आंकड़ों और विज़ुअलाइज़ेशन की तकनीकों की मदद से अपने डेटा की जांच करने के बाद, आपको अपने डेटा को ऐसे तरीके से बदलना चाहिए जिससे आपके मॉडल को ज़्यादा बेहतर तरीके से ट्रेन करने में मदद मिले. नॉर्मलाइज़ेशन का मकसद, फ़ीचर को एक ही स्केल पर बदलना है. उदाहरण के लिए, इन दो सुविधाओं पर ध्यान दें:
- सुविधा
Xकी रेंज 154 से 24,917,482 तक है. - सुविधा
Yकी रेंज 5 से 22 तक है.
ये दोनों सुविधाएं अलग-अलग रेंज में होती हैं. सामान्य बनाने की प्रोसेस में, X और Y में बदलाव किया जा सकता है, ताकि वे एक जैसी रेंज में हों. जैसे, 0 से 1.
डेटा को सामान्य बनाने से ये फ़ायदे मिलते हैं:
- इससे मॉडल को ट्रेनिंग के दौरान ज़्यादा तेज़ी से कॉन्वर्ज करने में मदद मिलती है. जब अलग-अलग सुविधाओं की रेंज अलग-अलग होती है, तो ग्रेडिएंट डिसेंट "बाउंस" कर सकता है और कन्वर्ज़न धीमा हो सकता है. हालांकि, Adagrad और Adam जैसे बेहतर ऑप्टिमाइज़र, समय के साथ बेहतर लर्निंग रेट में बदलाव करके, इस समस्या से बचाते हैं.
- इससे मॉडल को बेहतर अनुमान लगाने में मदद मिलती है. जब अलग-अलग सुविधाओं की रेंज अलग-अलग होती है, तो इससे तैयार होने वाला मॉडल कुछ कम काम का अनुमान दे सकता है.
- फ़ीचर वैल्यू बहुत ज़्यादा होने पर, "NaN ट्रैप" से बचने में मदद करता है.
NaN, संख्या नहीं है के लिए छोटा नाम है. जब किसी मॉडल में मौजूद वैल्यू, फ़्लोटिंग-पॉइंट की सटीक वैल्यू की सीमा से ज़्यादा हो जाती है, तो सिस्टम वैल्यू को किसी संख्या के बजाय
NaNपर सेट कर देता है. जब मॉडल में मौजूद कोई संख्या NaN हो जाती है, तो मॉडल में मौजूद अन्य संख्याएं भी आखिर में NaN हो जाती हैं. - इससे मॉडल को हर सुविधा के लिए सही वेट सीखने में मदद मिलती है. फ़ीचर स्केलिंग के बिना, मॉडल का ध्यान ज़्यादा रेंज वाली फ़ीचर पर ज़्यादा जाता है और कम रेंज वाली फ़ीचर पर कम.
हमारा सुझाव है कि अलग-अलग रेंज (उदाहरण के लिए, उम्र और आय) को कवर करने वाली संख्या वाली सुविधाओं को सामान्य बनाएं.
हमारा सुझाव है कि आप ऐसी संख्या वाली किसी एक सुविधा को सामान्य बनाएं जो कई तरह की वैल्यू को कवर करती हो, जैसे कि city population.
इन दो सुविधाओं पर ध्यान दें:
- सुविधा
Aकी सबसे कम वैल्यू -0.5 और सबसे ज़्यादा वैल्यू +0.5 है. - सुविधा
Bकी सबसे कम वैल्यू -5.0 और सबसे ज़्यादा वैल्यू +5.0 है.
सुविधा A और सुविधा B के स्पैन काफ़ी कम हैं. हालांकि, सुविधा B का स्पैन, सुविधा A के स्पैन से 10 गुना ज़्यादा है. इसलिए:
- ट्रेनिंग की शुरुआत में, मॉडल यह मानता है कि फ़ीचर
B, फ़ीचरAसे दस गुना ज़्यादा "ज़रूरी" है. - ट्रेनिंग में ज़रूरत से ज़्यादा समय लगेगा.
- इससे मिलने वाला मॉडल, शायद सही न हो.
सामान्य न करने की वजह से होने वाला कुल नुकसान अपेक्षाकृत कम होगा. हालांकि, हम अब भी सुझाव देते हैं कि आप सुविधा A और सुविधा B को एक ही स्केल पर सामान्य करें. जैसे, -1.0 से +1.0.
