Po zbadaniu danych za pomocą technik statystycznych i wizualizacyjnych należy je przekształcić w taki sposób, aby model mógł się skuteczniej trenować. Celem normalizacji jest przekształcenie cech tak, aby miały podobną skalę. Rozważmy na przykład te 2 funkcje:
- Funkcja
Xobejmuje zakres od 154 do 24 917 482. - Funkcja
Yobejmuje zakres od 5 do 22.
Te 2 funkcje obejmują bardzo różne zakresy. Normalizacja może przekształcić wartości X i Y tak, aby mieściły się w podobnym zakresie, np. od 0 do 1.
Normalizacja zapewnia te korzyści:
- Pomaga modelom szybciej się dostosowywać podczas trenowania. Gdy różne cechy mają różne zakresy, metoda gradientu prostego może „odbijać się” i powodować powolną zbieżność. Bardziej zaawansowane optymalizatory, takie jak Adagrad i Adam, chronią przed tym problemem, zmieniając efektywny współczynnik uczenia się w czasie.
- Pomaga modelom wyciągać trafniejsze wnioski. Jeśli różne cechy mają różne zakresy, model może generować nieco mniej przydatne prognozy.
- Pomaga unikać „pułapki NaN”, gdy wartości cech są bardzo wysokie.
NaN to skrót od not a number (nie jest liczbą). Gdy wartość w modelu przekracza limit precyzji zmiennoprzecinkowej, system ustawia wartość na
NaNzamiast na liczbę. Gdy jedna liczba w modelu staje się wartością NaN, inne liczby w modelu również ostatecznie stają się wartościami NaN. - Pomaga modelowi nauczyć się odpowiednich wag dla każdej cechy. Bez skalowania cech model zwraca zbyt dużą uwagę na cechy o szerokim zakresie, a zbyt małą na cechy o wąskim zakresie.
Zalecamy normalizowanie cech numerycznych obejmujących wyraźnie różne zakresy (np. wiek i dochód).
Zalecamy też normalizację pojedynczej funkcji numerycznej, która obejmuje szeroki zakres, np. city population..
Rozważ te 2 funkcje:
- Najniższa wartość cechy
Ato -0,5, a najwyższa to +0,5. - Najniższa wartość cechy
Bto -5.0, a najwyższa to +5.0.
Funkcje A i B mają stosunkowo wąskie zakresy. Jednak zakres funkcji B jest 10 razy szerszy niż zakres funkcji A. Dlatego:
- Na początku trenowania model zakłada, że cecha
Bjest 10 razy „ważniejsza” niż cechaA. - Trenowanie będzie trwało dłużej niż powinno.
- Wynikowy model może być nieoptymalny.
Ogólne szkody wynikające z braku normalizacji będą stosunkowo niewielkie, ale nadal zalecamy normalizację cechy A i cechy B do tej samej skali, np. od –1,0 do +1,0.
Rozważmy teraz 2 funkcje o większej różnicy zakresów:
- Najniższa wartość cechy
Cto -1, a najwyższa to +1. - Najniższa wartość cechy
Dto +5000, a najwyższa to +1 000 000 000.
Jeśli nie znormalizujesz cechy C i cechy D, model prawdopodobnie nie będzie optymalny. Co więcej, trenowanie będzie trwało znacznie dłużej, zanim model osiągnie zbieżność, a może nawet nigdy jej nie osiągnąć.
W tej sekcji znajdziesz omówienie 3 popularnych metod normalizacji:
- skalowanie liniowe,
- Skalowanie standaryzacji Z
- skalowanie logarytmiczne,
Ta sekcja zawiera też informacje o przycinaniu. Chociaż obcinanie nie jest prawdziwą techniką normalizacji, pozwala ono ograniczyć nieuporządkowane cechy liczbowe do zakresów, które umożliwiają tworzenie lepszych modeli.
Skala liniowa
Skalowanie liniowe (częściej skracane do skalowania) oznacza przekształcanie wartości zmiennoprzecinkowych z ich naturalnego zakresu na zakres standardowy – zwykle od 0 do 1 lub od -1 do +1.
Skalowanie liniowe jest dobrym wyborem, gdy spełnione są wszystkie te warunki:
- Dolna i górna granica danych nie zmieniają się z czasem.
- Ta cecha zawiera niewiele wartości odstających lub nie zawiera ich wcale, a wartości odstające nie są ekstremalne.
- Wartości cechy są w przybliżeniu rozłożone równomiernie w jej zakresie. Oznacza to, że histogram będzie miał mniej więcej równe słupki dla większości wartości.
