
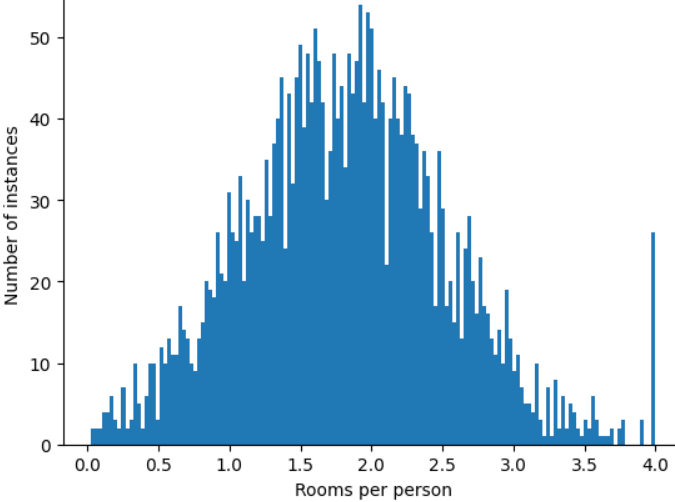
Il troncamento del valore della funzionalità a 4.0 non significa che il modello ignora tutti i valori superiori a 4.0. Significa invece che tutti i valori superiori a 4,0 diventano 4,0. Questo spiega la particolare collina a 4,0. Nonostante questo problema, il set di funzionalità scalato è ora più utile dei dati originali.
Aspetta un secondo! Puoi davvero ridurre ogni valore anomalo a una soglia superiore arbitraria? Sì, durante l'addestramento di un modello.
Puoi anche tagliare i valori dopo aver applicato altre forme di normalizzazione. Ad esempio, supponiamo di utilizzare la scalabilità Z-score, ma alcuni outlier hanno valori assoluti molto superiori a 3. In questo caso, potresti:
- I punteggi Z dei clip superiori a 3 diventano esattamente 3.
- I punteggi Z dei clip inferiori a -3 diventano esattamente -3.
Il troncamento impedisce al modello di eseguire un'indicizzazione eccessiva dei dati non importanti. Tuttavia, alcuni valori anomali sono in realtà importanti, quindi taglia i valori con attenzione.
Riepilogo delle tecniche di normalizzazione
| Tecnica di normalizzazione | Formula | Quando utilizzarle |
|---|---|---|
| Scala lineare | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | Quando la funzionalità è distribuita in modo uniforme nell'intervallo. A forma piatta |
| Scalabilità del punteggio z | $$ x' = \frac{x - μ}{σ}$$ | Quando la funzionalità è distribuita normalmente (picco vicino alla media). A forma di campana |
| Scala logaritmica | $$ x' = log(x)$$ | Quando la distribuzione delle funzionalità è fortemente asimmetrica su almeno un lato della coda. Pesante a forma di coda |
| Ritaglio | Se $x > max$, imposta $x' = max$ Se $x < min$, imposta $x' = min$ |
Quando la funzionalità contiene valori anomali estremi. |
Esercizio: verifica le tue conoscenze

Supponiamo che tu stia sviluppando un modello che preveda la produttività di un data center in base alla temperatura misurata al suo interno.
Quasi tutti i valori di temperature nel set di dati rientrano
tra 15 e 30 (Celsius), con le seguenti eccezioni:
- Una o due volte l'anno, nei giorni estremamente caldi, vengono registrati alcuni valori compresi tra 31 e 45 in
temperature. - Ogni 1000° punto in
temperatureè impostato su 1000 anziché sulla temperatura effettiva.
Quale sarebbe una tecnica di normalizzazione ragionevole per
temperature?
I valori di 1000 sono errori e devono essere eliminati anziché troncati.
I valori compresi tra 31 e 45 sono punti dati legittimi. Il troncamento sarebbe probabilmente una buona idea per questi valori, supponendo che il set di dati non contenga esempi sufficienti in questo intervallo di temperatura per addestrare il modello a fare buone previsioni. Tuttavia, durante l'inferenza, tieni presente che il modello troncato farà quindi la stessa previsione per una temperatura di 45 come per una temperatura di 35.