अब दो ऐसी सुविधाओं पर विचार करें जिनकी रेंज में काफ़ी अंतर है:
- फ़ीचर
Cकी सबसे कम वैल्यू -1 और सबसे ज़्यादा वैल्यू +1 है. - फ़ीचर
Dकी सबसे कम वैल्यू +5,000 और सबसे ज़्यादा वैल्यू +1,000,000,000 है.
अगर आपने सुविधा C और सुविधा D को सामान्य नहीं किया है, तो हो सकता है कि आपका मॉडल सही तरीके से काम न करे. इसके अलावा, ट्रेनिंग को एक साथ काम करने में काफ़ी समय लगेगा या हो सकता है कि वह पूरी तरह से काम न करे!
इस सेक्शन में, सामान्य बनाने के तीन लोकप्रिय तरीके बताए गए हैं:
- लीनियर स्केलिंग
- Z-स्कोर स्केलिंग
- लॉग स्केलिंग
इस सेक्शन में, क्लिप करने के बारे में भी बताया गया है. क्लिपिंग, नॉर्मलाइज़ेशन की सही तकनीक नहीं है. हालांकि, यह ग़ैर-ज़रूरी संख्याओं को ऐसी सीमाओं में बदल देती है जिनसे बेहतर मॉडल बनते हैं.
रेखीय स्केलिंग
लीनियर स्केलिंग (आम तौर पर इसे सिर्फ़ स्केलिंग कहा जाता है) का मतलब है, फ़्लोटिंग-पॉइंट वैल्यू को उनकी सामान्य रेंज से स्टैंडर्ड रेंज में बदलना. आम तौर पर, यह रेंज 0 से 1 या -1 से +1 होती है.
लीनियर स्केलिंग का विकल्प तब सही होता है, जब ये सभी शर्तें पूरी होती हैं:
- आपके डेटा की निचली और ऊपरी सीमा, समय के साथ ज़्यादा नहीं बदलती.
- इस सुविधा में आउटलायर कम हैं या कोई आउटलायर नहीं है. साथ ही, ये आउटलायर बहुत ज़्यादा नहीं हैं.
- यह सुविधा, अपनी रेंज में लगभग समान रूप से डिस्ट्रिब्यूट होती है. इसका मतलब है कि हिस्टोग्राम में ज़्यादातर वैल्यू के लिए, लगभग बराबर बार दिखेंगे.
मान लें कि मानव age एक सुविधा है. लीनियर स्केलिंग, age के लिए सामान्य करने की एक अच्छी तकनीक है, क्योंकि:
- अनुमानित निचली और ऊपरी सीमा 0 से 100 है.
ageमें आउटलायर का प्रतिशत कम है. यहां की सिर्फ़ 0.3% आबादी की उम्र 100 साल से ज़्यादा है.- हालांकि, कुछ उम्र के लोगों के डेटा की तुलना में अन्य उम्र के लोगों के डेटा की संख्या ज़्यादा हो सकती है. हालांकि, बड़े डेटासेट में सभी उम्र के लोगों के डेटा के ज़रूरत के मुताबिक उदाहरण होने चाहिए.
एक्सरसाइज़: देखें कि आपको क्या समझ आया
मान लें कि आपके मॉडल मेंnet_worth नाम की एक सुविधा है, जिसमें अलग-अलग लोगों की कुल संपत्ति से जुड़ी जानकारी होती है. क्या net_worth के लिए, लीनियर स्केलिंग एक अच्छी नॉर्मलाइज़ेशन टेक्नोलॉजी होगी? ऐसा क्यों है या क्यों नहीं है?
Z-स्कोर स्केलिंग
Z-स्कोर, मीन से स्टैंडर्ड डिवीऐशन (मानक विचलन) की संख्या होती है. उदाहरण के लिए, अगर कोई वैल्यू, औसत से दो स्टैंडर्ड डिविएशन ज़्यादा है, तो उसका Z-स्कोर +2.0 होगा. अगर कोई वैल्यू, माध्य से 1.5 स्टैंडर्ड डिविएशन कम है, तो उसका Z-स्कोर -1.5 होगा.
