Después de examinar tus datos con técnicas estadísticas y de visualización, debes transformarlos de manera que ayuden a tu modelo a entrenarse de forma más eficaz. El objetivo de la normalización es transformar las características para que estén en una escala similar. Por ejemplo, considera los siguientes dos atributos:
- La columna
Xabarca el rango de 154 a 24,917,482. - El atributo
Yabarca el rango de 5 a 22.
Estas dos características abarcan rangos muy diferentes. La normalización podría manipular X y Y para que abarquen un rango similar, tal vez de 0 a 1.
La normalización proporciona los siguientes beneficios:
- Ayuda a que los modelos converjan más rápido durante el entrenamiento. Cuando las diferentes funciones tienen rangos diferentes, el descenso del gradiente puede "rebotar" y ralentizar la convergencia. Dicho esto, los optimizadores más avanzados, como Adagrad y Adam, protegen contra este problema cambiando la tasa de aprendizaje efectiva con el tiempo.
- Ayuda a los modelos a inferir mejores predicciones. Cuando las diferentes características tienen rangos diferentes, el modelo resultante podría generar predicciones algo menos útiles.
- Ayuda a evitar la "trampa de NaN" cuando los valores de las características son muy altos.
NaN es la abreviatura de no es un número. Cuando un valor de un modelo supera el límite de precisión de punto flotante, el sistema establece el valor en
NaNen lugar de un número. Cuando un número del modelo se convierte en NaN, otros números del modelo también se convierten en NaN. - Ayuda al modelo a aprender los pesos adecuados para cada atributo. Sin el ajuste de atributos, el modelo les presta demasiada atención a los atributos con rangos amplios y no les presta suficiente atención a los atributos con rangos estrechos.
Recomendamos normalizar los atributos numéricos que abarcan rangos claramente diferentes (por ejemplo, edad e ingresos).
También recomendamos normalizar un solo atributo numérico que abarque un amplio rango, como city population..
Considera los siguientes dos atributos:
- El valor más bajo de la variable
Aes -0.5 y el más alto es +0.5. - El valor más bajo de la función
Bes -5.0 y el más alto es +5.0.
Las funciones A y B tienen rangos relativamente estrechos. Sin embargo, el intervalo de la función B es 10 veces más amplio que el de la función A. Por lo tanto:
- Al comienzo del entrenamiento, el modelo supone que el atributo
Bes diez veces más "importante" que el atributoA. - El entrenamiento tardará más de lo que debería.
- El modelo resultante puede ser deficiente.
El daño general por no normalizar será relativamente pequeño. Sin embargo, recomendamos normalizar la función A y la función B en la misma escala, tal vez de -1.0 a +1.0.
Ahora, considera dos atributos con una mayor disparidad de rangos:
- El valor más bajo de la función
Ces -1 y el más alto es +1. - El valor más bajo de la función
Des +5,000 y el más alto es +1,000,000,000.
Si no normalizas el atributo C y el atributo D, es probable que tu modelo no sea óptimo. Además, el entrenamiento tardará mucho más en converger o incluso no podrá hacerlo.
En esta sección, se describen tres métodos de normalización populares:
- Escalamiento lineal
- Ajuste de la puntuación Z
- Escalamiento logarítmico
En esta sección, también se explica el recorte. Si bien no es una verdadera técnica de normalización, el recorte sí controla los atributos numéricos no controlados en rangos que producen mejores modelos.
Escalamiento lineal
El escalamiento lineal (más comúnmente abreviado como escalamiento) significa convertir los valores de punto flotante de su rango natural a un rango estándar, generalmente de 0 a 1 o de -1 a +1.
El ajuste de escala lineal es una buena opción cuando se cumplen todas las siguientes condiciones:
- Los límites inferior y superior de tus datos no cambian mucho con el tiempo.
- La función contiene pocos valores atípicos o ninguno, y estos no son extremos.
- La función se distribuye de forma aproximadamente uniforme en su rango. Es decir, un histograma mostraría barras casi uniformes para la mayoría de los valores.
Supongamos que el ser humano age es un atributo. El ajuste lineal es una buena técnica de normalización para age porque:
- Los límites inferior y superior aproximados son de 0 a 100.
agecontiene un porcentaje relativamente pequeño de valores atípicos. Solo alrededor del 0.3% de la población tiene más de 100 años.- Si bien ciertas edades están algo mejor representadas que otras, un conjunto de datos grande debería contener suficientes ejemplos de todas las edades.
