أنظمة تعلُّم الآلة للإنتاج: الاستنتاج الثابت مقابل الاستنتاج الديناميكي
تنظيم صفحاتك في مجموعات
يمكنك حفظ المحتوى وتصنيفه حسب إعداداتك المفضّلة.
الاستنتاج هو عملية
إجراء تنبؤات من خلال تطبيق نموذج مدرَّب على
أمثلة غير مصنّفة.
بشكل عام، يمكن للنموذج استنتاج التوقّعات بإحدى الطريقتَين التاليتَين:
النمذجة الثابتة (المعروفة أيضًا باسم النمذجة بلا إنترنت أو
النمذجة المجمّعة) تعني أنّ النموذج يقدّم توقّعات بشأن مجموعة من
الأمثلة غير المصنّفة
ثم يخزّن هذه التوقّعات في مكان ما.
الاستنتاج الديناميكي (يُعرف أيضًا باسم الاستنتاج على الإنترنت أو
الاستنتاج في الوقت الفعلي) يعني أنّ النموذج لا يضع توقّعات إلا عند الطلب،
مثلاً عندما يطلب العميل توقّعات.
ولنوضّح ذلك، لنفترض أنّ هناك نموذجًا معقّدًا للغاية يحتاج إلى ساعة واحدة لاستنتاج توقّع.
قد يكون هذا مثالاً ممتازًا للاستنتاج الثابت:
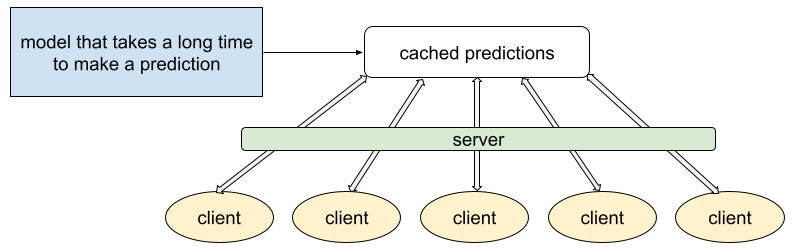
الشكل 4. في الاستنتاج الثابت، ينشئ النموذج توقّعات،
ويتم تخزينها مؤقتًا على خادم.
لنفترض أنّ هذا النموذج المعقّد نفسه يستخدم عن طريق الخطأ الاستنتاج الديناميكي بدلاً من
الاستنتاج الثابت. إذا طلب العديد من العملاء توقّعات في الوقت نفسه تقريبًا، لن يتلقّى معظمهم هذه التوقّعات لعدّة ساعات أو أيام.
لنفترض الآن أنّ هناك نموذجًا يستنتج المعلومات بسرعة، ربما في مليсекتَين باستخدام
الحد الأدنى النسبي للموارد الحسابية. في هذه الحالة، يمكن للعملاء
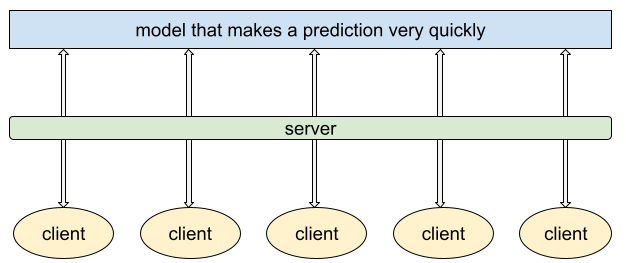
تلقّي التوقّعات بسرعة وكفاءة من خلال الاستنتاج الديناميكي، كما هو موضح في الشكل 5.
الشكل 5. في الاستنتاج الديناميكي، يستنتج النموذج التوقّعات عند الطلب.
الاستنتاج الثابت
توفّر الاستنتاج الثابت مزايا وعيوبًا معيّنة.
المزايا
لا داعي للقلق كثيرًا بشأن تكلفة الاستنتاج.
يمكن إجراء عملية التحقّق من التوقّعات بعد إرسالها.
السلبيات
يمكن عرض التوقّعات المخزّنة مؤقتًا فقط، لذا قد لا يكون النظام قادرًا على
عرض توقّعات لأمثلة الإدخال غير الشائعة.
