หลังจากตรวจสอบข้อมูลผ่านเทคนิคทางสถิติและการแสดงภาพแล้ว คุณควรเปลี่ยนรูปแบบข้อมูลในลักษณะที่จะช่วยให้โมเดลฝึกได้มีประสิทธิภาพมากขึ้น เป้าหมายของการปรับให้เป็นมาตรฐานคือการเปลี่ยนรูปแบบฟีเจอร์ให้มีขนาดใกล้เคียงกัน ตัวอย่างเช่น ลองพิจารณาฟีเจอร์ 2 อย่างต่อไปนี้
- ฟีเจอร์
Xครอบคลุมช่วง 154 ถึง 24,917,482 - ฟีเจอร์
Yครอบคลุมช่วง 5 ถึง 22
ฟีเจอร์ทั้ง 2 นี้ครอบคลุมช่วงที่แตกต่างกันมาก การปรับให้เป็นมาตรฐานอาจจัดการกับ
X และ Y เพื่อให้ครอบคลุมช่วงที่คล้ายกัน เช่น 0 ถึง 1
การแปลงเป็นรูปแบบมาตรฐานมีประโยชน์ดังนี้
- ช่วยให้โมเดลบรรจบกันได้เร็วขึ้นระหว่างการฝึก เมื่อฟีเจอร์ต่างๆ มีช่วงที่แตกต่างกัน การไล่ระดับการไล่ระดับอาจ "ดีด" และทำให้การบรรจบช้าลง อย่างไรก็ตาม ตัวเพิ่มประสิทธิภาพขั้นสูงกว่า เช่น Adagrad และ Adam จะป้องกันปัญหานี้โดย เปลี่ยนอัตราการเรียนรู้ที่มีประสิทธิภาพเมื่อเวลาผ่านไป
- ช่วยให้โมเดลอนุมานการคาดการณ์ได้ดียิ่งขึ้น เมื่อฟีเจอร์ต่างๆ มีช่วงที่แตกต่างกัน โมเดลที่ได้อาจทําให้การคาดการณ์มีประโยชน์น้อยลง
- ช่วยหลีกเลี่ยง "NaN Trap" เมื่อค่าฟีเจอร์สูงมาก
NaN เป็นตัวย่อของ
ไม่ใช่ตัวเลข เมื่อค่าในโมเดลเกินขีดจำกัดความแม่นยำของจุดลอย ระบบจะตั้งค่าเป็น
NaNแทนที่จะเป็นตัวเลข เมื่อตัวเลข 1 ตัวในโมเดลกลายเป็น NaN ตัวเลขอื่นๆ ในโมเดลก็จะกลายเป็น NaN ในที่สุด - ช่วยให้โมเดลเรียนรู้น้ำหนักที่เหมาะสมสำหรับแต่ละฟีเจอร์ หากไม่มีการปรับขนาดฟีเจอร์ โมเดลจะให้ความสนใจกับฟีเจอร์ที่มีช่วงกว้างมากเกินไป และให้ความสนใจกับฟีเจอร์ที่มีช่วงแคบไม่เพียงพอ
เราขอแนะนำให้ปรับฟีเจอร์ที่เป็นตัวเลขซึ่งครอบคลุมช่วงที่แตกต่างกันอย่างชัดเจน (เช่น อายุและรายได้) ให้เป็นมาตรฐาน
นอกจากนี้ เราขอแนะนำให้ปรับฟีเจอร์ตัวเลขเดียวที่ครอบคลุมช่วงกว้าง เช่น city population.
