Wenn der ML-Experte Fachwissen hat, das darauf hindeutet, dass eine Variable mit dem Quadrat, dem Kubik oder einer anderen Potenz einer anderen Variablen zusammenhängt, ist es manchmal sinnvoll, eine synthetische Variable aus einer der vorhandenen numerischen Variablen zu erstellen.
Betrachten Sie die folgende Verteilung von Datenpunkten, bei der rosa Kreise eine Klasse oder Kategorie (z. B. eine Baumart) und grüne Dreiecke eine andere Klasse (oder Baumart) repräsentieren:
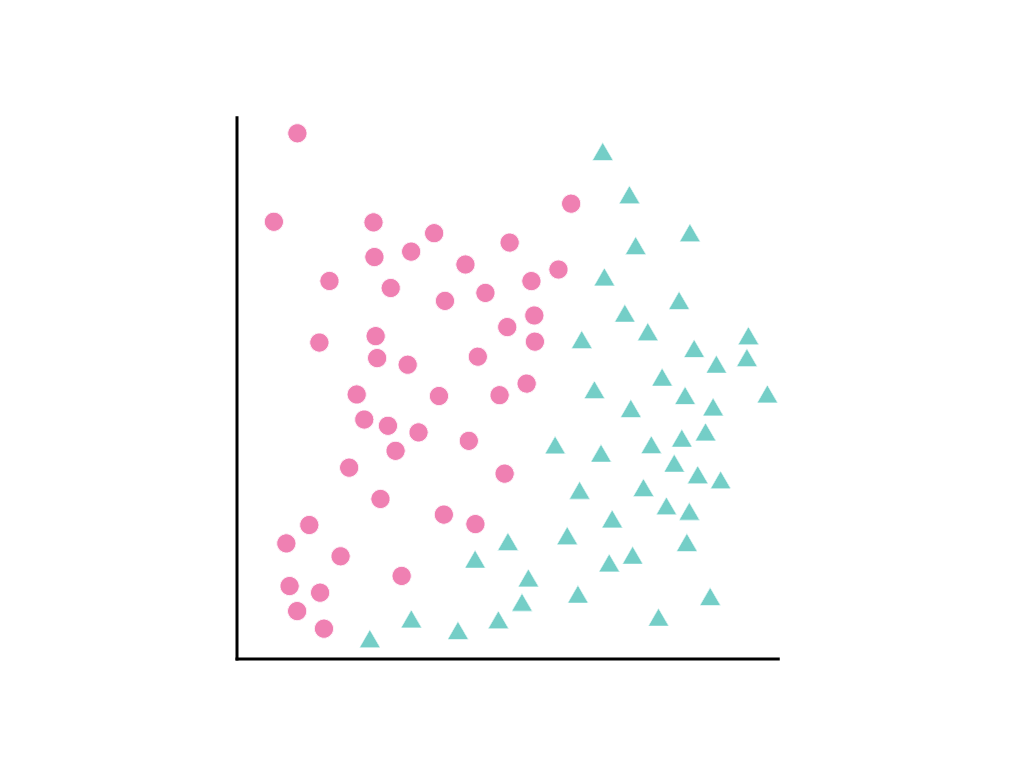
Es ist nicht möglich, eine gerade Linie zu zeichnen, die die beiden Klassen sauber voneinander trennt. Es ist jedoch möglich, eine Kurve zu zeichnen, die dies tut:
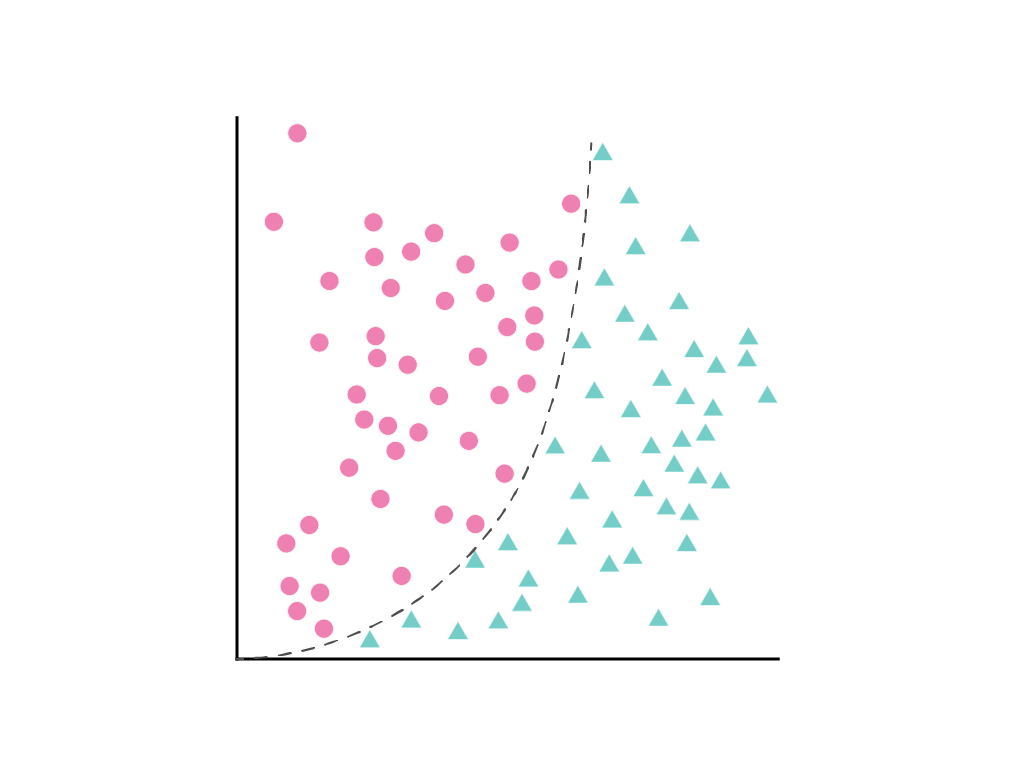
Wie im Modul „Lineare Regression“ erläutert, wird ein lineares Modell mit einem Feature, $x_1$, durch die lineare Gleichung beschrieben:
Zusätzliche Funktionen werden durch Hinzufügen von Begriffen wie \(w_2x_2\)oder\(w_3x_3\)verwaltet.
Bei der Gradientenabstiegsmethode wird das Gewicht w1 (oder die Gewichte\(w_1\), \(w_2\), \(w_3\)bei zusätzlichen Funktionen) ermittelt, mit dem der Verlust des Modells minimiert wird. Die angezeigten Datenpunkte können jedoch nicht durch eine Linie getrennt werden. Was kann man dagegen tun?
Es ist möglich, sowohl die lineare Gleichung beizubehalten als auch Nichtlinearität zuzulassen, indem ein neuer Term \(x_2\)definiert wird, der einfach \(x_1\) hoch 2 ist:
