Overfitting หมายถึงการสร้างรูปแบบ ที่ตรงกับ (จดจำ) ชุดการฝึก อย่างใกล้ชิดว่าโมเดล ไม่สามารถคาดการณ์ข้อมูลใหม่ได้อย่างถูกต้อง โมเดลโอเวอร์พอลคล้ายกับสิ่งประดิษฐ์ที่มีประสิทธิภาพดีในห้องทดลอง ก็ไร้ค่าในโลกจริง
ในรูปที่ 11 สมมติว่ารูปทรงเรขาคณิตแต่ละรูปแสดงถึงตำแหน่งของต้นไม้ ในป่ารูปสี่เหลี่ยม เพชรสีฟ้าจะแสดงตำแหน่งของต้นไม้ที่มีสุขภาพดี ขณะที่วงกลมสีส้มจะระบุตำแหน่งของต้นไม้ที่ป่วย

ต้องวาดรูปร่างต่างๆ ไม่ว่าจะเป็นเส้น เส้นโค้ง วงรี หรืออะไรก็ตาม เพื่อแยกออกจาก ต้นไม้ที่มีสุขภาพดีจากต้นไม้ที่ป่วย จากนั้นขยายบรรทัดถัดไปเพื่อตรวจสอบ การแยกที่เป็นไปได้
ขยายเพื่อดูวิธีแก้ปัญหาที่เป็นไปได้ 1 วิธี (รูปที่ 12)

รูปทรงที่ซับซ้อนที่แสดงในรูปที่ 12 จัดหมวดหมู่ข้อมูลทั้งหมด ต้นไม้ ถ้าเรามองว่ารูปทรงเป็นต้นแบบ ต้องดีมากเลย โมเดล
หรืออาจจะยังมีหวังอยู่กันแน่นะ โมเดลที่ยอดเยี่ยมอย่างแท้จริงจัดหมวดหมู่ตัวอย่างใหม่ได้สำเร็จ รูปที่ 13 แสดงสิ่งที่เกิดขึ้นเมื่อโมเดลเดียวกันนั้นทำการคาดการณ์ใน ตัวอย่างจากชุดทดสอบ

ดังนั้น โมเดลที่ซับซ้อนที่แสดงในรูปที่ 12 ทำงานได้ดีในชุดการฝึก แต่ทำได้ไม่ดีพอในชุดการทดสอบ นี่เป็นกรณีคลาสสิกของโมเดล ปรับมากเกินไปให้กับข้อมูลชุดการฝึก
การปรับให้พอดี การตัดมากเกินไป และการตัดให้พอดี
โมเดลต้องคาดการณ์ข้อมูลใหม่ได้ดี กล่าวคือ คุณตั้งเป้าที่จะสร้างโมเดลที่ "เหมาะสม" ข้อมูลใหม่
จากที่เห็น โมเดลโอเวอร์ฟิตคาดการณ์ได้อย่างดีเยี่ยมในการฝึก ตั้งค่าแต่มีการคาดการณ์ได้ไม่ดีในข้อมูลใหม่ CANNOT TRANSLATE รูปแบบชุดชั้นใน ไม่ได้คาดการณ์ข้อมูลการฝึกได้ดี หากรูปแบบโอเวอร์เอนด์คือ เช่น ผลิตภัณฑ์ที่มีประสิทธิภาพดีในห้องทดลอง แต่ไม่ดีในโลกแห่งความเป็นจริง แบบที่ใส่เสื้อผ้าต่ำกว่าเกณฑ์ก็เหมือนผลิตภัณฑ์ ที่ประสิทธิภาพไม่ดี Lab