ลองพิจารณาฟีเจอร์ 2 อย่างต่อไปนี้
- ค่าต่ำสุดของฟีเจอร์
Aคือ -0.5 และค่าสูงสุดคือ +0.5 - ค่าต่ำสุดของฟีเจอร์
Bคือ -5.0 และค่าสูงสุดคือ +5.0
ฟีเจอร์ A และฟีเจอร์ B มีช่วงที่ค่อนข้างแคบ อย่างไรก็ตาม ช่วงของฟีเจอร์ B กว้างกว่าช่วงของฟีเจอร์ A 10 เท่า ดังนั้น
- เมื่อเริ่มการฝึก โมเดลจะถือว่าฟีเจอร์
B"สำคัญ" กว่าฟีเจอร์A10 เท่า - การฝึกจะใช้เวลานานกว่าที่ควร
- โมเดลที่ได้อาจไม่ดีเท่าที่ควร
ความเสียหายโดยรวมที่เกิดจากการไม่ปรับให้เป็นมาตรฐานจะค่อนข้างน้อย อย่างไรก็ตาม เรายังคงแนะนําให้ปรับฟีเจอร์ ก. และฟีเจอร์ ข. ให้เป็นมาตรฐานในระดับเดียวกัน อาจเป็น -1.0 ถึง +1.0
ตอนนี้ลองพิจารณาฟีเจอร์ 2 รายการที่มีช่วงแตกต่างกันมากขึ้น
- ค่าต่ำสุดของฟีเจอร์
Cคือ -1 และค่าสูงสุดคือ +1 - ค่าต่ำสุดของฟีเจอร์
Dคือ +5000 และค่าสูงสุดคือ +1,000,000,000
หากไม่ได้ทำให้ฟีเจอร์ C และฟีเจอร์ D เป็นมาตรฐาน โมเดลของคุณอาจทำงานได้ไม่ดีเท่าที่ควร
นอกจากนี้ การฝึกยังใช้เวลานานกว่ามากในการ
รวมกัน หรืออาจรวมกันไม่สำเร็จเลยก็ได้
ส่วนนี้จะครอบคลุมวิธีการปรับให้เป็นมาตรฐาน 3 วิธีที่นิยมใช้กัน
- การปรับขนาดเชิงเส้น
- การปรับขนาดคะแนนมาตรฐาน (Z-Score)
- การปรับขนาดบันทึก
นอกจากนี้ ส่วนนี้ยังครอบคลุมถึงการตัด แม้ว่าการตัดค่าจะไม่ใช่เทคนิคการปรับให้เป็นมาตรฐานที่แท้จริง แต่ก็ช่วยให้ฟีเจอร์ตัวเลขที่ควบคุมยากอยู่ในช่วงที่สร้างโมเดลได้ดีขึ้น
การปรับสเกลเชิงเส้น
การปรับสเกลเชิงเส้น (โดยทั่วไปมักย่อเป็นการปรับสเกล) หมายถึงการแปลงค่าทศนิยมจากช่วงปกติเป็นช่วงมาตรฐาน ซึ่งมักจะเป็น 0 ถึง 1 หรือ -1 ถึง +1
การปรับขนาดเชิงเส้นเป็นตัวเลือกที่ดีเมื่อเป็นไปตามเงื่อนไขต่อไปนี้ทั้งหมด
- ขอบเขตล่างและขอบเขตบนของข้อมูลไม่เปลี่ยนแปลงมากนักเมื่อเวลาผ่านไป
- ฟีเจอร์มีค่าผิดปกติเพียงเล็กน้อยหรือไม่มีเลย และค่าผิดปกติเหล่านั้นไม่ รุนแรง