Dieses synthetische Element, die sogenannte Polynomtransformation, wird wie jedes andere Element behandelt. Die vorherige lineare Formel wird zu:
Dieses Problem kann weiterhin wie eine lineare Regression behandelt und die Gewichte wie gewohnt durch Gradientenabstieg bestimmt werden, obwohl es einen versteckten quadratischen Term, die Polynomtransformation, enthält. Ohne die Art und Weise zu ändern, wie das lineare Modell trainiert wird, kann das Modell durch Hinzufügen einer polynomen Transformation die Datenpunkte mit einer Kurve der Form $y = b + w_1x + w_2x^2$ trennen.
Normalerweise wird die betreffende numerische Variable mit sich selbst multipliziert, d. h., sie wird mit einer Potenz erhöht. Manchmal kann ein ML-Experte eine fundierte Vermutung über den geeigneten Exponenten anstellen. Viele Beziehungen in der realen Welt beziehen sich beispielsweise auf quadratische Terme, darunter die Beschleunigung durch die Schwerkraft, die Dämpfung von Licht oder Schall über die Entfernung und die elastische potenzielle Energie.
Wenn Sie ein Element so transformieren, dass sich sein Maßstab ändert, sollten Sie auch mit der Normalisierung experimentieren. Durch die Normalisierung nach der Transformation lässt sich die Leistung des Modells möglicherweise verbessern. Weitere Informationen finden Sie unter Numerische Daten: Normalisierung.
Ein ähnliches Konzept bei kategorischen Daten ist die Merkmalskreuzung, bei der häufiger zwei verschiedene Merkmale kombiniert werden.