การจำแนกประเภทคือ ตรงข้ามกับการปรับมากเกินไป กล่าวคือ โมเดลที่มีความครอบคลุมดีจะทำให้ดี การคาดคะเนเกี่ยวกับข้อมูลใหม่ เป้าหมายของคุณคือการสร้างโมเดลที่ทำให้ทุกคนเข้าใจ กับข้อมูลใหม่
กำลังตรวจจับเกินขนาด
เส้นโค้งต่อไปนี้จะช่วยให้คุณตรวจพบความพอดีที่มากเกินไป
- กราฟแบบสูญเสียบางส่วน
- เส้นโค้งทั่วไป
กราฟ Loss แสดงการสูญเสียของโมเดล กับจำนวนการทำซ้ำการฝึก กราฟที่แสดงเส้นโค้งการสูญเสียตั้งแต่ 2 เส้นขึ้นไปเรียกว่าการอ้างอิงทั่วไป เส้นโค้ง ดังต่อไปนี้ เส้นโค้งทั่วไปแสดงเส้นโค้งการสูญเสีย 2 เส้น ได้แก่
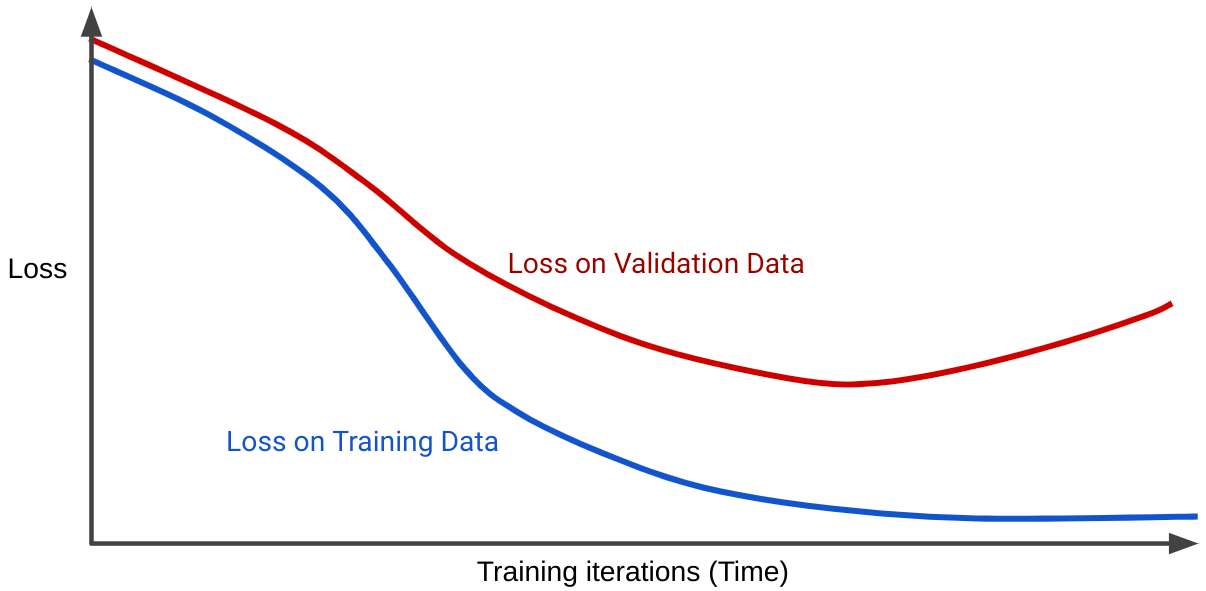
โปรดสังเกตว่าเส้นโค้งการสูญเสียทั้ง 2 เส้นโค้งทำงานคล้ายกันในตอนแรก จากนั้นจะเบี่ยงเบนกัน กล่าวคือ หลังจากมีการปรับปรุงแก้ไข ลดลง หรือ คง (รูปแบบ) ของชุดการฝึก แต่เพิ่มขึ้น สำหรับชุดการตรวจสอบ ซึ่งหมายถึงการปรับมากเกินไป
ในทางตรงกันข้าม เส้นโค้งการสรุปโดยทั่วไปสำหรับโมเดลที่เหมาะสมจะแสดงเส้นโค้งการสูญเสีย 2 เส้น ที่มีรูปทรงคล้ายกัน
อะไรเป็นสาเหตุของการปรับมากเกินไป
กล่าวอย่างกว้างๆ ก็คือ การปรับมากเกินไปอาจเกิดจากสาเหตุหนึ่งหรือทั้ง 2 อย่างต่อไปนี้ ปัญหา:
- ชุดการฝึกไม่ได้แสดงข้อมูลในชีวิตจริงอย่างเพียงพอ (หรือ ชุดการตรวจสอบหรือชุดทดสอบ)
- โมเดลซับซ้อนเกินไป
เงื่อนไขทั่วไป
โมเดลจะฝึกในชุดการฝึก แต่การทดสอบจริงๆ ของคุณค่าของโมเดลคือ ทำให้สามารถคาดการณ์ตัวอย่างใหม่ๆ โดยเฉพาะข้อมูลในชีวิตจริง ขณะพัฒนาโมเดล ชุดทดสอบของคุณทำหน้าที่เป็นพร็อกซีสำหรับข้อมูลจริง การฝึกโมเดลที่รวมโดยทั่วไปจะสื่อถึงเงื่อนไขชุดข้อมูลต่อไปนี้
- ตัวอย่างต้องเป็น เผยแพร่โดยอิสระและเหมือนกันทุกประการ ซึ่งเป็นวิธีพูดที่งดงามในการบอกว่า ตัวอย่างต่างๆ จะไม่สามารถโน้มน้าวกัน
- ชุดข้อมูลคือ คงที่ ซึ่งหมายความว่า จะไม่มีการเปลี่ยนแปลงอย่างมีนัยสำคัญเมื่อเวลาผ่านไป
- พาร์ติชันชุดข้อมูลมีการกระจายเดียวกัน กล่าวคือ ตัวอย่างในชุดการฝึกมีสถิติคล้ายคลึงกับ ตัวอย่างในชุดการตรวจสอบ ชุดทดสอบ และข้อมูลการใช้งานจริง
ศึกษาสภาวะก่อนหน้านี้ผ่านแบบฝึกหัดต่อไปนี้
แบบฝึกหัด: ตรวจสอบความเข้าใจ

