بعد فحص بياناتك باستخدام أساليب إحصائية وأساليب عرض مرئي، عليك تحويل بياناتك بطرق تساعد نموذجك على التدريب بشكل أكثر فعالية. تهدف عملية التسوية إلى تحويل الميزات لتكون على مقياس مشابه. على سبيل المثال، ضع في اعتبارك الميزتَين التاليتَين:
- تتراوح قيمة السمة
Xبين 154 و24,917,482. - تتراوح الميزة
Yبين 5 و22.
تتضمّن هاتان الميزتان نطاقات مختلفة جدًا. قد تؤدي التسوية إلى تعديل X وY لكي تغطيان نطاقًا مشابهًا، ربما من 0 إلى 1.
توفّر عملية التسوية المزايا التالية:
- تساعد النماذج على التقارب بشكل أسرع أثناء التدريب. عندما يكون للميزات المختلفة نطاقات مختلفة، يمكن أن "ترتد" عملية الانحدار التدريجي وتؤدي إلى تباطؤ التقارب. ومع ذلك، فإنّ أدوات التحسين الأكثر تقدّمًا، مثل Adagrad وAdam، تحمي من هذه المشكلة من خلال تغيير معدّل التعلّم الفعّال بمرور الوقت.
- تساعد النماذج في استنتاج توقّعات أفضل. عندما يكون للميزات المختلفة نطاقات مختلفة، قد يقدم النموذج الناتج توقعات أقل فائدة.
- تساعد هذه الطريقة في تجنُّب "فخ NaN" عندما تكون قيم الميزات مرتفعة جدًا.
NaN هو اختصار
ليس رقمًا. عندما تتجاوز قيمة في أحد النماذج حد دقة الفاصلة العائمة، يضبط النظام القيمة على
NaNبدلاً من رقم. عندما يصبح أحد الأرقام في النموذج NaN، تصبح الأرقام الأخرى في النموذج أيضًا NaN في النهاية. - تساعد النموذج في تعلُّم الأوزان المناسبة لكل ميزة. بدون تسوية الميزات، يركّز النموذج بشكل كبير على الميزات ذات النطاقات الواسعة، ولا يركّز بشكل كافٍ على الميزات ذات النطاقات الضيقة.
ننصح بتسوية الميزات الرقمية التي تغطي نطاقات مختلفة بشكل واضح (مثل العمر والدخل).
ننصح أيضًا بتسوية ميزة رقمية واحدة تغطي نطاقًا واسعًا، مثل city population.
ضَع في اعتبارك الميزتَين التاليتَين:
- أدنى قيمة للميزة
Aهي -0.5 وأعلى قيمة هي +0.5. - أدنى قيمة للميزة
Bهي -5.0 وأعلى قيمة هي +5.0.
للميزتَين A وB نطاقات ضيقة نسبيًا. ومع ذلك، يبلغ مدى Feature B
10 أضعاف مدى Feature A. ولذلك:
- في بداية التدريب، يفترض النموذج أنّ الميزة
Bأكثر "أهمية" بعشر مرات من الميزةA. - سيستغرق التدريب وقتًا أطول من اللازم.
- وقد يكون النموذج الناتج غير مثالي.
سيكون الضرر الإجمالي الناتج عن عدم التسوية صغيرًا نسبيًا، ولكننا ننصحك بتسوية الميزة (أ) والميزة (ب) على المقياس نفسه، ربما من -1.0 إلى +1.0.
لنأخذ الآن ميزتَين بنطاقات مختلفة بشكل كبير:
- أدنى قيمة للميزة
Cهي -1 وأعلى قيمة هي +1. - أدنى قيمة للميزة
Dهي +5000 وأعلى قيمة هي +1,000,000,000.
إذا لم يتم تسوية السمة C والسمة D، من المحتمل أن يكون النموذج دون المستوى المطلوب. بالإضافة إلى ذلك، سيستغرق التدريب وقتًا أطول بكثير للوصول إلى النتيجة المرجوة، أو قد لا يصل إليها على الإطلاق.
يتناول هذا القسم ثلاث طرق شائعة للتسوية:
- التحجيم الخطي
- تحجيم درجة Z
- ضبط المقياس اللوغاريتمي
يتناول هذا القسم أيضًا القص. على الرغم من أنّ عملية الحصر ليست أسلوبًا حقيقيًا للتسوية، إلا أنّها تساعد في تنظيم الميزات الرقمية غير المنضبطة ضمن نطاقات تؤدي إلى إنشاء نماذج أفضل.