Ejercicio: Comprueba tus conocimientos
Supongamos que tu modelo tiene un atributo llamadonet_worth que contiene el patrimonio neto de diferentes personas. ¿El ajuste lineal sería una buena técnica de normalización para net_worth? ¿Por qué?
Ajuste de la puntuación Z
Una puntuación Z es la cantidad de desviaciones estándar que tiene un valor a partir de la media. Por ejemplo, un valor que es 2 desviaciones estándar mayor que la media tiene una puntuación Z de +2.0. Un valor que es 1.5 desviaciones estándar menor que la media tiene una puntuación Z de -1.5.
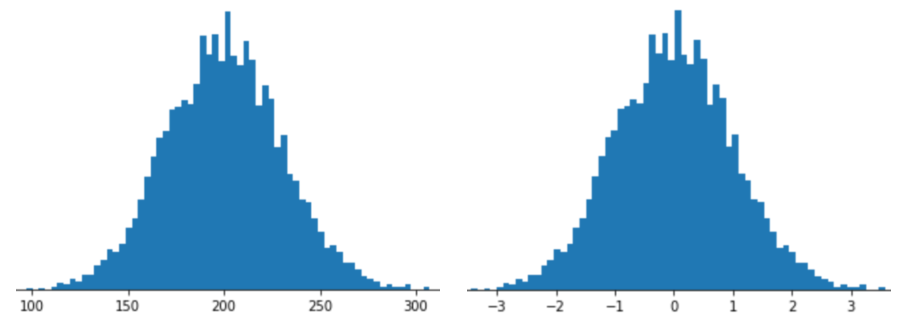
Representar un atributo con el ajuste de escala de Z-score significa almacenar el Z-score de ese atributo en el vector de atributos. Por ejemplo, en la siguiente figura, se muestran dos histogramas:
- A la izquierda, una distribución normal clásica.
- A la derecha, se muestra la misma distribución normalizada con el escalamiento de la puntuación Z.
El ajuste de la puntuación Z también es una buena opción para los datos como los que se muestran en la siguiente figura, que solo tienen una distribución vagamente normal.
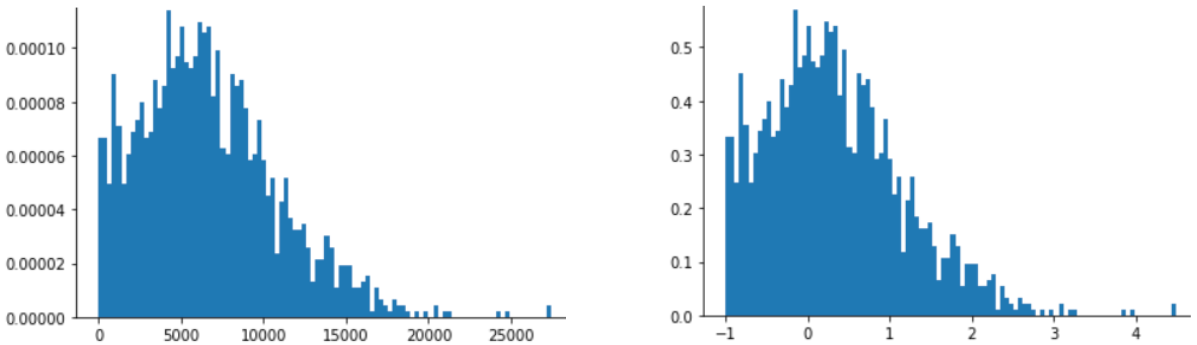
La puntuación Z es una buena opción cuando los datos siguen una distribución normal o una distribución algo similar a una distribución normal.
Ten en cuenta que algunas distribuciones pueden ser normales dentro de la mayor parte de su rango, pero aun así contener valores atípicos extremos. Por ejemplo, casi todos los puntos de un atributo net_worth podrían ajustarse perfectamente a 3 desviaciones estándares, pero algunos ejemplos de este atributo podrían estar a cientos de desviaciones estándares de la media. En estas situaciones, puedes combinar el ajuste de la puntuación Z con otra forma de normalización (por lo general, el recorte) para controlar esta situación.
Ejercicio: Comprueba tus conocimientos
Supongamos que tu modelo se entrena con un atributo llamadoheight que contiene las alturas de diez millones de mujeres adultas. ¿El escalamiento de la puntuación Z sería una buena técnica de normalización para height? ¿Por qué?