Załóżmy, że cechą jest age. Skalowanie liniowe to dobra technika normalizacji w przypadku age, ponieważ:
- Przybliżone dolne i górne granice to 0–100.
agezawiera stosunkowo niewielki odsetek wartości odstających. Tylko około 0,3% populacji ma ponad 100 lat.- Chociaż niektóre grupy wiekowe są reprezentowane nieco lepiej niż inne, duży zbiór danych powinien zawierać wystarczającą liczbę przykładów dla wszystkich grup wiekowych.
Ćwiczenie: sprawdź swoją wiedzę
Załóżmy, że model ma funkcję o nazwienet_worth, która zawiera wartość netto różnych osób. Czy skalowanie liniowe byłoby dobrą techniką normalizacji w przypadku net_worth? Dlaczego?
Skalowanie standaryzacji Z
Wartość Z to liczba odchyleń standardowych, o którą wartość odbiega od średniej. Na przykład wartość, która jest o 2 odchylenia standardowe większa od średniej, ma wynik z (Z-score) równy +2,0. Wartość, która jest o 1,5 odchylenia standardowego mniejsza od średniej, ma wynik z (Z-score) równy –1,5.
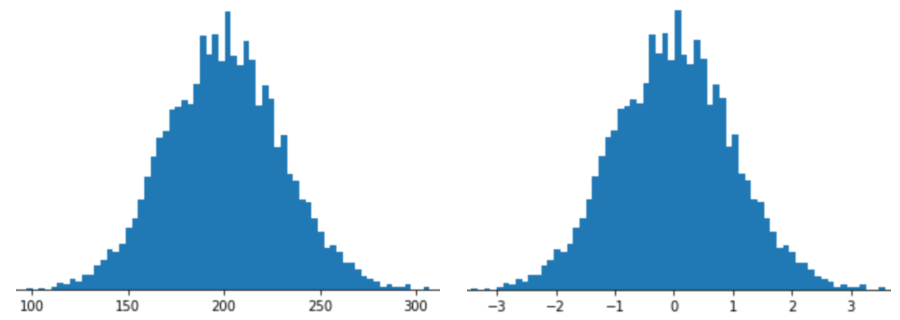
Reprezentowanie cechy za pomocą skalowania Z-score oznacza przechowywanie w wektorze cech wartości Z-score tej cechy. Na przykład na tym rysunku widać 2 histogramy:
- Po lewej stronie klasyczny rozkład normalny.
- Po prawej stronie ten sam rozkład znormalizowany przez skalowanie za pomocą wyniku z.
Skalowanie za pomocą wyniku z jest też dobrym wyborem w przypadku danych takich jak te na poniższym rysunku, które mają tylko niejasny rozkład normalny.
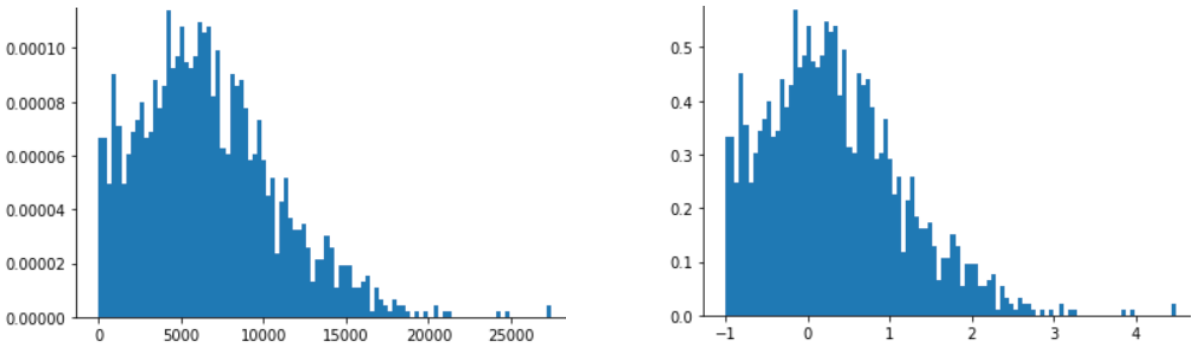
Wartość z jest dobrym wyborem, gdy dane mają rozkład normalny lub rozkład do niego podobny.
Pamiętaj, że niektóre rozkłady mogą być normalne w większości zakresu, ale nadal zawierać skrajne wartości odstające. Na przykład prawie wszystkie punkty w przypadku cechy net_worth mogą mieścić się w zakresie 3 odchyleń standardowych, ale kilka przykładów tej cechy może znajdować się setki odchyleń standardowych od średniej. W takich sytuacjach możesz połączyć skalowanie za pomocą wyniku z inną formą normalizacji (zwykle przycinaniem), aby rozwiązać ten problem.
