Bagian ini membahas tiga pertanyaan berikut:
- Apa perbedaan antara set data seimbang kelas dan set data tidak seimbang kelas?
- Mengapa pelatihan set data yang tidak seimbang sulit dilakukan?
- Bagaimana cara mengatasi masalah pelatihan set data yang tidak seimbang?
Set data seimbang kelas versus set data tidak seimbang kelas
Pertimbangkan set data yang berisi label kategoris yang nilainya adalah kelas positif atau kelas negatif. Dalam dataset yang seimbang kelasnya, jumlah kelas positif dan kelas negatif hampir sama. Misalnya, set data yang berisi 235 kelas positif dan 247 kelas negatif adalah set data seimbang.
Dalam set data kelas tidak seimbang, satu label jauh lebih umum daripada label lainnya. Di dunia nyata, set data dengan kelas tidak seimbang jauh lebih umum daripada set data dengan kelas seimbang. Misalnya, dalam set data transaksi kartu kredit, pembelian yang menipu mungkin hanya mencakup kurang dari 0,1% contoh. Demikian pula, dalam set data diagnosis medis, jumlah pasien dengan virus langka mungkin kurang dari 0,01% dari total contoh. Dalam set data kelas tidak seimbang:
- Label yang lebih umum disebut kelas mayoritas.
- Label yang kurang umum disebut kelas minoritas.
Kesulitan melatih set data yang sangat tidak seimbang
Pelatihan bertujuan untuk membuat model yang berhasil membedakan kelas positif dari kelas negatif. Untuk melakukannya, batch memerlukan jumlah kedua class positif dan class negatif yang memadai. Hal ini tidak menjadi masalah saat melatih set data yang tidak seimbang secara ringan karena bahkan batch kecil biasanya berisi contoh yang cukup dari class positif dan class negatif. Namun, set data yang sangat tidak seimbang mungkin tidak berisi cukup contoh kelas minoritas untuk pelatihan yang tepat.
Misalnya, pertimbangkan set data kelas tidak seimbang yang diilustrasikan dalam Gambar 6 yang:
- 200 label berada di class mayoritas.
- 2 label berada di kelas minoritas.
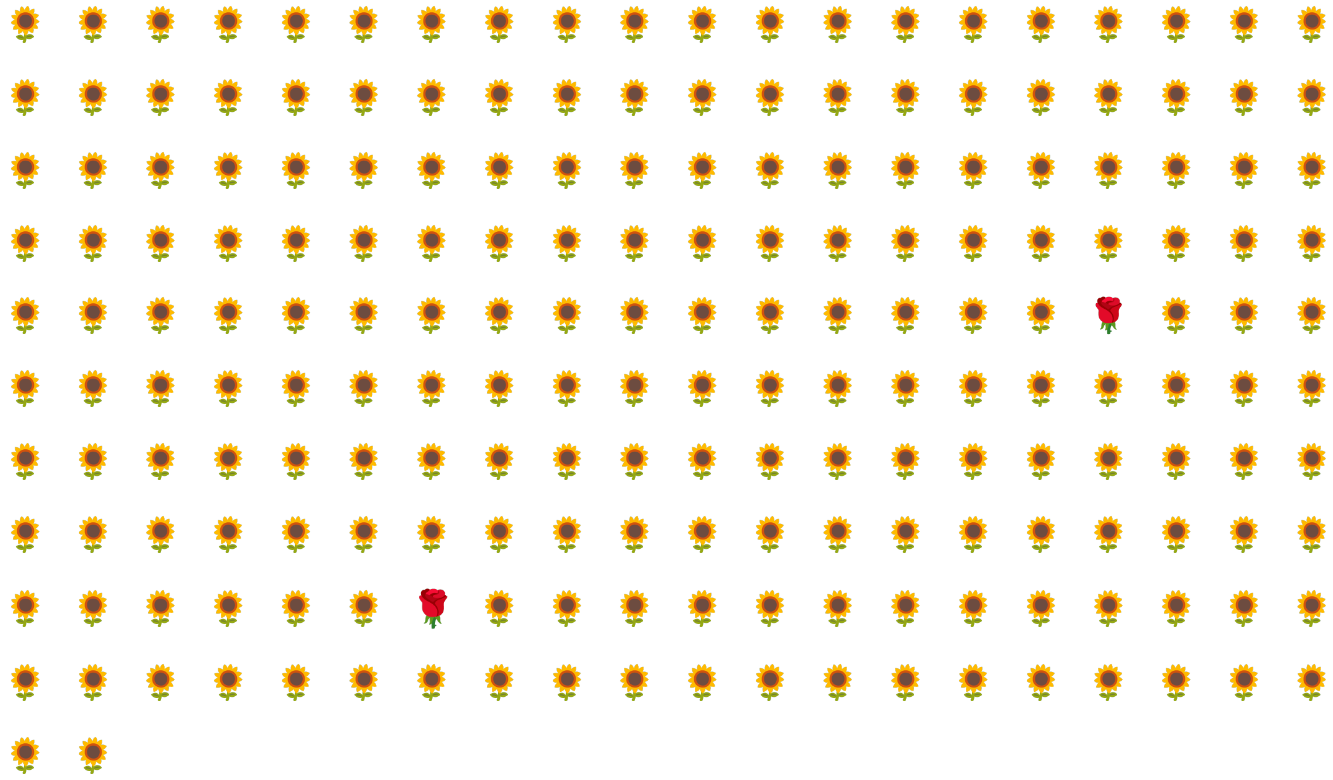
Jika ukuran batch adalah 20, sebagian besar batch tidak akan berisi contoh kelas minoritas. Jika ukuran batch adalah 100, setiap batch hanya akan berisi rata-rata satu contoh kelas minoritas, yang tidak cukup untuk pelatihan yang tepat. Bahkan ukuran batch yang jauh lebih besar akan tetap menghasilkan proporsi yang tidak seimbang sehingga model mungkin tidak dapat dilatih dengan benar.