Escalamiento logarítmico
El ajuste de escala logarítmica calcula el logaritmo del valor sin procesar. En teoría, el logaritmo podría tener cualquier base; en la práctica, el ajuste logarítmico suele calcular el logaritmo natural (ln).
El ajuste de escala logarítmica es útil cuando los datos se ajustan a una distribución de ley de potencias. En términos generales, una distribución de ley de potencias se ve de la siguiente manera:
- Los valores bajos de
Xtienen valores muy altos deY. - A medida que aumentan los valores de
X, los valores deYdisminuyen rápidamente. Por lo tanto, los valores altos deXtienen valores muy bajos deY.
Las calificaciones de películas son un buen ejemplo de una distribución de ley de potencias. En la siguiente figura, observa lo siguiente:
- Algunas películas tienen muchas calificaciones de los usuarios. (Los valores bajos de
Xtienen valores altos deY). - La mayoría de las películas tienen muy pocas calificaciones de los usuarios. (Los valores altos de
Xtienen valores bajos deY).
El ajuste de escala logarítmica cambia la distribución, lo que ayuda a entrenar un modelo que realizará mejores predicciones.

Como segundo ejemplo, las ventas de libros se ajustan a una distribución de ley de potencias por los siguientes motivos:
- La mayoría de los libros publicados venden una cantidad muy pequeña de copias, tal vez entre cien y doscientas.
- Algunos libros venden una cantidad moderada de copias, de a miles.
- Solo unos pocos éxitos de ventas venderán más de un millón de copias.
Supongamos que estás entrenando un modelo lineal para encontrar la relación entre, por ejemplo, las portadas de los libros y las ventas de libros. Un modelo lineal que se entrena con valores sin procesar tendría que encontrar algo sobre las portadas de los libros que venden un millón de copias que sea 10,000 veces más potente que las portadas de los libros que venden solo 100 copias. Sin embargo, escalar todos los datos de ventas con un logaritmo hace que la tarea sea mucho más factible. Por ejemplo, el logaritmo de 100 es el siguiente:
~4.6 = ln(100)
mientras que el logaritmo de 1,000,000 es el siguiente:
~13.8 = ln(1,000,000)
Por lo tanto, el logaritmo de 1,000,000 es solo tres veces mayor que el logaritmo de 100. Probablemente podrías imaginar que la portada de un libro éxito de ventas es tres veces más potente (de alguna manera) que la portada de un libro que se vende poco.
Recorte
El recorte es una técnica para minimizar la influencia de los valores atípicos extremos. En resumen, el recorte suele limitar (reducir) el valor de los valores atípicos a un valor máximo específico. El recorte es una idea extraña y, sin embargo, puede ser muy eficaz.
Por ejemplo, imagina un conjunto de datos que contiene un atributo llamado roomsPerPerson, que representa la cantidad de habitaciones (habitaciones totales divididas por la cantidad de ocupantes) de varias casas. En el siguiente gráfico, se muestra que más del 99% de los valores de los atributos se ajustan a una distribución normal (aproximadamente, una media de 1.8 y una desviación estándar de 0.7). Sin embargo, la función contiene algunos valores atípicos, algunos de ellos extremos:
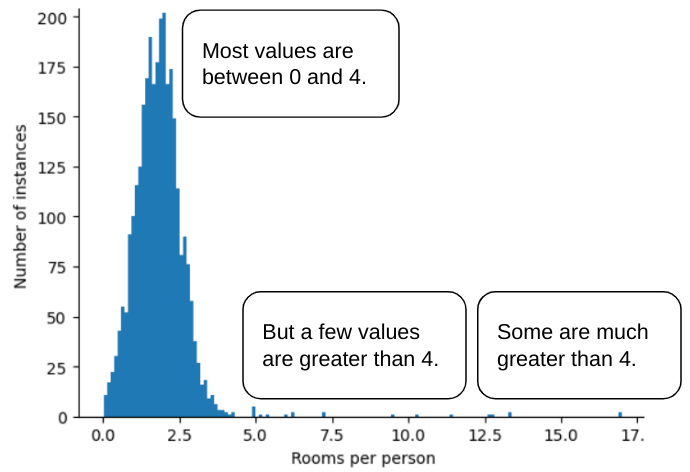
¿Cómo puedes minimizar la influencia de esos valores atípicos extremos? Bueno, el histograma no es una distribución uniforme, una distribución normal ni una distribución de ley de potencia. ¿Qué sucede si simplemente limitas o recortas el valor máximo de roomsPerPerson en un valor arbitrario, por ejemplo, 4.0?
