En esta sección, se exploran las siguientes tres preguntas:
- ¿Cuál es la diferencia entre los conjuntos de datos equilibrados y los conjuntos de datos desequilibrados en cuanto a las clases?
- ¿Por qué es difícil entrenar un conjunto de datos desequilibrado?
- ¿Cómo puedes superar los problemas del entrenamiento de conjuntos de datos desequilibrados?
Conjuntos de datos equilibrados en cuanto a las clases y conjuntos de datos con desequilibrio de clases
Considera un conjunto de datos que contiene una etiqueta categórica cuyo valor es la clase positiva o la clase negativa. En un conjunto de datos equilibrado por clase, la cantidad de clases positivas y clases negativas es aproximadamente igual. Por ejemplo, un conjunto de datos que contiene 235 clases positivas y 247 clases negativas es un conjunto de datos equilibrado.
En un conjunto de datos con desequilibrio de clases, una etiqueta es considerablemente más común que la otra. En el mundo real, los conjuntos de datos con desequilibrio de clases son mucho más comunes que los conjuntos de datos con equilibrio de clases. Por ejemplo, en un conjunto de datos de transacciones con tarjetas de crédito, las compras fraudulentas podrían representar menos del 0.1% de los ejemplos. Del mismo modo, en un conjunto de datos de diagnóstico médico, la cantidad de pacientes con un virus poco común podría ser inferior al 0.01% de los ejemplos totales. En un conjunto de datos con desequilibrio de clases:
- La etiqueta más común se denomina clase mayoritaria.
- La etiqueta menos común se denomina clase minoritaria.
La dificultad de entrenar conjuntos de datos con un desequilibrio de clases grave
El entrenamiento tiene como objetivo crear un modelo que distinga correctamente la clase positiva de la clase negativa. Para ello, los lotes necesitan una cantidad suficiente de clases positivas y negativas. Esto no es un problema cuando se entrena con un conjunto de datos con un desequilibrio de clases leve, ya que incluso los lotes pequeños suelen contener suficientes ejemplos de la clase positiva y la clase negativa. Sin embargo, un conjunto de datos con un desequilibrio grave entre las clases podría no contener suficientes ejemplos de la clase minoritaria para un entrenamiento adecuado.
Por ejemplo, considera el conjunto de datos con desequilibrio de clases que se ilustra en la Figura 6, en el que se cumple lo siguiente:
- 200 etiquetas están en la clase mayoritaria.
- 2 etiquetas están en la clase minoritaria.
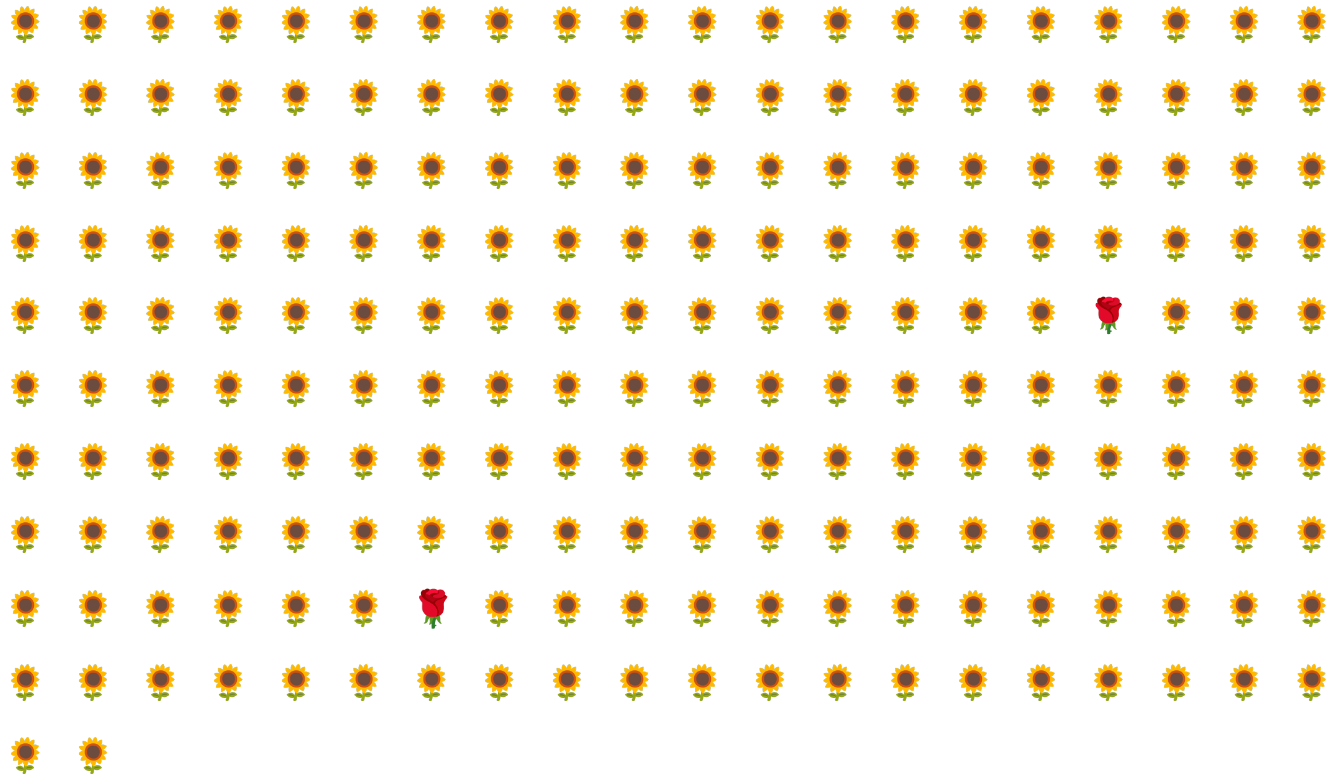
Si el tamaño del lote es 20, la mayoría de los lotes no contendrán ejemplos de la clase minoritaria. Si el tamaño del lote es 100, cada lote contendrá un promedio de solo un ejemplo de clase minoritaria, lo que es insuficiente para un entrenamiento adecuado. Incluso un tamaño de lote mucho mayor seguirá produciendo una proporción tan desequilibrada que es posible que el modelo no se entrene correctamente.
Entrenamiento de un conjunto de datos con desequilibrio de clases