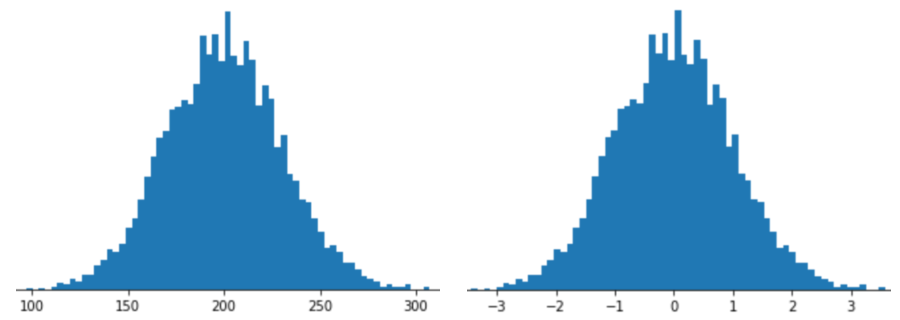
किसी फ़ीचर को Z-स्कोर स्केलिंग के साथ दिखाने का मतलब है कि फ़ीचर वेक्टर में उस फ़ीचर का Z-स्कोर सेव करना. उदाहरण के लिए, नीचे दिए गए चित्र में दो हिस्टोग्राम दिखाए गए हैं:
- बाईं ओर, क्लासिक नॉर्मल डिस्ट्रिब्यूशन.
- दाईं ओर, Z-स्कोर स्केलिंग के हिसाब से नॉर्मलाइज़ किया गया वही डिस्ट्रिब्यूशन.
नीचे दिए गए आंकड़े में दिखाए गए डेटा के लिए भी, Z-स्कोर स्केलिंग एक अच्छा विकल्प है. इस डेटा में, सामान्य डिस्ट्रिब्यूशन काफ़ी हद तक है.
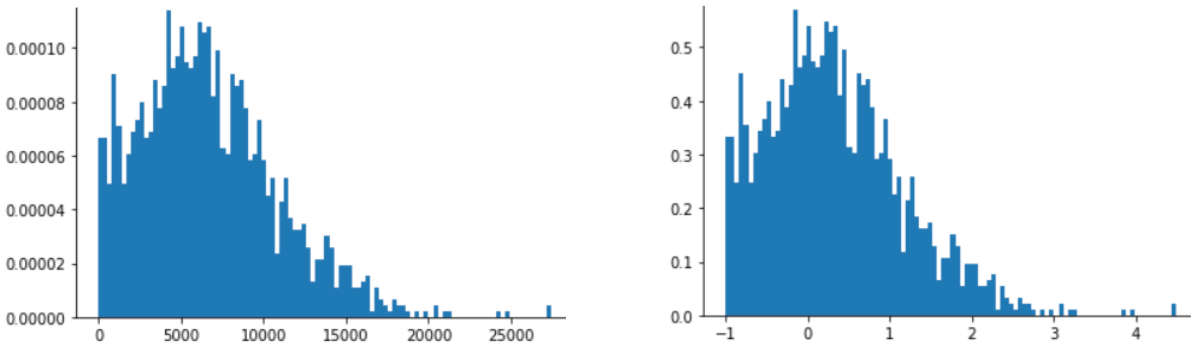
जब डेटा सामान्य डिस्ट्रिब्यूशन या सामान्य डिस्ट्रिब्यूशन से मिलता-जुलता डिस्ट्रिब्यूशन फ़ॉलो करता है, तब Z-स्कोर एक अच्छा विकल्प होता है.
ध्यान दें कि कुछ डिस्ट्रिब्यूशन अपनी रेंज के ज़्यादातर हिस्से में सामान्य हो सकते हैं. हालांकि, इनमें अब भी बहुत ज़्यादा आउटलायर हो सकते हैं. उदाहरण के लिए, हो सकता है कि net_worth सुविधा के ज़्यादातर पॉइंट, तीन स्टैंडर्ड डिविएशन में आसानी से फ़िट हो जाएं, लेकिन इस सुविधा के कुछ उदाहरण, माध्य से सैकड़ों स्टैंडर्ड डिविएशन दूर हो सकते हैं. इन स्थितियों में, इस स्थिति को मैनेज करने के लिए, Z-स्कोर स्केलिंग को सामान्य बनाने के किसी अन्य तरीके (आम तौर पर क्लिपिंग) के साथ जोड़ा जा सकता है.