التحجيم الخطي
التحجيم الخطي (يُعرف عادةً باسم التحجيم) هو تحويل قيم النقطة العائمة من نطاقها الطبيعي إلى نطاق عادي، عادةً من 0 إلى 1 أو من -1 إلى +1.
يُعدّ التوسّع الخطي خيارًا جيدًا عند استيفاء جميع الشروط التالية:
- لا تتغير الحدود الدنيا والعليا لبياناتك كثيرًا بمرور الوقت.
- يحتوي العنصر على قيم متطرفة قليلة أو لا يحتوي على أي قيم متطرفة، وهذه القيم المتطرفة ليست شديدة.
- يتم توزيع الميزة بشكل موحّد تقريبًا على نطاقها. أي أنّ المدرّج التكراري سيعرض أشرطة متساوية تقريبًا لمعظم القيم.
لنفترض أنّ age هو سمة بشرية. يُعدّ التوسّع الخطي أسلوبًا جيدًا للتسوية
في age للأسباب التالية:
- الحدّان الأدنى والأقصى التقريبيان هما 0 و100.
- تحتوي
ageعلى نسبة صغيرة نسبيًا من القيم الشاذة. ويبلغ عدد الأشخاص الذين تزيد أعمارهم عن 100 عام حوالي% 0.3 فقط من إجمالي عدد السكان. - على الرغم من أنّ بعض الفئات العمرية ممثّلة بشكل أفضل من غيرها، يجب أن تحتوي مجموعة البيانات الكبيرة على أمثلة كافية من جميع الفئات العمرية.
تمرين: التحقّق من فهمك
لنفترض أنّ نموذجك يتضمّن ميزة باسمnet_worth تعرض صافي قيمة ثروة أشخاص مختلفين. هل سيكون الضبط الخطي أسلوبًا جيدًا لتسوية net_worth؟ ما سبب ذلك؟
تحجيم درجة Z
النتيجة المعيارية هي عدد الانحرافات المعيارية التي تبعدها القيمة عن المتوسط. على سبيل المثال، القيمة التي تزيد بمقدار انحرافَين معياريَين عن المتوسط يكون لها درجة Z تساوي 2.0+. القيمة التي تقل بمقدار 1.5 انحراف معياري عن المتوسط الحسابي يكون لها درجة Z تساوي -1.5.
يعني تمثيل ميزة باستخدام تحجيم النتيجة المعيارية تخزين النتيجة المعيارية لهذه الميزة في متجه الميزات. على سبيل المثال، يعرض الشكل التالي مدرّجين تكراريين:
- على اليمين، توزيع عادي كلاسيكي
- على اليسار، التوزيع نفسه بعد تسويته باستخدام مقياس Z.
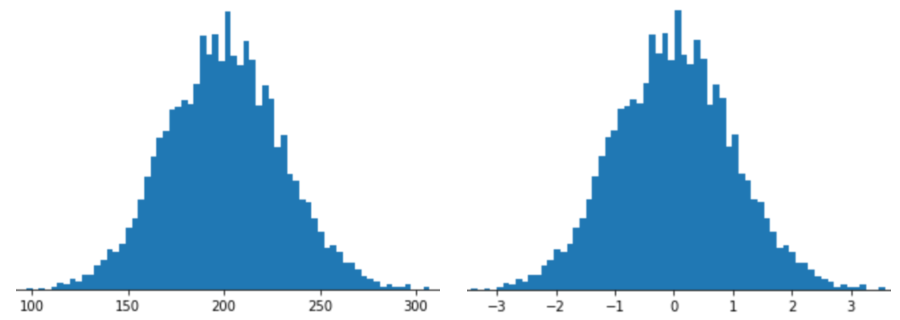
يُعدّ قياس الدرجة القياسية (الدرجة z) خيارًا جيدًا أيضًا للبيانات المشابهة لتلك المعروضة في الشكل التالي، والتي لها توزيع طبيعي غير واضح.
يُعدّ المقياس المعياري خيارًا جيدًا عندما تتّبع البيانات توزيعًا عاديًا أو توزيعًا يشبه التوزيع العادي إلى حد ما.
