ส่วนนี้จะสำรวจคำถาม 3 ข้อต่อไปนี้
- ชุดข้อมูลที่มีความสมดุลของคลาสและชุดข้อมูลที่มีความไม่สมดุลของคลาสแตกต่างกันอย่างไร
- เหตุใดการฝึกชุดข้อมูลที่ไม่สมดุลจึงเป็นเรื่องยาก
- คุณจะแก้ปัญหาการฝึกชุดข้อมูลที่ไม่สมดุลได้อย่างไร
ชุดข้อมูลที่สมดุลของคลาสเทียบกับชุดข้อมูลที่ไม่สมดุลของคลาส
พิจารณาชุดข้อมูลที่มีป้ายกำกับเชิงหมวดหมู่ซึ่งมีค่าเป็นคลาสเชิงบวกหรือคลาสเชิงลบ ในชุดข้อมูลที่สมดุลของคลาส จำนวนคลาสที่เป็นบวก และคลาสที่เป็นลบจะ เท่ากันโดยประมาณ ตัวอย่างเช่น ชุดข้อมูลที่มีคลาสที่เป็นบวก 235 คลาสและคลาสที่เป็นลบ 247 คลาสถือเป็นชุดข้อมูลที่สมดุล
ในชุดข้อมูลที่ไม่สมดุลของคลาส ป้ายกำกับหนึ่งจะพบบ่อยกว่าอีกป้ายกำกับหนึ่งอย่างมาก ในโลกแห่งความเป็นจริง ชุดข้อมูลที่ไม่สมดุลของคลาสพบได้บ่อยกว่าชุดข้อมูลที่สมดุลของคลาสมาก ตัวอย่างเช่น ในชุดข้อมูลธุรกรรมบัตรเครดิต การซื้อที่เป็นการฉ้อโกงอาจมีสัดส่วนน้อยกว่า 0.1% ของตัวอย่าง ในทำนองเดียวกัน ในชุดข้อมูลการวินิจฉัยทางการแพทย์ จำนวนผู้ป่วยที่เป็นไวรัสหายากอาจน้อยกว่า 0.01% ของตัวอย่างทั้งหมด ในชุดข้อมูลที่มีความไม่สมดุลของคลาส
- ป้ายกำกับที่พบบ่อยกว่าเรียกว่าคลาสส่วนใหญ่
- ป้ายกำกับที่มีการใช้งานน้อยเรียกว่าคลาสส่วนน้อย
ความยากในการฝึกชุดข้อมูลที่มีความไม่สมดุลของคลาสอย่างรุนแรง
การฝึกมีจุดมุ่งหมายเพื่อสร้างโมเดลที่แยกความแตกต่างระหว่างคลาสที่เป็นบวกกับคลาสที่เป็นลบได้สำเร็จ โดยกลุ่มต้องมีจำนวนทั้งคลาสเชิงบวกและคลาสเชิงลบเพียงพอ ซึ่งไม่ใช่ปัญหา เมื่อฝึกในชุดข้อมูลที่มีความไม่สมดุลของคลาสเล็กน้อย เนื่องจากแม้แต่แบตช์ขนาดเล็ก ก็มักจะมีตัวอย่างที่เพียงพอของทั้งคลาสบวกและ คลาสลบ อย่างไรก็ตาม ชุดข้อมูลที่มีความไม่สมดุลของคลาสอย่างรุนแรงอาจมีตัวอย่างคลาสส่วนน้อยไม่เพียงพอสำหรับการฝึกที่เหมาะสม