एक्सरसाइज़: देखें कि आपको क्या समझ आया
मान लें कि आपका मॉडलheight नाम की किसी सुविधा पर ट्रेनिंग लेता है. इसमें, वयस्क महिलाओं की ऊंचाई का डेटा होता है. क्या height के लिए, Z-स्कोर स्केलिंग एक अच्छी नॉर्मलाइज़ेशन टेक्नोलॉजी होगी? ऐसा क्यों है या क्यों नहीं है?
लॉग स्केलिंग
लॉग स्केलिंग, रॉ वैल्यू के लॉगारिद्म का हिसाब लगाती है. सिद्धांत रूप से, लॉगारिद्म का आधार कोई भी हो सकता है. हालांकि, आम तौर पर लॉग स्केलिंग में नेचुरल लॉगारिद्म (ln) का हिसाब लगाया जाता है.
लॉग स्केलिंग तब मददगार होती है, जब डेटा पावर लॉ डिस्ट्रिब्यूशन के मुताबिक हो. आम तौर पर, पावर लॉ डिस्ट्रिब्यूशन इस तरह दिखता है:
Xकी कम वैल्यू के लिए,Yकी वैल्यू बहुत ज़्यादा होती है.Xकी वैल्यू बढ़ने पर,Yकी वैल्यू तेज़ी से कम हो जाती है. इसलिए,Xकी ज़्यादा वैल्यू के लिएYकी वैल्यू बहुत कम होती है.
फ़िल्मों की रेटिंग, पावर लॉ डिस्ट्रिब्यूशन का एक अच्छा उदाहरण है. नीचे दिए गए आंकड़े में, ध्यान दें:
- कुछ फ़िल्मों को उपयोगकर्ताओं ने बहुत ज़्यादा रेटिंग दी है. (
Xकी कम वैल्यू के लिए,Yकी वैल्यू ज़्यादा होती है.) - ज़्यादातर फ़िल्मों को उपयोगकर्ताओं की बहुत कम रेटिंग मिलती हैं. (
Xकी ज़्यादा वैल्यू के लिए,Yकी वैल्यू कम होती है.)
लॉग स्केलिंग से डिस्ट्रिब्यूशन में बदलाव होता है. इससे, बेहतर अनुमान लगाने वाले मॉडल को ट्रेन करने में मदद मिलती है.

दूसरे उदाहरण के तौर पर, किताबों की बिक्री, पावर लॉ डिस्ट्रिब्यूशन के मुताबिक होती है, क्योंकि:
- पब्लिश की गई ज़्यादातर किताबों की कुछ ही कॉपी बिकती हैं. शायद एक या दो सौ.
- कुछ किताबों की हज़ारों कॉपी बिकती हैं.
- सिर्फ़ कुछ बेस्टसेलर की एक करोड़ से ज़्यादा कॉपी बिकती हैं.
मान लें कि आपको किताब के कवर और उसकी बिक्री के बीच के संबंध का पता लगाने के लिए, किसी लीनियर मॉडल को ट्रेनिंग देनी है. रॉ वैल्यू पर लीनियर मॉडल ट्रेनिंग के लिए, उन किताबों के कवर के बारे में कुछ पता करना होगा जिनकी एक करोड़ कॉपी बिकती हैं. यह जानकारी, सिर्फ़ 100 कॉपी बिकने वाली किताबों के कवर की जानकारी से 10,000 गुना ज़्यादा अहम होती है. हालांकि, बिक्री के सभी आंकड़ों को लॉग स्केलिंग करने से, यह काम ज़्यादा आसान हो जाता है. उदाहरण के लिए, 100 का लॉग:
~4.6 = ln(100)
जबकि 1,000,000 का लॉग:
~13.8 = ln(1,000,000)
इसलिए, 1,000,000 का लॉग, 100 के लॉग से सिर्फ़ तीन गुना ज़्यादा है. आपको शायद यह पता हो कि बेस्टसेलर किताब का कवर, कम बिकने वाली किताब के कवर के मुकाबले, किसी तरह से तीन गुना ज़्यादा असरदार होता है.
क्लिप करना
क्लिपिंग एक ऐसी तकनीक है जिससे, बहुत ज़्यादा आउटलायर के असर को कम किया जा सकता है. कम शब्दों में, क्लिपिंग की सुविधा आम तौर पर आउटलायर की वैल्यू को किसी तय सीमा तक कम कर देती है. क्लिपिंग एक ऐसा तरीका है जो थोड़ा अजीब है. इसके बावजूद, यह बहुत असरदार हो सकता है.