Ćwiczenie: sprawdź swoją wiedzę
Załóżmy, że model trenuje na podstawie cechy o nazwieheight, która zawiera wzrost 10 milionów dorosłych kobiet. Czy skalowanie za pomocą standaryzacji Z byłoby dobrą techniką normalizacji w przypadku height? Dlaczego?
Skalowanie logarytmiczne
Skalowanie logarytmiczne oblicza logarytm wartości pierwotnej. Teoretycznie logarytm może mieć dowolną podstawę, ale w praktyce skalowanie logarytmiczne zwykle oblicza logarytm naturalny (ln).
Skalowanie logarytmiczne jest przydatne, gdy dane mają rozkład zgodny z prawem potęgowym. Mówiąc wprost, rozkład potęgowy wygląda tak:
- Niskie wartości
Xmają bardzo wysokie wartościY. - Wraz ze wzrostem wartości
XwartościYszybko maleją. W konsekwencji wysokie wartościXmają bardzo niskie wartościY.
Oceny filmów są dobrym przykładem rozkładu potęgowego. Na poniższym rysunku zwróć uwagę na te elementy:
- Kilka filmów ma wiele ocen użytkowników. (Niskie wartości
Xmają wysokie wartościY). - Większość filmów ma bardzo mało ocen użytkowników. (Wysokie wartości
Xmają niskie wartościY).
Skalowanie logarytmiczne zmienia rozkład, co pomaga trenować model, który będzie generować lepsze prognozy.

Inny przykład: sprzedaż książek jest zgodna z rozkładem potęgowym, ponieważ:
- Większość opublikowanych książek sprzedaje się w niewielkiej liczbie egzemplarzy, może w stu lub dwustu.
- Niektóre książki sprzedają się w umiarkowanej liczbie egzemplarzy, czyli w tysiącach.
- Tylko kilka bestsellerów sprzeda się w nakładzie ponad miliona egzemplarzy.
Załóżmy, że trenujesz model liniowy, aby znaleźć związek między okładkami książek a ich sprzedażą. Model liniowy trenowany na surowych wartościach musiałby znaleźć coś na okładkach książek, które sprzedają się w milionach egzemplarzy, co jest 10 000 razy bardziej skuteczne niż okładki książek, które sprzedają się tylko w 100 egzemplarzach. Skalowanie logarytmiczne wszystkich danych o sprzedaży znacznie ułatwia to zadanie. Na przykład logarytm liczby 100 to:
~4.6 = ln(100)
logarytm z 1 000 000 to:
~13.8 = ln(1,000,000)
Dlatego logarytm z 1 000 000 jest tylko około 3 razy większy niż logarytm ze 100. Prawdopodobnie możesz sobie wyobrazić, że okładka bestsellera jest około 3 razy bardziej atrakcyjna (w jakiś sposób) niż okładka książki, która sprzedaje się w niewielkich ilościach.
Obcinanie
Przycinanie to technika, która pozwala zminimalizować wpływ skrajnych wartości odstających. W skrócie, przycinanie zwykle ogranicza (zmniejsza) wartość elementów odstających do określonej wartości maksymalnej. Przycinanie to dziwny pomysł, ale może być bardzo skuteczny.
Wyobraź sobie na przykład zbiór danych zawierający cechę o nazwie roomsPerPerson, która reprezentuje liczbę pokoi (łączna liczba pokoi podzielona przez liczbę mieszkańców) w różnych domach. Poniższy wykres pokazuje, że ponad 99% wartości cech ma rozkład normalny (średnia ok. 1,8, a odchylenie standardowe 0,7). Ta funkcja zawiera jednak kilka wartości odstających, w tym niektóre skrajne:
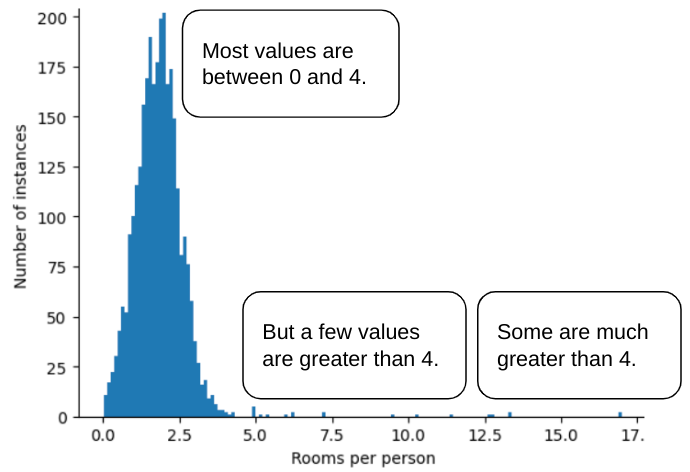
Jak możesz zminimalizować wpływ tych skrajnych wartości odstających? Histogram nie jest rozkładem równomiernym, normalnym ani rozkładem potęgowym. Co się stanie, jeśli po prostu ograniczysz lub przytniesz maksymalną wartość roomsPerPerson do dowolnej wartości, np.4,0?
