התאמת יתר היא יצירת מודל שתואם (מזכרת) את המשפט האימון הוגדר, שהמודל לא מצליח לספק תחזיות נכונות לגבי נתונים חדשים. מודל overfit מקביל להמצאה שמניבה ביצועים טובים בשיעור ה-Lab, חסר ערך בעולם האמיתי.
באיור 11 נניח שכל צורה גאומטרית מייצגת מיקום של עץ ביער מרובע. היהלומים הכחולים מסמנים את המיקומים של עצים בריאים, והעיגולים הכתומים מסמנים את המיקומים של העצים החולים.

ציירו מבחינה מנטלית צורות - קווים, עקומות, אליפסות...כל דבר - כדי להפריד עצים בריאים מהעצים החולים. לאחר מכן, מרחיבים את השורה הבאה כדי לבדוק של הפרדה אפשרית אחת.
הרחב כדי לראות פתרון אפשרי אחד (איור 12).

הצורות המורכבות שמוצגות באיור 12 סווגו בהצלחה את כל הצורות, למעט שתיים העצים. אם נחשוב על הצורות כמודל, אז זה מדהים מודל טרנספורמר.
או שלא? מודל מעולה במיוחד מסווג דוגמאות חדשות לקטגוריות. איור 13 מראה מה קורה כאשר אותו מודל מבצע תחזיות דוגמאות מקבוצת הבדיקה:

לכן, המודל המורכב שמוצג באיור 12 עשה עבודה מצוינת בערכת האימון אבל עבודה לא טובה במבחן. זה מקרה קלאסי במודל התאמת יתר לנתונים של קבוצת האימון.
התאמה, התאמת יתר והלבשה תחתונה
המודל חייב לספק חיזויים טובים לגבי נתונים חדשים. כלומר, אתם שואפים ליצור מודל ש"מתאים" נתונים חדשים.
כמו שראיתם, מודל ללבוש חליפין מספק תחזיות מעולות להגדיר חיזויים אבל גרועים לגבי נתונים חדשים. מודל חסר לא מספק אפילו חיזויים טובים לגבי נתוני האימון. אם מודל התאמת יתר כמו מוצר שיש לו ביצועים טובים במעבדה אבל פחות טוב בעולם האמיתי, מודל הלבשה תחתונה הוא כמו מוצר שאפילו לא מצליח בשיעור ה-Lab.