ตัวอย่างเช่น พิจารณาชุดข้อมูลที่มีความไม่สมดุลของคลาสที่แสดงในรูปที่ 6 ซึ่งมีลักษณะดังนี้
- ป้ายกำกับ 200 รายการอยู่ในคลาสส่วนใหญ่
- มีป้ายกำกับ 2 รายการอยู่ในคลาสส่วนน้อย
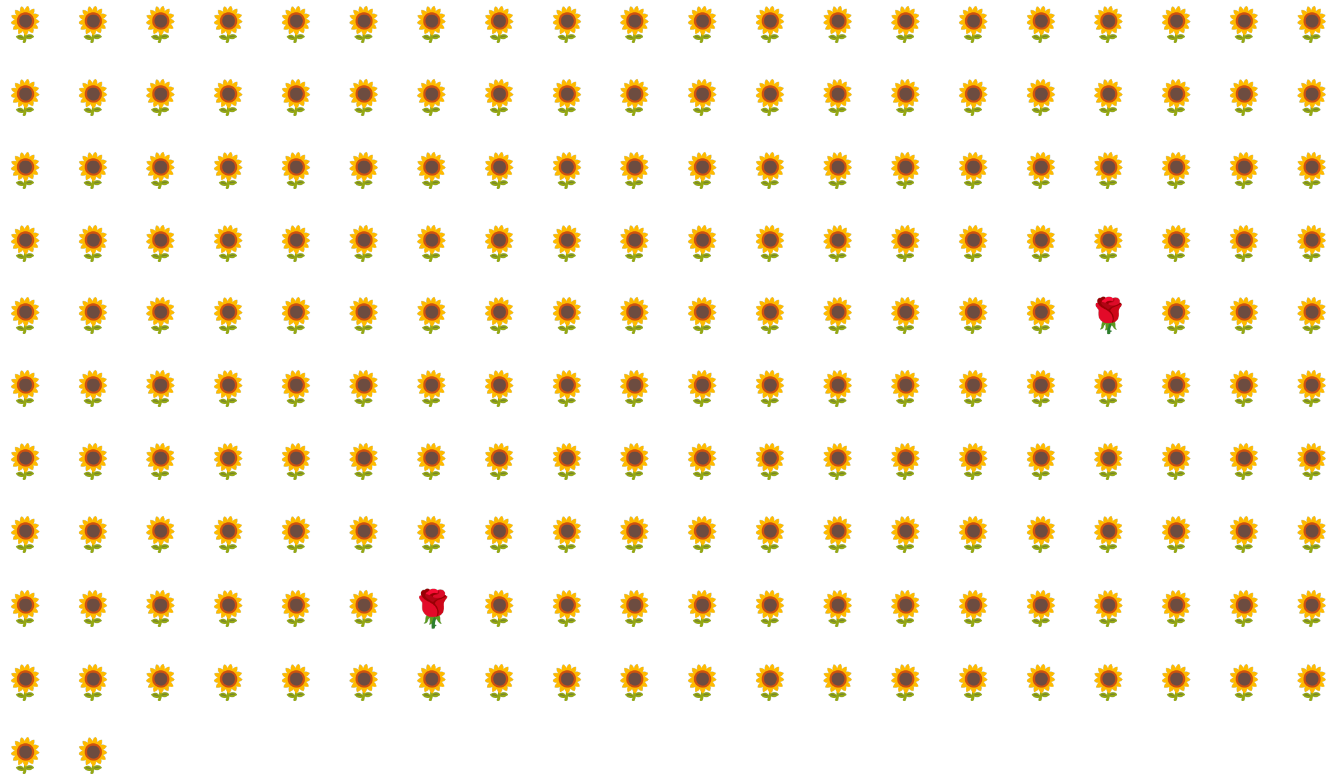
หากขนาดกลุ่มคือ 20 กลุ่มส่วนใหญ่จะไม่มีตัวอย่างของคลาสส่วนน้อย หากขนาดกลุ่มคือ 100 แต่ละกลุ่มจะมีตัวอย่างคลาสรองเพียง 1 รายการโดยเฉลี่ย ซึ่งไม่เพียงพอสำหรับการฝึกที่เหมาะสม แม้ว่าขนาดกลุ่มจะใหญ่ขึ้นมาก แต่ก็ยังคงให้สัดส่วนที่ไม่สมดุลดังกล่าว ซึ่งอาจทำให้โมเดล ฝึกไม่ถูกต้อง
การฝึกชุดข้อมูลที่มีความไม่สมดุลของคลาส
ในระหว่างการฝึก โมเดลควรเรียนรู้ 2 สิ่งต่อไปนี้
- ลักษณะของแต่ละคลาส นั่นคือ ค่าฟีเจอร์ใดที่สอดคล้องกับคลาสใด
- ความถี่ของแต่ละคลาส นั่นคือ การกระจายสัมพัทธ์ของคลาสเป็นอย่างไร
การฝึกมาตรฐานจะรวมเป้าหมายทั้ง 2 นี้เข้าด้วยกัน ในทางตรงกันข้าม เทคนิค 2 ขั้นตอนต่อไปนี้ที่เรียกว่าการสุ่มตัวอย่างแบบดาวน์แซมปลิงและการเพิ่มน้ำหนักให้กับคลาสส่วนใหญ่จะแยกเป้าหมายทั้ง 2 นี้ออกจากกัน ซึ่งช่วยให้โมเดลบรรลุเป้าหมายทั้ง 2 ได้
ขั้นตอนที่ 1: ดาวน์แซมเปิลคลาสส่วนใหญ่
การดาวน์แซมปลิงหมายถึงการฝึก โดยใช้ตัวอย่างของคลาสส่วนใหญ่ที่มีเปอร์เซ็นต์ต่ำอย่างไม่สมส่วน กล่าวคือ คุณบังคับให้ชุดข้อมูลที่มีความไม่สมดุลของคลาสกลายเป็นชุดข้อมูลที่มีความสมดุลมากขึ้นโดยการละเว้นตัวอย่างคลาสส่วนใหญ่จำนวนมากจากการฝึก การดาวน์แซมปลิงจะเพิ่มโอกาสที่แต่ละกลุ่ม จะมีตัวอย่างของคลาสส่วนน้อยเพียงพอที่จะฝึกโมเดลได้อย่างเหมาะสม และมีประสิทธิภาพ
