Page Summary
-
Synthetic features, like polynomial transforms, enable linear models to represent non-linear relationships by introducing new features based on existing ones.
-
Polynomial transforms involve raising an existing feature to a power, often informed by domain knowledge, such as physical laws involving squared terms.
-
By incorporating synthetic features, linear regression models can effectively separate data points that are not linearly separable using curves instead of straight lines.
-
This approach maintains the simplicity of linear regression while expanding its capacity to capture complex patterns within the data.
-
Feature crosses, a related concept for categorical data, synthesize new features by combining existing features, further enhancing model flexibility.
Sometimes, when the ML practitioner has domain knowledge suggesting that one variable is related to the square, cube, or other power of another variable, it's useful to create a synthetic feature from one of the existing numerical features.
Consider the following spread of data points, where pink circles represent one class or category (for example, a species of tree) and green triangles another class (or species of tree):
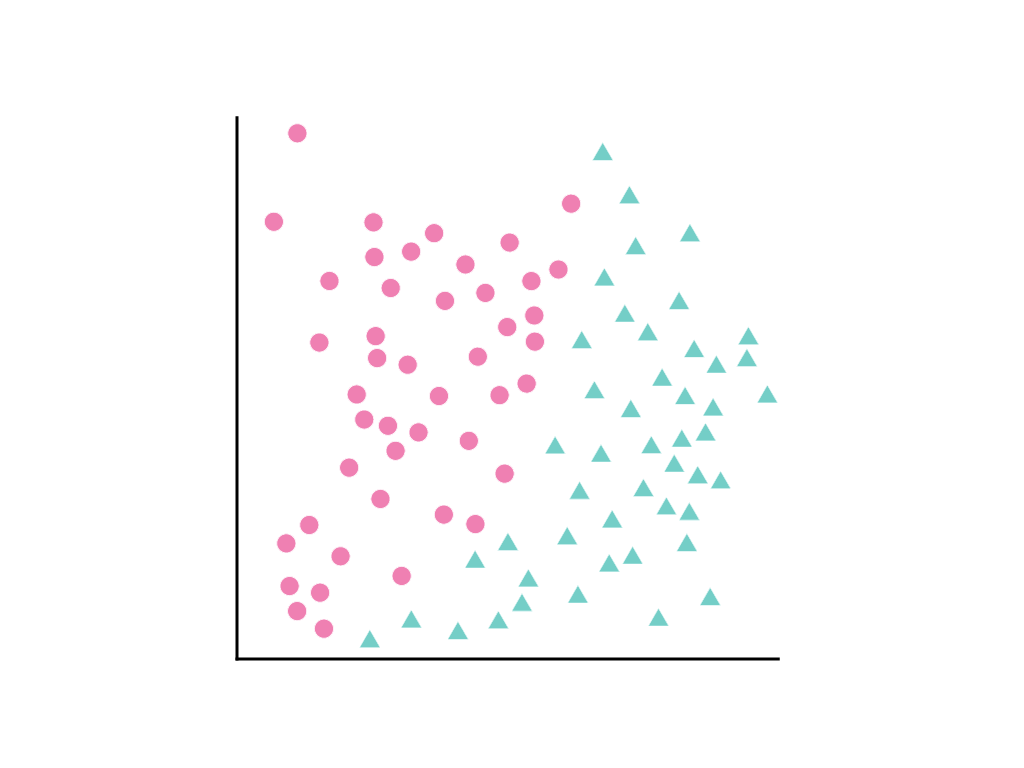
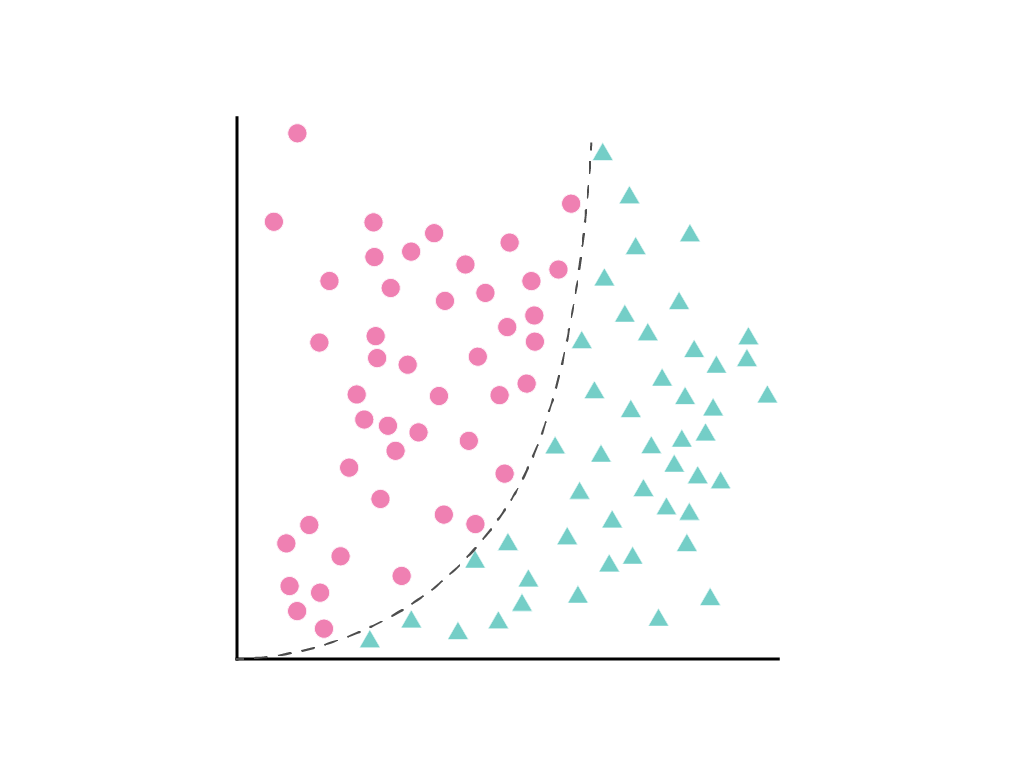
It's not possible to draw a straight line that cleanly separates the two classes, but it is possible to draw a curve that does so:
As discussed in the Linear regression module, a linear model with one feature, $x_1$, is described by the linear equation:
Additional features are handled by the addition of terms \(w_2x_2\), \(w_3x_3\), etc.
Gradient descent finds the weight $w_1$ (or weights \(w_1\), \(w_2\), \(w_3\), in the case of additional features) that minimizes the loss of the model. But the data points shown cannot be separated by a line. What can be done?
It's possible to keep both the linear equation and allow nonlinearity by defining a new term, \(x_2\), that is simply \(x_1\) squared:
This synthetic feature, called a polynomial transform, is treated like any other feature. The previous linear formula becomes:
This can still be treated like a linear regression problem, and the weights determined through gradient descent, as usual, despite containing a hidden squared term, the polynomial transform. Without changing how the linear model trains, the addition of a polynomial transform allows the model to separate the data points using a curve of the form $y = b + w_1x + w_2x^2$.
Usually the numerical feature of interest is multiplied by itself, that is, raised to some power. Sometimes an ML practitioner can make an informed guess about the appropriate exponent. For example, many relationships in the physical world are related to squared terms, including acceleration due to gravity, the attenuation of light or sound over distance, and elastic potential energy.
If you transform a feature in a way that changes its scale, you should consider experimenting with normalizing it as well. Normalizing after transforming might make the model perform better. For more information, see Numerical Data: Normalization.
A related concept in categorical data is the feature cross, which more frequently synthesizes two different features.