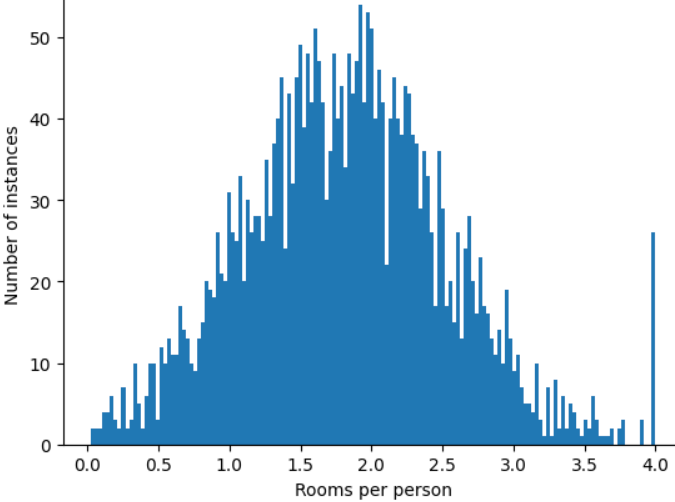
Ograniczenie wartości cechy do 4,0 nie oznacza, że model ignoruje wszystkie wartości większe niż 4,0. Oznacza to, że wszystkie wartości większe niż 4,0 zostaną teraz zastąpione wartością 4,0. Wyjaśnia to nietypowe wzniesienie na poziomie 4,0. Pomimo tego problemu przeskalowany zestaw cech jest teraz bardziej przydatny niż oryginalne dane.
Chwileczkę! Czy można naprawdę zredukować każdą wartość odstającą do jakiegoś arbitralnego górnego progu? Tak, podczas trenowania modelu.
Możesz też przycinać wartości po zastosowaniu innych form normalizacji. Załóżmy na przykład, że używasz skalowania z-score, ale kilka wartości odstających ma wartości bezwzględne znacznie większe niż 3. W takim przypadku możesz:
- Ogranicz wyniki z-score powyżej 3 do wartości 3.
- Wartości z klipu mniejsze niż -3 zostaną zmienione na -3.
Obcinanie zapobiega nadmiernemu indeksowaniu przez model nieistotnych danych. Niektóre wartości odstające są jednak ważne, więc ostrożnie przycinaj wartości.
Podsumowanie technik normalizacji
| Technika normalizacji | Formuła | Kiedy używać |
|---|---|---|
| Skala liniowa | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | Gdy funkcja jest w większości równomiernie rozłożona w zakresie. Płaskie |
| Skalowanie standaryzacji Z | $$ x' = \frac{x - μ}{σ}$$ | Gdy cecha ma rozkład normalny (wartość szczytowa jest zbliżona do średniej). w kształcie dzwonu |
| Skalowanie logarytmiczne | $$ x' = log(x)$$ | Gdy rozkład cech jest silnie skośny po co najmniej jednej stronie ogona. Duży w kształcie ogona |
| Obcinanie | Jeśli $x > max$, ustaw $x' = max$ Jeśli $x < min$, ustaw $x' = min$ |
gdy funkcja zawiera wartości odstające, |
Ćwiczenie: sprawdź swoją wiedzę
Załóżmy, że tworzysz model, który na podstawie temperatury w centrum danych prognozuje jego wydajność.
Prawie wszystkie wartości temperature w zbiorze danych mieszczą się w zakresie od 15 do 30 stopni Celsjusza, z wyjątkiem tych wartości:
- Raz lub dwa razy w roku, w bardzo gorące dni, w
temperatureodnotowuje się kilka wartości z przedziału od 31 do 45. - Każdy tysięczny punkt w
temperaturejest ustawiony na 1000, a nie na rzeczywistą temperaturę.
Która z poniższych metod normalizacji byłaby odpowiednia w przypadku wartości temperature?
Wartości 1000 są błędne i należy je usunąć, a nie przyciąć.
Wartości od 31 do 45 są prawidłowymi punktami danych. W przypadku tych wartości warto zastosować przycinanie, zakładając, że zbiór danych nie zawiera wystarczającej liczby przykładów w tym zakresie temperatur, aby wytrenować model do tworzenia dobrych prognoz. Podczas wnioskowania model po przycięciu będzie jednak dokonywać tego samego przewidywania dla temperatury 45 stopni co dla temperatury 35 stopni.