يُرجى العِلم أنّ بعض التوزيعات قد تكون عادية ضمن الجزء الأكبر من نطاقها، ولكنها قد تظل تتضمّن قيمًا متطرفة. على سبيل المثال، قد تتناسب جميع النقاط تقريبًا في ميزة net_worth مع 3 انحرافات معيارية، ولكن قد تكون بعض الأمثلة على هذه الميزة على بُعد مئات الانحرافات المعيارية عن المتوسط. في هذه الحالات، يمكنك دمج عملية تغيير مقياس Z مع شكل آخر من أشكال التسوية (عادةً ما يكون الاقتصاص) للتعامل مع هذه الحالة.
تمرين: التحقّق من فهمك
لنفترض أنّ نموذجك يتدرب على سمة اسمهاheight تتضمّن أطوال البالغين من النساء وعددهم عشرة ملايين. هل سيكون قياس الدرجة z أسلوبًا جيدًا لتسوية height؟ ما سبب ذلك؟
تغيير المقياس إلى لوغاريتمي
يحسب مقياس اللوغاريتم اللوغاريتم الخاص بالقيمة الأولية. من الناحية النظرية، يمكن أن يكون اللوغاريتم أي أساس، ولكن من الناحية العملية، عادةً ما يحسب مقياس اللوغاريتم اللوغاريتم الطبيعي (ln).
يكون مقياس السجلّ مفيدًا عندما تتوافق البيانات مع توزيع قانون القوة. بشكل عام، يبدو توزيع قانون القوة على النحو التالي:
- تكون قيم
Yمرتفعة جدًا عندما تكون قيمXمنخفضة. - مع زيادة قيم
X، تنخفض قيمYبسرعة. نتيجةً لذلك، تتضمّن القيم المرتفعة منXقيمًا منخفضة جدًا منY.
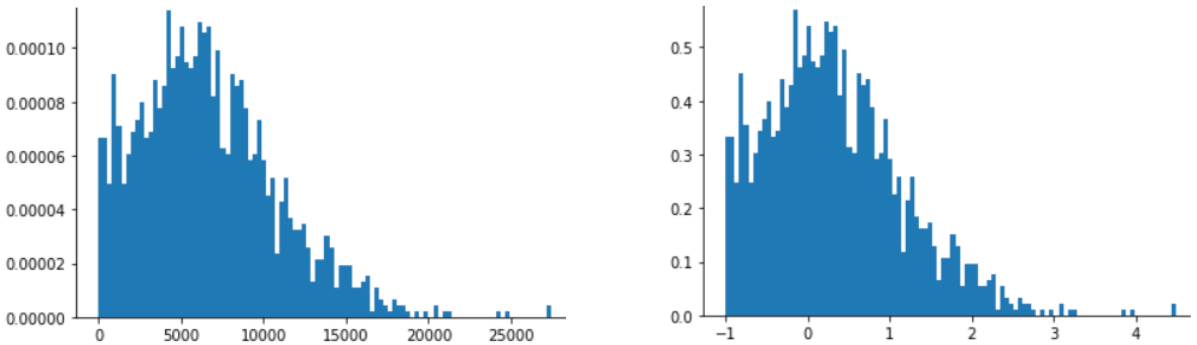
تُعد تقييمات الأفلام مثالاً جيدًا على توزيع قانون القوة. في الشكل التالي، لاحظ ما يلي:
- بعض الأفلام تتضمّن الكثير من تقييمات المستخدمين. (تتضمّن القيم المنخفضة لـ
Xقيمًا مرتفعة لـY). - معظم الأفلام لديها عدد قليل جدًا من تقييمات المستخدمين. (تكون قيم
Yمنخفضة عندما تكون قيمXمرتفعة).
يؤدي تغيير مقياس السجلّ إلى تغيير التوزيع، ما يساعد في تدريب نموذج يقدّم توقّعات أفضل.

كمثال ثانٍ، تتوافق مبيعات الكتب مع توزيع قانون القوة للأسباب التالية:
- تبيع معظم الكتب المنشورة عددًا قليلاً جدًا من النُسخ، ربما مئة أو مئتين.
- تبيع بعض الكتب عددًا معتدلاً من النسخ، أي بالآلاف.
- لن يبيع سوى عدد قليل من الكتب الأكثر مبيعًا أكثر من مليون نسخة.