הכללה היא ההפך מבחינת התאמת יתר. כלומר, מודל שמכלל היטב יוצר ויצירת חיזויים על נתונים חדשים. המטרה שלכם היא ליצור מודל שמכלל היטב לנתונים חדשים.
זיהוי התאמת יתר
העקומות הבאות עוזרות לזהות התאמת יתר:
- עקומות הפסד
- עקומות הכללה
עקומת הפסד מתארת את האובדן של המודל ביחס למספר האיטרציות של האימון. גרף שמציג שתי עקומות הפסד או יותר נקרא הכללה עקומה. הבאים עקומת ההכללה מראה שתי עקומות הפסד:
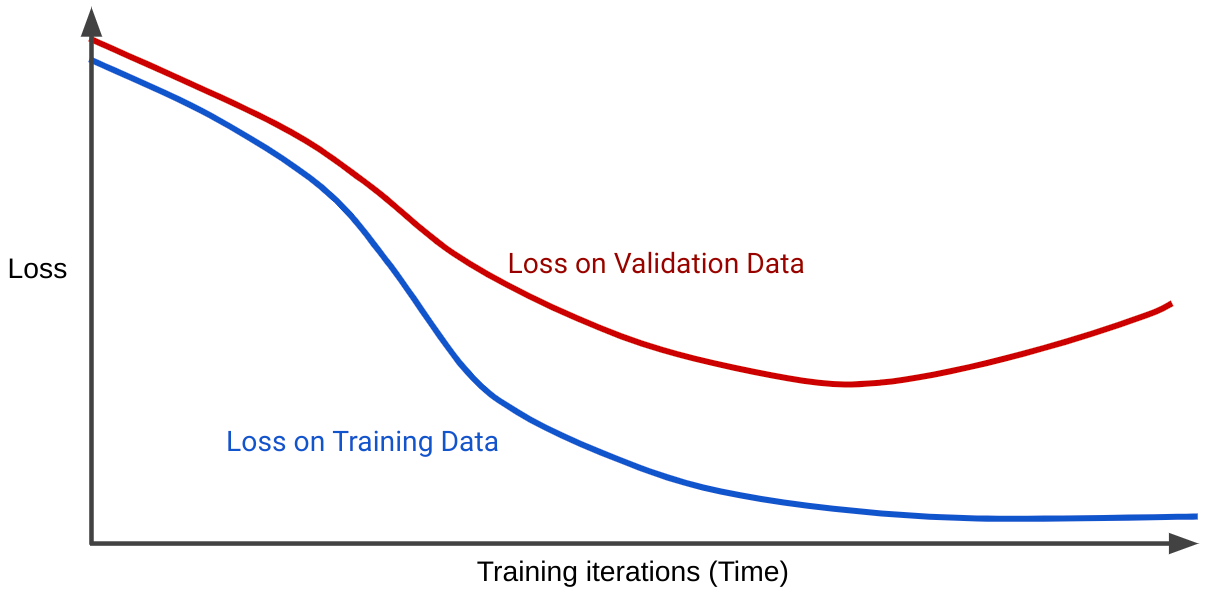
שימו לב ששתי עקומות האובדן פועלות באופן דומה בהתחלה ורק אחר כך נפרדות. כלומר, לאחר מספר מסוים של חזרות, ירידות הפסד או היא יציבה (מקפיצים) בערכת האימון, אבל עבור קבוצת האימות. זה מרמז על התאמת יתר.
לעומת זאת, עקומת הכללה של מודל בעל התאמה טובה מציגה שתי עקומות הפסד שיש להם צורות דומות.
מה גורם להתאמה יתר של המכשיר?
באופן כללי, התאמת יתר נגרמת מאחת מהסיבות הבאות או משניהם בעיות:
- ערכת האימון לא מייצגת במידה הולמת נתונים מהחיים האמיתיים קבוצת האימות או קבוצת הבדיקה).
- המודל מורכב מדי.
תנאי הכללה
מודל מתאמן על ערכת אימון, אבל המבחן האמיתי לשווי של מודל הוא הוא יוצר תחזיות לגבי דוגמאות חדשות, במיוחד לגבי נתונים מהעולם האמיתי. במהלך פיתוח המודל, ערכת הבדיקה שלכם משמשת כביטוי לנתונים מהעולם האמיתי. אימון מודל שמכלל היטב מרמז על התנאים הבאים של מערך נתונים:
- הדוגמאות חייבות להיות מופצת באופן עצמאי וזהה, וזו דרך מהודרת לומר הדוגמאות לא יכולות להשפיע זו על זו.
- מערך הנתונים הוא stationary, כלומר מערך הנתונים לא משתנה באופן משמעותי עם הזמן.
- למחיצות של מערכי הנתונים יש התפלגות זהה. כלומר, הדוגמאות בערכת האימון דומות מבחינה סטטיסטית דוגמאות בקבוצת האימות, בקבוצת הבדיקה ובנתונים מהעולם האמיתי.
נסו את התרגילים הבאים כדי ללמוד על התנאים הקודמים.
תרגילים: בדקו את ההבנה שלכם

תרגיל אתגר
אתם יוצרים מודל שחוזה את התאריך האידיאלי שבו נוסעים יקנו כרטיס רכבת למסלול מסוים. לדוגמה, המודל עשוי להמליץ שהמשתמשים קונים את הכרטיס שלהם ב-8 ביולי לרכבת שיוצאת ב-23 ביולי. חברת הרכבות מעדכנת את המחירים מדי שעה ומתבססת על העדכונים שלה של גורמים, אבל בעיקר על המספר הנוכחי של המושבים הזמינים. כלומר:
- אם יש הרבה מושבים, מחירי הכרטיסים בדרך כלל נמוכים.
- אם יש מעט מאוד מושבים זמינים, מחירי הכרטיסים בדרך כלל גבוהים.
תשובה: המודל של העולם האמיתי מתקשה באמצעות לולאת משוב.
לדוגמה, נניח שהמודל ממליץ למשתמשים לקנות כרטיסים ב-8 ביולי. חלק מהנוסעים שמשתמשים בהמלצה של המודל קונים את הכרטיסים שלהם בשעה 8:30 בבוקר ב-8 ביולי. בשעה 9:00, חברת הרכבות מעלה מחירים כי פחות מושבים זמינים עכשיו. נוסעים שמשתמשים בהמלצה של המודל קיבלו מחירים ששונו. בשעות הערב, מחירי הכרטיסים עשויים להיות גבוהים בהרבה בבוקר.