ตัวอย่างเช่น ชุดข้อมูลที่มีความไม่สมดุลของคลาสที่แสดงในรูปที่ 6 ประกอบด้วยตัวอย่างคลาสส่วนใหญ่ 99% และตัวอย่างคลาสส่วนน้อย 1% การสุ่มตัวอย่างแบบดาวน์แซมปลิงของคลาสส่วนใหญ่ ด้วยปัจจัย 25 จะสร้างชุดการฝึกที่สมดุลมากขึ้น (คลาสส่วนใหญ่ 80% ต่อคลาสส่วนน้อย 20%) ตามที่แนะนำในรูปที่ 7

ขั้นตอนที่ 2: เพิ่มน้ำหนักให้กับคลาสที่ดาวน์แซมเปิล
การดาวน์แซมปลิงทำให้เกิดอคติในการคาดการณ์ โดยการแสดงโลกที่สร้างขึ้นซึ่งคลาสมีความสมดุลมากกว่าในโลกแห่งความเป็นจริงให้โมเดลเห็น หากต้องการแก้ไขอคตินี้ คุณต้อง "เพิ่มน้ำหนัก" ให้กับคลาสส่วนใหญ่ ด้วยปัจจัยที่คุณใช้ดาวน์แซมปลิง การเพิ่มน้ำหนักหมายถึงการพิจารณา การสูญเสียในตัวอย่างของคลาสส่วนใหญ่รุนแรงกว่าการสูญเสียในตัวอย่างของคลาสส่วนน้อย
เช่น เราลดตัวอย่างคลาสส่วนใหญ่ลง 25 เท่า ดังนั้นเราจึงต้อง เพิ่มน้ำหนักคลาสส่วนใหญ่ขึ้น 25 เท่า กล่าวคือ เมื่อโมเดล คาดการณ์คลาสส่วนใหญ่ผิดพลาด ให้ถือว่าค่า Loss เป็นข้อผิดพลาด 25 รายการ (คูณค่า Loss ปกติด้วย 25)

คุณควรดาวน์แซมเปิลและเพิ่มน้ำหนักมากน้อยเพียงใดเพื่อปรับสมดุลชุดข้อมูล หากต้องการหาคำตอบ คุณควรทดสอบปัจจัยการดาวน์แซมปลิง และการเพิ่มน้ำหนักที่แตกต่างกันเช่นเดียวกับการทดสอบไฮเปอร์พารามิเตอร์อื่นๆ
ประโยชน์ของเทคนิคนี้
การดาวน์แซมปลิงและการเพิ่มน้ำหนักให้กับคลาสส่วนใหญ่มีประโยชน์ดังนี้
- โมเดลที่ดีขึ้น: โมเดลผลลัพธ์ "รู้" ทั้ง 2 สิ่งต่อไปนี้
- ความเชื่อมโยงระหว่างฟีเจอร์กับป้ายกำกับ
- การกระจายที่แท้จริงของคลาส
- การบรรจบกันเร็วขึ้น: ในระหว่างการฝึก โมเดลจะเห็นคลาสส่วนน้อยบ่อยขึ้น ซึ่งจะช่วยให้โมเดลบรรจบกันได้เร็วขึ้น