لنفترض أنّك تدرب نموذجًا خطيًا للعثور على العلاقة بين، على سبيل المثال، أغلفة الكتب ومبيعاتها. يجب أن يجد نموذج خطي يتم تدريبه على القيم الأولية شيئًا ما حول أغلفة الكتب التي تبيع مليون نسخة، ويكون هذا الشيء أقوى بمقدار 10,000 مرة من أغلفة الكتب التي تبيع 100 نسخة فقط. ومع ذلك، فإنّ استخدام المقياس اللوغاريتمي لجميع أرقام المبيعات يجعل المهمة أكثر جدوى. على سبيل المثال، لوغاريتم العدد 100 هو:
~4.6 = ln(100)
بينما اللوغاريتم الأساسي لـ 1,000,000 هو:
~13.8 = ln(1,000,000)
لذلك، فإنّ لوغاريتم 1,000,000 أكبر بثلاث مرات تقريبًا من لوغاريتم 100. من المحتمل أن تتخيّل أنّ غلاف الكتاب الأكثر مبيعًا أكثر تأثيرًا (بطريقة ما) بثلاث مرات من غلاف الكتاب الذي يحقّق مبيعات قليلة.
القص
القص هو أسلوب يهدف إلى تقليل تأثير القيم المتطرفة. باختصار، يحدّ التقطيع عادةً من قيمة القيم الشاذة (يقلّلها) إلى قيمة قصوى معيّنة. قد تبدو فكرة قص الفيديو غريبة، ولكنّها قد تكون فعّالة جدًا.
على سبيل المثال، لنفترض أنّ مجموعة بيانات تحتوي على سمة باسم roomsPerPerson، والتي تمثّل عدد الغرف (إجمالي عدد الغرف مقسومًا على عدد السكان) لمنازل مختلفة. يوضّح الرسم البياني التالي أنّ أكثر من% 99 من قيم الميزات تتوافق مع التوزيع الطبيعي (بمتوسط يبلغ 1.8 تقريبًا وانحراف معياري يبلغ 0.7). ومع ذلك، تتضمّن الميزة بعض القيم الشاذة، بعضها متطرّف:
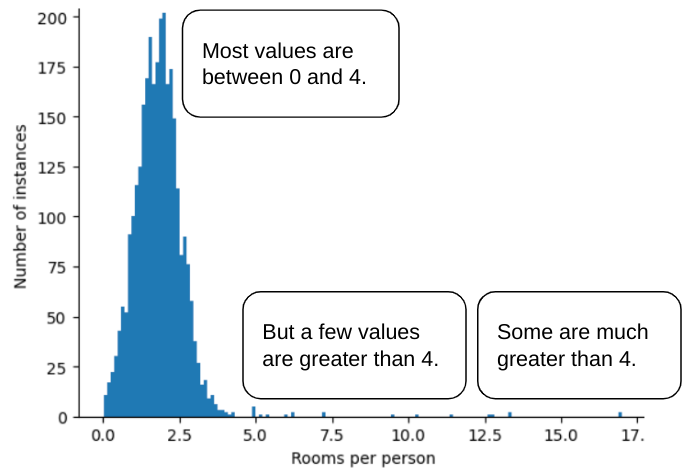
كيف يمكنك تقليل تأثير هذه القيم الشاذة المتطرفة؟ حسنًا، المدرّج التكراري ليس توزيعًا متساويًا أو توزيعًا طبيعيًا أو توزيعًا لقانون القوة. ماذا لو حدّدت أو قصصت الحد الأقصى لقيمة roomsPerPerson عند قيمة عشوائية، مثلاً 4.0؟
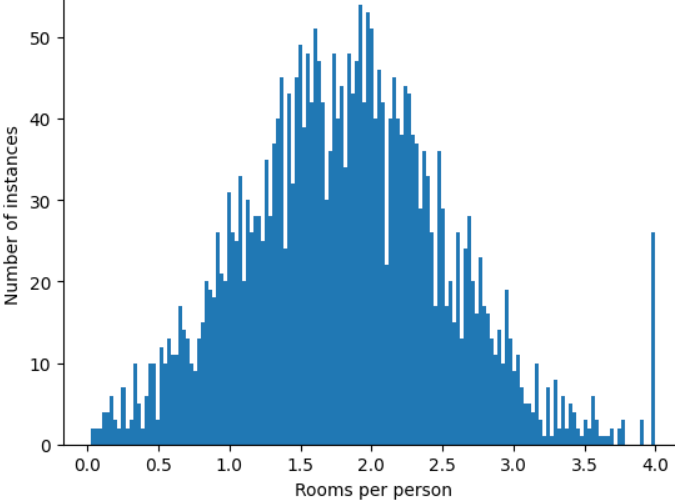
لا يعني قص قيمة السمة عند 4.0 أنّ النموذج يتجاهل جميع القيم الأكبر من 4.0. بل يعني ذلك أنّ جميع القيم التي كانت أكبر من 4.0 أصبحت الآن 4.0. يوضّح هذا الرسم البياني الارتفاع الغريب عند النقطة 4.0. على الرغم من هذا التحدي، أصبحت مجموعة الميزات المعدَّلة أكثر فائدة من البيانات الأصلية.