- ฟีเจอร์นี้มีการกระจายอย่างสม่ำเสมอโดยประมาณในขอบเขตของฟีเจอร์ กล่าวคือ ฮิสโตแกรมจะแสดงแท่งข้อมูลที่เกือบเท่ากันสำหรับค่าส่วนใหญ่
สมมติว่าageของมนุษย์เป็นฟีเจอร์ การปรับขนาดเชิงเส้นเป็นเทคนิคการทําให้เป็นมาตรฐานที่ดีสําหรับ age เนื่องจาก
- ขอบเขตล่างและบนโดยประมาณคือ 0 ถึง 100
ageมีค่าผิดปกติในสัดส่วนที่ค่อนข้างน้อย มีประชากรเพียงประมาณ 0.3% เท่านั้นที่มีอายุมากกว่า 100 ปี- แม้ว่าอายุบางช่วงจะได้รับการแสดงอย่างเหมาะสมมากกว่าช่วงอื่นๆ แต่ชุดข้อมูลขนาดใหญ่ควรมีตัวอย่างของทุกช่วงอายุอย่างเพียงพอ
แบบฝึกหัด: ทดสอบความเข้าใจ
สมมติว่าโมเดลของคุณมีฟีเจอร์ชื่อnet_worth ซึ่งมีมูลค่าสุทธิของบุคคลต่างๆ การปรับขนาดเชิงเส้นเป็นเทคนิคการทำให้เป็นปกติที่ดีสำหรับ net_worth ไหม เพราะเหตุใด
การปรับขนาดคะแนนมาตรฐาน (Z-Score)
คะแนน Z คือจำนวนค่าเบี่ยงเบนมาตรฐานที่ค่าหนึ่งๆ อยู่ห่างจากค่าเฉลี่ย เช่น ค่าที่มากกว่าค่าเฉลี่ย 2 ส่วนเบี่ยงเบนมาตรฐาน จะมีคะแนน Z เท่ากับ +2.0 ค่าที่น้อยกว่าค่าเฉลี่ย 1.5 ส่วนเบี่ยงเบนมาตรฐานจะมีคะแนน Z เท่ากับ -1.5
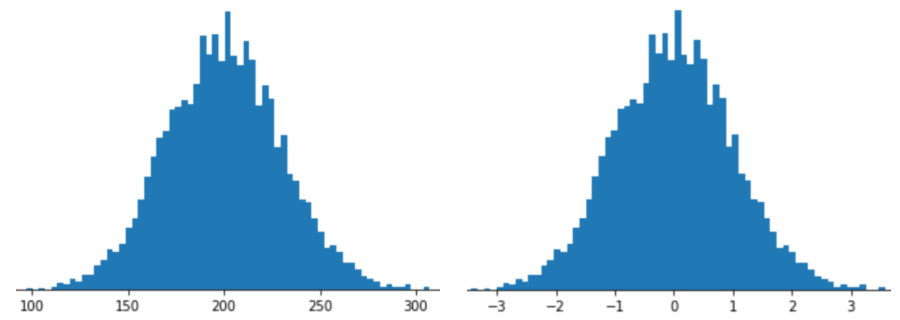
การแสดงฟีเจอร์ด้วยการปรับขนาด Z-score หมายถึงการจัดเก็บ Z-score ของฟีเจอร์นั้นในเวกเตอร์ฟีเจอร์ ตัวอย่างเช่น รูปที่ต่อไปนี้แสดงฮิสโทแกรม 2 รายการ
- ทางด้านซ้ายคือการกระจายปกติแบบคลาสสิก
- ทางด้านขวาคือการกระจายเดียวกันที่ปรับให้เป็นมาตรฐานโดยการปรับขนาด Z-score
การปรับขนาด Z-score ยังเป็นตัวเลือกที่ดีสำหรับข้อมูลเช่นที่แสดงใน รูปต่อไปนี้ ซึ่งมีการกระจายแบบปกติเพียงเล็กน้อย
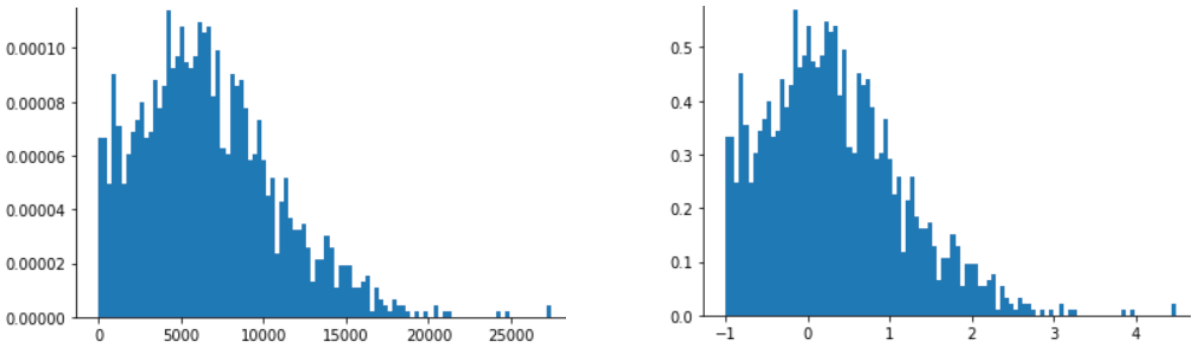
คะแนน Z เป็นตัวเลือกที่ดีเมื่อข้อมูลมีการกระจายตามปกติหรือ การกระจายที่คล้ายกับการกระจายตามปกติ
โปรดทราบว่าการกระจายบางอย่างอาจเป็นเรื่องปกติภายในช่วงส่วนใหญ่ แต่ก็ยังคงมีค่าผิดปกติที่มากเกินไป ตัวอย่างเช่น จุดเกือบทั้งหมดในnet_worthฟีเจอร์อาจอยู่ในช่วงการเบี่ยงเบนมาตรฐาน 3 รายการ