การออกกำลังกายแบบชาเลนจ์
คุณกำลังสร้างโมเดลที่คาดการณ์วันไหนที่เหมาะที่สุดสำหรับไรเดอร์ ตั๋วรถไฟสำหรับเส้นทางนั้นๆ โดยเฉพาะ ตัวอย่างเช่น โมเดลอาจแนะนำ ที่ผู้ใช้ซื้อตั๋วในวันที่ 8 กรกฎาคมสำหรับรถไฟที่ออกเดินทางวันที่ 23 กรกฎาคม บริษัทรถไฟจะอัปเดตราคาเป็นรายชั่วโมงตามข้อมูลอัปเดตจากปัจจัยต่างๆ แต่จะขึ้นอยู่กับจำนวน ที่นั่งว่างในปัจจุบันเป็นหลัก โดยการ
- หากมีที่นั่งจำนวนมาก โดยปกติแล้วราคาตั๋วจะต่ำกว่านี้
- โดยปกติแล้ว หากมีที่นั่งน้อยเกินไป ราคาตั๋วก็จะสูง
เฉลย: โมเดลในชีวิตจริงกำลังมีปัญหากับ ลูปความคิดเห็น
ตัวอย่างเช่น สมมติว่าโมเดลแนะนำให้ผู้ใช้ซื้อตั๋วในวันที่ 8 กรกฎาคม นักแข่งบางคนที่ใช้คำแนะนำของโมเดลนี้ซื้อตั๋วเวลา 08:30 น. ในช่วงเช้าของวันที่ 8 กรกฎาคม ในเวลา 9:00 น. บริษัทรถไฟขึ้นราคาเพราะ เหลือที่นั่งน้อยลงแล้ว นักขี่ที่ใช้การแนะนำของโมเดลมี ราคาที่ถูกปรับเปลี่ยน ในตอนเย็น ราคาตั๋วอาจสูงกว่า ตอนเช้า