Durante el entrenamiento, un modelo debe aprender dos cosas:
- Cómo se ve cada clase, es decir, qué valores de atributos corresponden a qué clase
- Qué tan común es cada clase, es decir, cuál es la distribución relativa de las clases
El entrenamiento estándar confunde estos dos objetivos. En cambio, la siguiente técnica de dos pasos llamada submuestreo y aumento de la ponderación de la clase mayoritaria separa estos dos objetivos, lo que permite que el modelo alcance ambos objetivos.
Paso 1: Submuestrea la clase mayoritaria
Reducción de muestreo significa entrenar con un porcentaje desproporcionadamente bajo de ejemplos de la clase mayoritaria. Es decir, fuerces artificialmente un conjunto de datos con desequilibrio de clases para que se vuelva algo más equilibrado omitiendo muchos de los ejemplos de la clase mayoritaria del entrenamiento. El submuestreo aumenta considerablemente la probabilidad de que cada lote contenga suficientes ejemplos de la clase minoritaria para entrenar el modelo de forma adecuada y eficiente.
Por ejemplo, el conjunto de datos desequilibrado en cuanto a las clases que se muestra en la Figura 6 consta de un 99% de ejemplos de la clase mayoritaria y un 1% de ejemplos de la clase minoritaria. La reducción de muestreo de la clase mayoritaria en un factor de 25 crea artificialmente un conjunto de entrenamiento más equilibrado (80% de clase mayoritaria y 20% de clase minoritaria), como se sugiere en la figura 7:

Paso 2: Aumenta la ponderación de la clase submuestreada
El submuestreo introduce un sesgo de predicción, ya que le muestra al modelo un mundo artificial en el que las clases están más equilibradas que en el mundo real. Para corregir este sesgo, debes aumentar el peso de las clases mayoritarias según el factor por el que realizaste la reducción de muestreo. El incremento de ponderación significa tratar la pérdida en un ejemplo de clase mayoritaria con más severidad que la pérdida en un ejemplo de clase minoritaria.
Por ejemplo, si reducimos la muestra de la clase mayoritaria en un factor de 25, debemos aumentar su peso en un factor de 25. Es decir, cuando el modelo predice erróneamente la clase mayoritaria, trata la pérdida como si fueran 25 errores (multiplica la pérdida normal por 25).

¿Cuánto debes submuestrear y sobreponderar para reequilibrar tu conjunto de datos? Para determinar la respuesta, debes experimentar con diferentes factores de submuestreo y aumento de peso, al igual que lo harías con otros hiperparámetros.
Beneficios de esta técnica
La reducción del muestreo y el aumento de la ponderación de la clase mayoritaria aportan los siguientes beneficios:
- Mejor modelo: El modelo resultante "conoce" lo siguiente:
- La conexión entre los atributos y las etiquetas
- La distribución real de las clases
- Convergencia más rápida: Durante el entrenamiento, el modelo ve la clase minoritaria con más frecuencia, lo que ayuda a que el modelo converja más rápido.