แต่ตัวอย่างบางส่วนของฟีเจอร์นี้อาจอยู่ห่างจากค่าเฉลี่ยหลายร้อยการเบี่ยงเบนมาตรฐาน
ในกรณีเหล่านี้ คุณสามารถใช้การปรับขนาดคะแนนมาตรฐานร่วมกับ
การปรับค่าปกติรูปแบบอื่น (โดยปกติคือการตัด) เพื่อจัดการกับสถานการณ์นี้
แบบฝึกหัด: ทดสอบความเข้าใจ
สมมติว่าโมเดลของคุณฝึกกับฟีเจอร์ชื่อheight ซึ่งมีส่วนสูงของผู้หญิงที่เป็นผู้ใหญ่ 10 ล้านคน
การปรับขนาดคะแนนมาตรฐาน (Z-Score) เป็นเทคนิคการทําให้เป็นปกติที่ดีสําหรับ height ไหม เพราะเหตุใด
การปรับขนาดบันทึก
การปรับขนาดแบบลอการิทึมจะคำนวณลอการิทึมของค่าดิบ ในทางทฤษฎี ลอการิทึมอาจมีฐานใดก็ได้ แต่ในทางปฏิบัติ การปรับขนาดบันทึกมักจะคำนวณ ลอการิทึมธรรมชาติ (ln)
การปรับขนาดแบบลอการิทึมมีประโยชน์เมื่อข้อมูลเป็นไปตามการกระจายกฎกำลัง การแจกแจงกฎกำลังอย่างคร่าวๆ มีลักษณะดังนี้
- ค่า
Xต่ำจะมีค่าYสูงมาก - เมื่อค่าของ
Xเพิ่มขึ้น ค่าของYจะลดลงอย่างรวดเร็ว ดังนั้น ค่าXที่สูงจึงมีค่าYต่ำมาก
การจัดประเภทภาพยนตร์เป็นตัวอย่างที่ดีของการกระจายแบบกฎกำลัง ในรูปภาพต่อไปนี้ ให้สังเกตสิ่งต่อไปนี้
- ภาพยนตร์บางเรื่องมีคะแนนจากผู้ใช้จำนวนมาก (ค่า
Xต่ำจะมีค่าYสูง) - ภาพยนตร์ส่วนใหญ่มีคะแนนจากผู้ใช้น้อยมาก (ค่า
Xสูงจะมีค่าYต่ำ)
การปรับขนาดบันทึกจะเปลี่ยนการกระจาย ซึ่งช่วยฝึกโมเดลที่จะ ทำการคาดการณ์ได้ดีขึ้น

ตัวอย่างที่ 2 ยอดขายหนังสือเป็นไปตามการกระจายแบบกฎกำลังเนื่องจาก
- หนังสือที่ตีพิมพ์ส่วนใหญ่ขายได้เพียงไม่กี่เล่ม อาจจะ 100 หรือ 200 เล่ม
- หนังสือบางเล่มขายได้ในระดับปานกลาง ซึ่งก็คือหลักพัน
- มีเพียงหนังสือขายดีไม่กี่เล่มเท่านั้นที่จะขายได้มากกว่า 1 ล้านเล่ม
สมมติว่าคุณกำลังฝึกโมเดลเชิงเส้นเพื่อหาความสัมพันธ์ ของปกหนังสือกับการขายหนังสือ การฝึกโมเดลเชิงเส้นบนค่าดิบจะต้องค้นหาบางอย่างเกี่ยวกับปกหนังสือที่ขายได้ 1 ล้านเล่ม ซึ่งมีประสิทธิภาพมากกว่าปกหนังสือที่ขายได้เพียง 100 เล่มถึง 10,000 เท่า อย่างไรก็ตาม การปรับขนาดบันทึกตัวเลขยอดขายทั้งหมดจะทำให้งานนี้เป็นไปได้มากขึ้น ตัวอย่างเช่น ล็อกของ 100 คือ