انتظر لحظة! هل يمكن حقًا تقليل كل قيمة شاذة إلى حدّ أعلى عشوائي؟ نعم، عند تدريب نموذج.
يمكنك أيضًا قص القيم بعد تطبيق أشكال أخرى من التسوية. على سبيل المثال، لنفترض أنّك تستخدم مقياس Z، ولكن بعض القيم الشاذة لها قيم مطلقة أكبر بكثير من 3. في هذه الحالة، يمكنك إجراء ما يلي:
- يتم ضبط قيم Z التي تزيد عن 3 لتصبح 3 بالضبط.
- يتم تعديل قيم Z-score للمقاطع التي تقل عن 3- لتصبح 3- بالضبط.
يمنع الاقتصاص النموذج من التركيز بشكل مفرط على البيانات غير المهمة. ومع ذلك، بعض القيم الشاذة مهمة في الواقع، لذا يجب قص القيم بعناية.
ملخّص لتقنيات التسوية
| أسلوب التسوية | الصيغة | حالات الاستخدام |
|---|---|---|
| التحجيم الخطي | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | عندما تكون الميزة موزّعة بشكل موحّد في معظم النطاق مسطّحة الشكل |
| تحجيم درجة Z | $$ x' = \frac{x - μ}{σ}$$ | عندما تكون الميزة موزَّعة بشكل طبيعي (القمة قريبة من المتوسط) على شكل جرس |
| تغيير المقياس إلى لوغاريتمي | $$ x' = log(x)$$ | عندما يكون توزيع الميزات منحرفًا بشكل كبير على أحد جانبي الذيل على الأقل على شكل ذيل سمكة |
| القص | إذا كان $x > max$، اضبط $x' = max$ إذا كان $x < min$، اضبط $x' = min$ |
عندما تحتوي السمة على قيم متطرفة. |
تمرين: اختبار معلوماتك
لنفترض أنّك بصدد تطوير نموذج يتوقّع إنتاجية مركز بيانات استنادًا إلى درجة الحرارة التي يتم قياسها داخل مركز البيانات.
تقع معظم قيم temperature في مجموعة البيانات بين 15 و30 درجة مئوية، باستثناء ما يلي:
- مرة أو مرتين في السنة، في الأيام شديدة الحرارة، يتم تسجيل بضع قيم بين 31 و45 في
temperature. - يتم ضبط كل نقطة من النقاط الألفية في
temperatureعلى 1,000 بدلاً من درجة الحرارة الفعلية.
أيّ مما يلي يمثّل أسلوب تسوية معقولاً للبيانات temperature؟
القيم التي تبلغ 1,000 هي أخطاء، ويجب حذفها بدلاً من اقتطاعها.
القيم بين 31 و45 هي نقاط بيانات صالحة. من المحتمل أن يكون الاقتصاص فكرة جيدة لهذه القيم، على افتراض أنّ مجموعة البيانات لا تحتوي على أمثلة كافية في نطاق درجة الحرارة هذا لتدريب النموذج على تقديم توقّعات جيدة. ومع ذلك، أثناء الاستدلال، يُرجى العِلم أنّ النموذج الذي تمّ اقتطاعه سيقدّم بالتالي التوقّع نفسه لدرجة حرارة 45 درجة مئوية كما هو الحال بالنسبة إلى درجة حرارة 35 درجة مئوية.