من المرجّح أن يتم قياس وقت استجابة التعديل بالساعات أو الأيام.
الاستنتاج الديناميكي
توفّر الاستنتاج الديناميكي مزايا وعيوبًا معيّنة.
المزايا
يمكنه استنتاج توقّع بشأن أي عنصر جديد عند وصوله، ما
يُعدّ أمرًا رائعًا للتوقّعات المتعلقة بالعناصر الأقل شيوعًا.
السلبيات
تتطلّب معالجة مكثفة وتستجيب ببطء للطلبات. قد يحدّ هذا المزيج من
تعقيد النموذج، أي أنّه قد يكون عليك إنشاء نموذج أبسط يمكنه
استنتاج التوقّعات بشكل أسرع من النموذج المعقّد.
احتياجات المراقبة أكثر كثافة.
تمارين: التحقّق من فهمك
أي ثلاثة من العبارات الأربعة التالية هي
صحيحة بشأن الاستنتاج الثابت؟
يجب أن يُنشئ النموذج توقّعات لجميع المدخلات المحتمَلة.
نعم، يجب أن يقدّم النموذج توقّعات لجميع المدخلات المحتملة ويحفظها في ذاكرة تخزين مؤقت أو جدول بحث.
إذا كانت مجموعة الأشياء التي يتوقّع النموذج حدوثها محدودة، قد يكون
الاستنتاج الثابت خيارًا جيدًا.
ومع ذلك، بالنسبة إلى الإدخالات الحرة الشكل، مثل طلبات بحث المستخدمين التي تحتوي على
قائمة طويلة من العناصر غير المعتادة أو النادرة، لا يمكن للاستنتاج الثابت أن يوفّر coverage
كاملة.
يمكن للنظام التحقّق من التوقّعات المستنتَجة قبل عرضها.
نعم، هذا جانب مفيد من الاستنتاج الثابت.
بالنسبة إلى إدخال معيّن، يمكن للنموذج تقديم توقّع بشكل أسرع
من الاستنتاج الديناميكي.
نعم، يمكن أن تقدّم الاستنتاجات الثابتة في معظم الأحيان توقّعات بشكل أسرع
من الاستنتاجات الديناميكية.
يمكنك الاستجابة بسرعة للتغييرات في العالم.
لا، هذا عيب في الاستنتاج الثابت.
أي عبارة من العبارات التالية هي
صحيحة بشأن الاستنتاج الديناميكي؟
يمكنك تقديم توقّعات لجميع العناصر المحتمَلة.
نعم، هذه هي إحدى نقاط قوة الاستنتاج الديناميكي. سيتم منح أي طلب
يصل إلى حسابك نتيجة. تعالج الاستنتاجات الديناميكية توزيعات
الذيل الطويل (تلك التي تحتوي على العديد من العناصر النادرة)، مثل مساحة كل
الجمل المحتمَلة المكتوبة في مراجعات الأفلام.
يمكنك التحقّق من التنبؤات بعد إنشائها قبل
استخدامها.
بشكل عام، لا يمكن إجراء عملية التحقّق من كل التوقعات بعد إجرائها قبل استخدامها لأنّه يتم إجراء التوقعات عند الطلب. ومع ذلك، يمكنك مراقبة القيم الإجمالية للتوقّعات من أجل توفير مستوى معيّن من التحقّق من الجودة، ولكنّ هذه القيم لن تُرسل إنذارات الحريق إلا بعد أن ينتشر الحريق.
عند إجراء الاستنتاج الديناميكي، لا داعي للقلق
بشأن وقت استجابة التوقّعات (وقت التأخير لعرض التوقّعات)
بقدر ما هو عليه الحال عند إجراء الاستنتاج الثابت.
غالبًا ما يكون وقت استجابة التوقّعات مصدر قلق حقيقي في الاستنتاج الديناميكي.
لا يمكنك بالضرورة حلّ مشاكل وقت استجابة التوقّعات
من خلال إضافة المزيد من خوادم الاستنتاج.