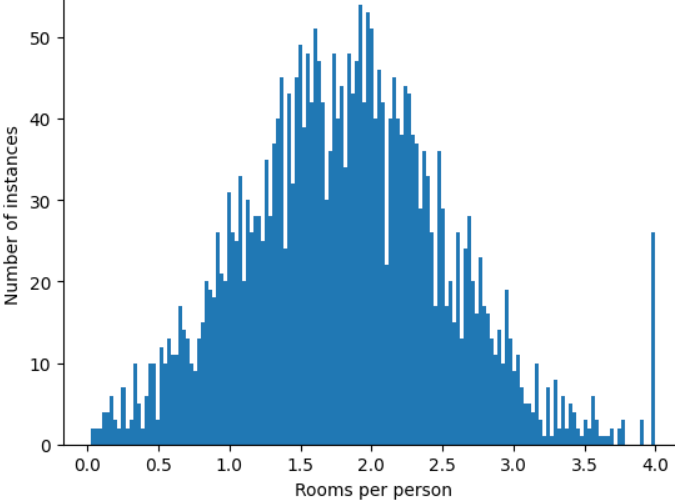
Recortar el valor del atributo en 4.0 no significa que tu modelo ignore todos los valores superiores a 4.0. Más bien, significa que todos los valores que eran mayores que 4.0 ahora se convierten en 4.0. Esto explica la peculiar colina en 4.0. A pesar de esa colina, el conjunto de funciones ajustado ahora es más útil que los datos originales.
¡Espera un segundo! ¿Realmente puedes reducir cada valor atípico a un umbral superior arbitrario? Sí, cuando entrenas un modelo.
También puedes recortar valores después de aplicar otras formas de normalización. Por ejemplo, supongamos que usas el ajuste de escala de la puntuación Z, pero algunos valores atípicos tienen valores absolutos mucho mayores que 3. En este caso, puedes hacer lo siguiente:
- Recorta las puntuaciones Z mayores que 3 para que sean exactamente 3.
- Recorta las puntuaciones Z inferiores a -3 para que sean exactamente -3.
El recorte evita que tu modelo se sobreindexe en datos sin importancia. Sin embargo, algunos valores atípicos son importantes, por lo que debes recortar los valores con cuidado.
Resumen de las técnicas de normalización
| Técnica de normalización | Formula | Cuándo debe utilizarse |
|---|---|---|
| Escalamiento lineal | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | Cuando la característica se distribuye de manera casi uniforme en todo el rango. Forma plana |
| Ajuste de la puntuación Z | $$ x' = \frac{x - μ}{σ}$$ | Cuando la característica se distribuye de forma normal (pico cerca de la media). Con forma de campana |
| Escalamiento logarítmico | $$ x' = log(x)$$ | Cuando la distribución de la característica está muy sesgada en al menos uno de los lados de la cola. Forma de cola pesada |
| Recorte | Si $x > max$, establece $x' = max$ Si $x < min$, establece $x' = min$ |
Cuando el atributo contiene valores atípicos extremos |
Ejercicio: Pon a prueba tus conocimientos
Supongamos que estás desarrollando un modelo que predice la productividad de un centro de datos en función de la temperatura medida en su interior.
Casi todos los valores de temperature en tu conjunto de datos se encuentran entre 15 y 30 (Celsius), con las siguientes excepciones:
- Una o dos veces al año, en días extremadamente calurosos, se registran algunos valores entre 31 y 45 en
temperature. - Cada punto 1,000 en
temperaturese establece en 1,000 en lugar de la temperatura real.
¿Cuál sería una técnica de normalización razonable para temperature?
Los valores de 1,000 son errores y se deben borrar en lugar de recortar.
Los valores entre 31 y 45 son datos legítimos. Probablemente, sería una buena idea recortar estos valores, suponiendo que el conjunto de datos no contiene suficientes ejemplos en este rango de temperatura para entrenar el modelo y que realice buenas predicciones. Sin embargo, durante la inferencia, ten en cuenta que el modelo recortado haría la misma predicción para una temperatura de 45 que para una de 35.