~4.6 = ln(100)
ในขณะที่บันทึกของ 1,000,000 คือ
~13.8 = ln(1,000,000)
ดังนั้น ล็อกของ 1,000,000 จึงใหญ่กว่าล็อกของ 100 เพียงประมาณ 3 เท่า คุณคงนึกภาพออกว่าปกหนังสือขายดีมีประสิทธิภาพมากกว่าปกหนังสือที่ขายได้น้อยประมาณ 3 เท่า (ในบางแง่มุม)
การตัด
การตัดค่าสุดโต่งเป็นเทคนิคในการ ลดอิทธิพลของค่าผิดปกติที่อยู่นอกช่วง กล่าวโดยย่อ การตัดมักจะจำกัด (ลด) ค่าของค่าผิดปกติให้เป็นค่าสูงสุดที่เฉพาะเจาะจง การตัดเป็นไอเดียที่ แปลก แต่ก็มีประสิทธิภาพมาก
ตัวอย่างเช่น ลองนึกถึงชุดข้อมูลที่มีฟีเจอร์ชื่อ roomsPerPerson
ซึ่งแสดงถึงจำนวนห้อง (จำนวนห้องทั้งหมดหารด้วย
จำนวนผู้เข้าพัก) สำหรับบ้านต่างๆ พล็อตต่อไปนี้แสดงให้เห็นว่าค่าฟีเจอร์มากกว่า 99% เป็นไปตามการแจกแจงปกติ (โดยประมาณ ค่าเฉลี่ยเท่ากับ 1.8 และส่วนเบี่ยงเบนมาตรฐานเท่ากับ 0.7) อย่างไรก็ตาม ฟีเจอร์นี้มี
ค่าผิดปกติอยู่บ้าง ซึ่งบางค่าก็เป็นค่าผิดปกติที่รุนแรง
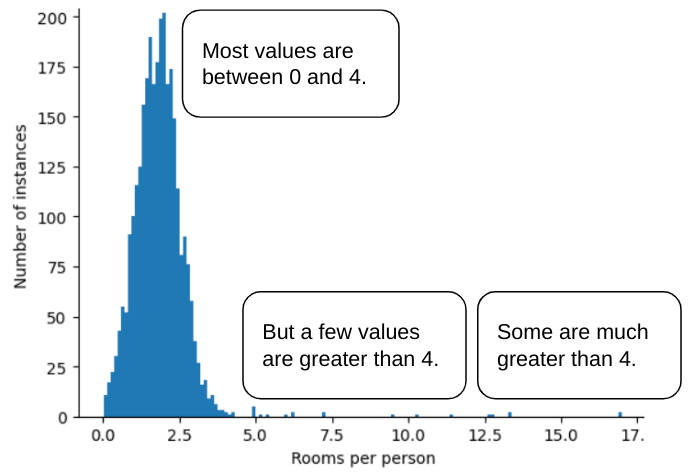
คุณจะลดอิทธิพลของค่าผิดปกติที่มากเกินไปเหล่านั้นได้อย่างไร ฮิสโทแกรมไม่ใช่การกระจายที่สม่ำเสมอ การกระจายปกติ หรือการกระจายกฎกำลัง
จะเกิดอะไรขึ้นหากคุณเพียงแค่จำกัดหรือตัดค่าสูงสุดของ
roomsPerPersonที่ค่าใดก็ได้ เช่น 4.0
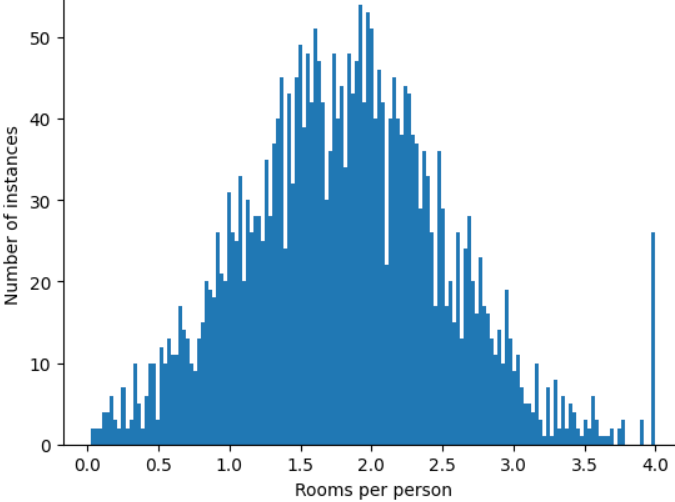
การตัดค่าฟีเจอร์ที่ 4.0 ไม่ได้หมายความว่าโมเดลจะละเว้นค่าทั้งหมดที่มากกว่า 4.0 แต่หมายความว่าค่าทั้งหมดที่มากกว่า 4.0 จะกลายเป็น 4.0 ซึ่งอธิบายถึงเนินเขาที่แปลกประหลาดที่ 4.0 แม้ว่า จะมีอุปสรรค แต่ตอนนี้ชุดฟีเจอร์ที่ปรับขนาดแล้วก็มีประโยชน์มากกว่าข้อมูลเดิม
โปรดรอสักครู่ คุณลดค่าผิดปกติทุกค่าให้เป็นขีดจำกัดบนที่กำหนดเองได้จริงหรือ ใช่ เมื่อฝึกโมเดล
นอกจากนี้ คุณยังตัดค่าหลังจากใช้การปรับรูปแบบอื่นๆ ได้ด้วย ตัวอย่างเช่น สมมติว่าคุณใช้การปรับขนาดคะแนนมาตรฐาน แต่ค่าผิดปกติบางค่ามี ค่าสัมบูรณ์มากกว่า 3 มาก ในกรณีนี้ คุณสามารถทำสิ่งต่อไปนี้ได้