Melatih set data kelas tidak seimbang
Selama pelatihan, model harus mempelajari dua hal:
- Seperti apa setiap kelas; yaitu, nilai fitur apa yang sesuai dengan kelas apa?
- Seberapa umum setiap class; yaitu, bagaimana distribusi relatif class?
Pelatihan standar menggabungkan kedua tujuan ini. Sebaliknya, teknik dua langkah berikut yang disebut pengurangan sampel dan peningkatan bobot kelas mayoritas memisahkan kedua tujuan ini, sehingga model dapat mencapai kedua tujuan.
Langkah 1: Kurangi sampel kelas mayoritas
Pengurangan sampel berarti melatih contoh kelas mayoritas dengan persentase rendah yang tidak proporsional. Artinya, Anda secara artifisial memaksa set data yang tidak seimbang menjadi lebih seimbang dengan menghilangkan banyak contoh kelas mayoritas dari pelatihan. Pengurangan sampel sangat meningkatkan probabilitas bahwa setiap batch berisi contoh yang cukup dari class minoritas untuk melatih model dengan benar dan efisien.
Misalnya, set data yang tidak seimbang kelas yang ditunjukkan pada Gambar 6 terdiri dari 99% contoh kelas mayoritas dan 1% contoh kelas minoritas. Mengurangi sampel kelas mayoritas dengan faktor 25 secara buatan menciptakan set pelatihan yang lebih seimbang (80% kelas mayoritas hingga 20% kelas minoritas) seperti yang ditunjukkan pada Gambar 7:

Langkah 2: Memberi bobot lebih tinggi pada kelas yang dikurangi sampelnya
Pengurangan sampel menyebabkan bias prediksi dengan menunjukkan kepada model dunia buatan yang kelasnya lebih seimbang daripada di dunia nyata. Untuk mengoreksi bias ini, Anda harus "menaikkan bobot" kelas mayoritas dengan faktor yang digunakan untuk mengurangi sampel. Menaikkan bobot berarti memperlakukan kerugian pada contoh kelas mayoritas lebih berat daripada kerugian pada contoh kelas minoritas.
Misalnya, kami melakukan downsampling pada kelas mayoritas dengan faktor 25, jadi kami harus menaikkan bobot kelas mayoritas dengan faktor 25. Artinya, saat model salah memprediksi kelas mayoritas, perlakukan kerugian seolah-olah ada 25 error (kalikan kerugian reguler dengan 25).

Seberapa banyak Anda harus melakukan downsampling dan menaikkan bobot untuk menyeimbangkan kembali set data? Untuk menentukan jawabannya, Anda harus bereksperimen dengan berbagai faktor pengurangan sampel dan peningkatan bobot seperti yang Anda lakukan saat bereksperimen dengan hyperparameter lainnya.
Manfaat teknik ini
Penurunan/pengurangan sampel dan peningkatan bobot kelas mayoritas memberikan manfaat berikut:
- Model yang lebih baik: Model yang dihasilkan "mengetahui" kedua hal berikut:
- Koneksi antara fitur dan label
- Distribusi sebenarnya dari kelas
- Konvergensi yang lebih cepat: Selama pelatihan, model melihat kelas minoritas lebih sering, yang membantu model menyatu lebih cepat.