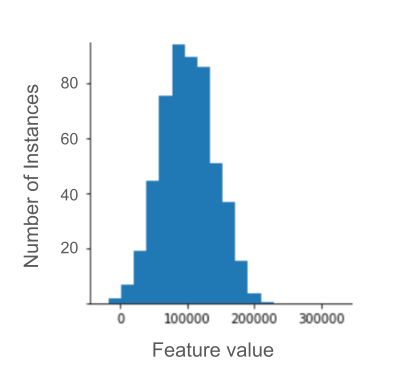
उदाहरण के लिए, roomsPerPerson नाम की सुविधा वाले डेटासेट की कल्पना करें, जो अलग-अलग घरों के लिए कमरों की संख्या दिखाता है. यह संख्या, कुल कमरों की संख्या को रहने वालों की संख्या से भाग देने पर मिलती है. यहां दिए गए प्लॉट से पता चलता है कि 99% से ज़्यादा सुविधा वैल्यू, सामान्य डिस्ट्रिब्यूशन के मुताबिक हैं. इनकी औसत वैल्यू 1.8 और स्टैंडर्ड डेविएशन 0.7 है. हालांकि, इस सुविधा में कुछ आउटलायर भी शामिल हैं. इनमें से कुछ आउटलायर काफ़ी ज़्यादा हैं:
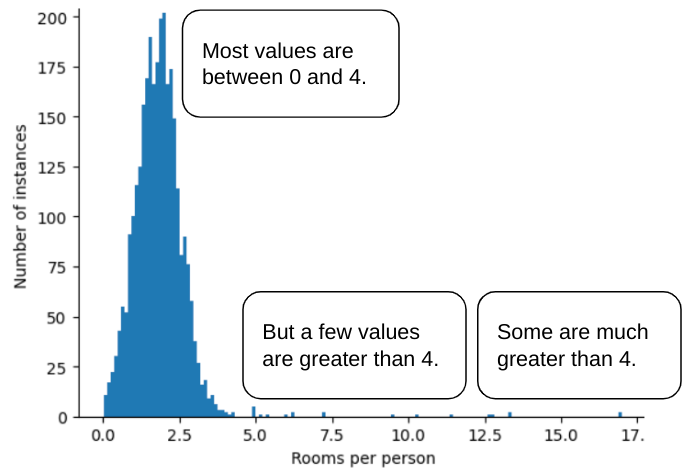
ऐसे आउटलायर के असर को कैसे कम किया जा सकता है? वैसे, हिस्टोग्राम में डेटा का बंटवारा, बराबर नहीं होता. यह नॉर्मल डिस्ट्रिब्यूशन या पावर लॉ डिस्ट्रिब्यूशन भी नहीं होता. अगर आपने roomsPerPerson की ज़्यादा से ज़्यादा वैल्यू को 4.0 जैसी किसी वैल्यू पर कप या क्लिप किया, तो क्या होगा?
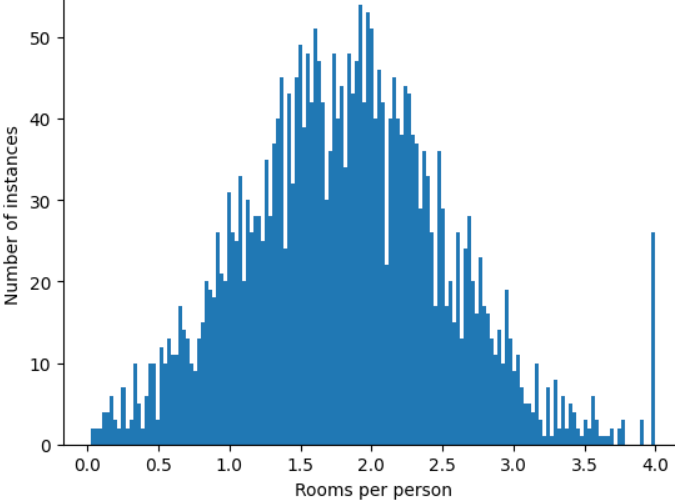
सुविधा की वैल्यू को 4.0 पर क्लिप करने का मतलब यह नहीं है कि आपका मॉडल 4.0 से ज़्यादा की सभी वैल्यू को अनदेखा कर देता है. इसका मतलब है कि 4.0 से ज़्यादा की सभी वैल्यू अब 4.0 हो गई हैं. इससे 4.0 पर मौजूद खास पहाड़ी के बारे में पता चलता है. इस बाधा के बावजूद, स्केल किया गया सुविधा सेट अब ओरिजनल डेटा से ज़्यादा काम का है.