- คลิปที่มี Z-score มากกว่า 3 จะกลายเป็น 3
- คลิปคะแนน Z น้อยกว่า -3 จะกลายเป็น -3
การตัดค่าจะป้องกันไม่ให้โมเดลของคุณจัดทำดัชนีข้อมูลที่ไม่สำคัญมากเกินไป อย่างไรก็ตาม ค่าผิดปกติบางค่าอาจมีความสำคัญ ดังนั้นให้ตัดค่าอย่างระมัดระวัง
สรุปเทคนิคการปรับให้เป็นมาตรฐาน
| เทคนิคการแปลงเป็นรูปแบบมาตรฐาน | สูตร | กรณีที่ควรใช้ |
|---|---|---|
| การปรับสเกลเชิงเส้น | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | เมื่อฟีเจอร์นี้กระจายอย่างสม่ำเสมอในขอบเขต แบน |
| การปรับขนาดคะแนนมาตรฐาน (Z-Score) | $$ x' = \frac{x - μ}{σ}$$ | เมื่อฟีเจอร์มีการกระจายแบบปกติ (จุดสูงสุดอยู่ใกล้ค่าเฉลี่ย) รูปกระดิ่ง |
| การปรับขนาดบันทึก | $$ x' = log(x)$$ | เมื่อการกระจายฟีเจอร์มีความเบ้สูงในด้านใดด้านหนึ่งของหาง หนักรูปหาง |
| การตัด | หาก $x > max$ ให้ตั้งค่า $x' = max$ หาก $x < min$ ให้ตั้งค่า $x' = min$ |
เมื่อฟีเจอร์มีค่าผิดปกติที่มากเกินไป |
แบบฝึกหัด: ทดสอบความรู้

สมมติว่าคุณกำลังพัฒนาโมเดลที่คาดการณ์ประสิทธิภาพของศูนย์ข้อมูล
โดยอิงตามอุณหภูมิที่วัดได้ภายในศูนย์ข้อมูล
ค่า temperature เกือบทั้งหมดในชุดข้อมูลอยู่ระหว่าง 15 ถึง 30 (องศาเซลเซียส) โดยมีข้อยกเว้นดังนี้
- ปีละ 1-2 ครั้ง ในวันที่อากาศร้อนจัด ระบบจะบันทึกค่าระหว่าง 31 ถึง 45 ใน
temperature - ทุกๆ จุดที่ 1,000 ใน
temperatureจะตั้งค่าเป็น 1,000 แทนที่จะเป็นอุณหภูมิจริง
เทคนิคการทำให้เป็นมาตรฐานที่สมเหตุสมผลสำหรับ
temperature คืออะไร
ค่า 1,000 เป็นค่าที่ไม่ถูกต้อง และควรลบออกแทนที่จะ ตัด
ค่าระหว่าง 31 ถึง 45 เป็นจุดข้อมูลที่ถูกต้อง การตัดค่าเหล่านี้อาจเป็นความคิดที่ดี สมมติว่าชุดข้อมูลมีตัวอย่างในช่วงอุณหภูมินี้ไม่เพียงพอที่จะฝึกโมเดลให้คาดการณ์ได้ดี อย่างไรก็ตาม ในระหว่างการอนุมาน โปรดทราบว่าโมเดลที่ตัดแล้วจะคาดการณ์อุณหภูมิ 45 เหมือนกับอุณหภูมิ 35