एक सेकंड रुकिए! क्या हर आउटलायर वैल्यू को किसी मनमुताबिक ऊपरी थ्रेशोल्ड तक कम किया जा सकता है? मॉडल को ट्रेनिंग देते समय, हां.
सामान्य बनाने के अन्य तरीकों को लागू करने के बाद भी, वैल्यू को क्लिप किया जा सकता है. उदाहरण के लिए, मान लें कि आपने Z-स्कोर स्केलिंग का इस्तेमाल किया है, लेकिन कुछ आउटलायर की वैल्यू 3 से काफ़ी ज़्यादा है. इस मामले में, ये काम किए जा सकते हैं:
- तीन से ज़्यादा के Z-स्कोर को तीन पर सेट करें.
- -3 से कम Z-स्कोर को -3 पर क्लिप करें.
क्लिपिंग की मदद से, आपके मॉडल को ज़रूरी न होने वाले डेटा को ओवरइंडेक्स करने से रोका जा सकता है. हालांकि, कुछ आउटलायर असल में ज़रूरी होते हैं. इसलिए, वैल्यू को ध्यान से क्लिप करें.
सामान्य बनाने की तकनीकों के बारे में खास जानकारी
| नॉर्मलाइज़ेशन की तकनीक | फ़ॉर्मूला | कब इस्तेमाल करें |
|---|---|---|
| रेखीय स्केलिंग | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | जब फ़ीचर, रेंज में ज़्यादातर एक जैसा हो. फ़्लैट आकार |
| Z-स्कोर स्केलिंग | $$ x' = \frac{x - μ}{σ}$$ | जब वैरिएबल सामान्य रूप से डिस्ट्रिब्यूट होता है (पीक, माध्य के करीब होता है). बेल के आकार का |
| लॉग स्केलिंग | $$ x' = log(x)$$ | जब फ़ीचर का डिस्ट्रिब्यूशन, टेल के कम से कम किसी एक तरफ़ काफ़ी ज़्यादा हो. भारी पूंछ के आकार का |
| क्लिप करना | अगर $x > max$ है, तो $x' = max$पर सेट करें अगर $x < min$ है, तो $x' = min$ पर सेट करें |
जब फ़ीचर में बहुत ज़्यादा आउटलायर हों. |
एक्सरसाइज़: अपनी जानकारी को टेस्ट करना
मान लें कि आपने एक ऐसा मॉडल डेवलप किया है जो डेटा सेंटर के अंदर मापे गए तापमान के आधार पर, डेटा सेंटर की प्रोडक्टिविटी का अनुमान लगाता है.
आपके डेटासेट में मौजूद temperature की लगभग सभी वैल्यू,
इन अपवादों को छोड़कर 15 से 30 (सेल्सियस) के बीच हैं:
- साल में एक या दो बार, बहुत गर्म दिनों में,
temperatureमें 31 से 45 के बीच की कुछ वैल्यू रिकॉर्ड की जाती हैं. temperatureमें हर 1,000वां पॉइंट, असल तापमान के बजाय 1,000 पर सेट होता है.
temperature के लिए, सामान्य बनाने की कौनसी तकनीक सही रहेगी?
1,000 की वैल्यू गलत हैं और इन्हें क्लिप करने के बजाय, मिटा दिया जाना चाहिए.
31 से 45 के बीच की वैल्यू, मान्य डेटा पॉइंट हैं. इन वैल्यू के लिए क्लिपिंग करना एक अच्छा विकल्प हो सकता है. ऐसा तब माना जाता है, जब डेटासेट में इस तापमान की सीमा में, अच्छे अनुमान लगाने के लिए मॉडल को ट्रेनिंग देने के लिए ज़रूरत के मुताबिक उदाहरण न हों. हालांकि, अनुमान लगाने के दौरान, ध्यान दें कि क्लिप किया गया मॉडल, 45 डिग्री और 35 डिग्री के तापमान के लिए एक जैसा अनुमान लगाएगा.